 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComplementing reinforcement learning with SFT through logit averaging in the post training of LLMs
May 19, 2026We introduce a novel method that averages the logits of a frozen reference policy (e.g., SFT) and a trainable policy, and incorporate the method into Group Relative Policy Optimization (GRPO). In contrast to Reinforcement Learning with Verifiable Rewards (RLVR) methods, our proposal does not involve a Kullback Leibler (KL) regularization or critic; the trainable policy and the reference anchor are coupled through the logit averaging structure to leverage the reasoning expertise of the trainable policy while maintaining the formatting advantage of SFT. Our method is evaluated on MATH, cn-k12, and MMLU, and the results show a higher accuracy or at least comparable accuracy relative to the canonical KL-regularized GRPO.
Predicting Tennis Serve directions with Machine Learning
Feb 26, 2026Serves, especially first serves, are very important in professional tennis. Servers choose their serve directions strategically to maximize their winning chances while trying to be unpredictable. On the other hand, returners try to predict serve directions to make good returns. The mind game between servers and returners is an important part of decision-making in professional tennis matches. To help understand the players' serve decisions, we have developed a machine learning method for predicting professional tennis players' first serve directions. Through feature engineering, our method achieves an average prediction accuracy of around 49\% for male players and 44\% for female players. Our analysis provides some evidence that top professional players use a mixed-strategy model in serving decisions and that fatigue might be a factor in choosing serve directions. Our analysis also suggests that contextual information is perhaps more important for returners' anticipatory reactions than previously thought.
MOVA: Towards Scalable and Synchronized Video-Audio Generation
Feb 09, 2026Audio is indispensable for real-world video, yet generation models have largely overlooked audio components. Current approaches to producing audio-visual content often rely on cascaded pipelines, which increase cost, accumulate errors, and degrade overall quality. While systems such as Veo 3 and Sora 2 emphasize the value of simultaneous generation, joint multimodal modeling introduces unique challenges in architecture, data, and training. Moreover, the closed-source nature of existing systems limits progress in the field. In this work, we introduce MOVA (MOSS Video and Audio), an open-source model capable of generating high-quality, synchronized audio-visual content, including realistic lip-synced speech, environment-aware sound effects, and content-aligned music. MOVA employs a Mixture-of-Experts (MoE) architecture, with a total of 32B parameters, of which 18B are active during inference. It supports IT2VA (Image-Text to Video-Audio) generation task. By releasing the model weights and code, we aim to advance research and foster a vibrant community of creators. The released codebase features comprehensive support for efficient inference, LoRA fine-tuning, and prompt enhancement.
FourierSampler: Unlocking Non-Autoregressive Potential in Diffusion Language Models via Frequency-Guided Generation
Jan 30, 2026Despite the non-autoregressive potential of diffusion language models (dLLMs), existing decoding strategies demonstrate positional bias, failing to fully unlock the potential of arbitrary generation. In this work, we delve into the inherent spectral characteristics of dLLMs and present the first frequency-domain analysis showing that low-frequency components in hidden states primarily encode global structural information and long-range dependencies, while high-frequency components are responsible for characterizing local details. Based on this observation, we propose FourierSampler, which leverages a frequency-domain sliding window mechanism to dynamically guide the model to achieve a "structure-to-detail" generation. FourierSampler outperforms other inference enhancement strategies on LLADA and SDAR, achieving relative improvements of 20.4% on LLaDA1.5-8B and 16.0% on LLaDA-8B-Instruct. It notably surpasses similarly sized autoregressive models like Llama3.1-8B-Instruct.
DiRL: An Efficient Post-Training Framework for Diffusion Language Models
Dec 23, 2025Diffusion Language Models (dLLMs) have emerged as promising alternatives to Auto-Regressive (AR) models. While recent efforts have validated their pre-training potential and accelerated inference speeds, the post-training landscape for dLLMs remains underdeveloped. Existing methods suffer from computational inefficiency and objective mismatches between training and inference, severely limiting performance on complex reasoning tasks such as mathematics. To address this, we introduce DiRL, an efficient post-training framework that tightly integrates FlexAttention-accelerated blockwise training with LMDeploy-optimized inference. This architecture enables a streamlined online model update loop, facilitating efficient two-stage post-training (Supervised Fine-Tuning followed by Reinforcement Learning). Building on this framework, we propose DiPO, the first unbiased Group Relative Policy Optimization (GRPO) implementation tailored for dLLMs. We validate our approach by training DiRL-8B-Instruct on high-quality math data. Our model achieves state-of-the-art math performance among dLLMs and surpasses comparable models in the Qwen2.5 series on several benchmarks.
RISE: Reasoning Enhancement via Iterative Self-Exploration in Multi-hop Question Answering
May 28, 2025Large Language Models (LLMs) excel in many areas but continue to face challenges with complex reasoning tasks, such as Multi-Hop Question Answering (MHQA). MHQA requires integrating evidence from diverse sources while managing intricate logical dependencies, often leads to errors in reasoning. Retrieval-Augmented Generation (RAG), widely employed in MHQA tasks, faces challenges in effectively filtering noisy data and retrieving all necessary evidence, thereby limiting its effectiveness in addressing MHQA challenges. To address these challenges, we propose RISE:Reasoning Enhancement via Iterative Self-Exploration, a novel framework designed to enhance models' reasoning capability through iterative self-exploration. Specifically, RISE involves three key steps in addressing MHQA tasks: question decomposition, retrieve-then-read, and self-critique. By leveraging continuous self-exploration, RISE identifies accurate reasoning paths, iteratively self-improving the model's capability to integrate evidence, maintain logical consistency, and enhance performance in MHQA tasks. Extensive experiments on multiple MHQA benchmarks demonstrate that RISE significantly improves reasoning accuracy and task performance.
Swarm Intelligence Enhanced Reasoning: A Density-Driven Framework for LLM-Based Multi-Agent Optimization
May 21, 2025Recently, many approaches, such as Chain-of-Thought (CoT) prompting and Multi-Agent Debate (MAD), have been proposed to further enrich Large Language Models' (LLMs) complex problem-solving capacities in reasoning scenarios. However, these methods may fail to solve complex problems due to the lack of ability to find optimal solutions. Swarm Intelligence has been serving as a powerful tool for finding optima in the field of traditional optimization problems. To this end, we propose integrating swarm intelligence into the reasoning process by introducing a novel Agent-based Swarm Intelligence (ASI) paradigm. In this paradigm, we formulate LLM reasoning as an optimization problem and use a swarm intelligence scheme to guide a group of LLM-based agents in collaboratively searching for optimal solutions. To avoid swarm intelligence getting trapped in local optima, we further develop a Swarm Intelligence Enhancing Reasoning (SIER) framework, which develops a density-driven strategy to enhance the reasoning ability. To be specific, we propose to perform kernel density estimation and non-dominated sorting to optimize both solution quality and diversity simultaneously. In this case, SIER efficiently enhances solution space exploration through expanding the diversity of the reasoning path. Besides, a step-level quality evaluation is used to help agents improve solution quality by correcting low-quality intermediate steps. Then, we use quality thresholds to dynamically control the termination of exploration and the selection of candidate steps, enabling a more flexible and efficient reasoning process. Extensive experiments are ...
ReAgent: Reversible Multi-Agent Reasoning for Knowledge-Enhanced Multi-Hop QA
Mar 10, 2025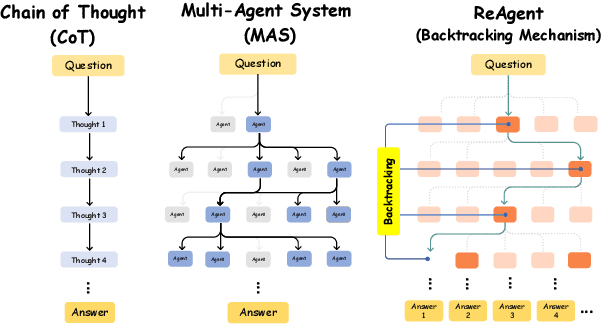
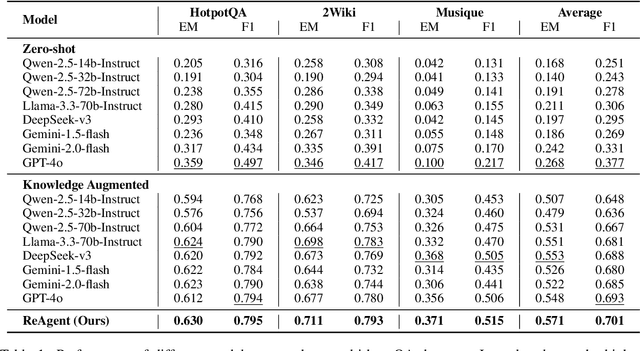
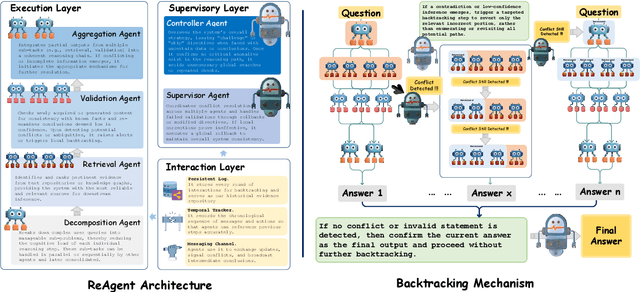
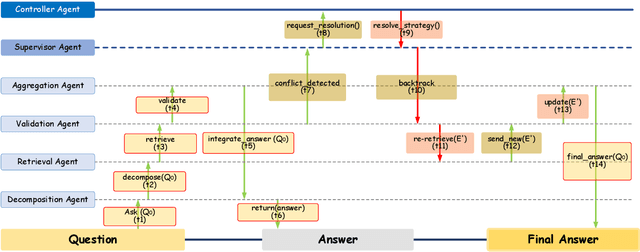
Recent advances in large language models (LLMs) have significantly improved multi-hop question answering (QA) through direct Chain-of-Thought (CoT) reasoning. However, the irreversible nature of CoT leads to error accumulation, making it challenging to correct mistakes in multi-hop reasoning. This paper introduces ReAgent: a Reversible multi-Agent collaborative framework augmented with explicit backtracking mechanisms, enabling reversible multi-hop reasoning. By incorporating text-based retrieval, information aggregation and validation, our system can detect and correct errors mid-reasoning, leading to more robust and interpretable QA outcomes. The framework and experiments serve as a foundation for future work on error-tolerant QA systems. Empirical evaluations across three benchmarks indicate ReAgent's efficacy, yielding average about 6\% improvements against baseline models.
Narrative-Driven Travel Planning: Geoculturally-Grounded Script Generation with Evolutionary Itinerary Optimization
Feb 20, 2025



To enhance tourists' experiences and immersion, this paper proposes a narrative-driven travel planning framework called NarrativeGuide, which generates a geoculturally-grounded narrative script for travelers, offering a novel, role-playing experience for their journey. In the initial stage, NarrativeGuide constructs a knowledge graph for attractions within a city, then configures the worldview, character setting, and exposition based on the knowledge graph. Using this foundation, the knowledge graph is combined to generate an independent scene unit for each attraction. During the itinerary planning stage, NarrativeGuide models narrative-driven travel planning as an optimization problem, utilizing a genetic algorithm (GA) to refine the itinerary. Before evaluating the candidate itinerary, transition scripts are generated for each pair of adjacent attractions, which, along with the scene units, form a complete script. The weighted sum of script coherence, travel time, and attraction scores is then used as the fitness value to update the candidate solution set. Experimental results across four cities, i.e., Nanjing and Yangzhou in China, Paris in France, and Berlin in Germany, demonstrate significant improvements in narrative coherence and cultural fit, alongside a notable reduction in travel time and an increase in the quality of visited attractions. Our study highlights that incorporating external evolutionary optimization effectively addresses the limitations of large language models in travel planning.Our codes are available at https://github.com/Evan01225/Narrative-Driven-Travel-Planning.
D$^3$epth: Self-Supervised Depth Estimation with Dynamic Mask in Dynamic Scenes
Nov 07, 2024



Depth estimation is a crucial technology in robotics. Recently, self-supervised depth estimation methods have demonstrated great potential as they can efficiently leverage large amounts of unlabelled real-world data. However, most existing methods are designed under the assumption of static scenes, which hinders their adaptability in dynamic environments. To address this issue, we present D$^3$epth, a novel method for self-supervised depth estimation in dynamic scenes. It tackles the challenge of dynamic objects from two key perspectives. First, within the self-supervised framework, we design a reprojection constraint to identify regions likely to contain dynamic objects, allowing the construction of a dynamic mask that mitigates their impact at the loss level. Second, for multi-frame depth estimation, we introduce a cost volume auto-masking strategy that leverages adjacent frames to identify regions associated with dynamic objects and generate corresponding masks. This provides guidance for subsequent processes. Furthermore, we propose a spectral entropy uncertainty module that incorporates spectral entropy to guide uncertainty estimation during depth fusion, effectively addressing issues arising from cost volume computation in dynamic environments. Extensive experiments on KITTI and Cityscapes datasets demonstrate that the proposed method consistently outperforms existing self-supervised monocular depth estimation baselines. Code is available at \url{https://github.com/Csyunling/D3epth}.