 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpecializing Large Models for Oracle Bone Script Interpretation via Component-Grounded Multimodal Knowledge Augmentation
Apr 08, 2026Deciphering ancient Chinese Oracle Bone Script (OBS) is a challenging task that offers insights into the beliefs, systems, and culture of the ancient era. Existing approaches treat decipherment as a closed-set image recognition problem, which fails to bridge the ``interpretation gap'': while individual characters are often unique and rare, they are composed of a limited set of recurring, pictographic components that carry transferable semantic meanings. To leverage this structural logic, we propose an agent-driven Vision-Language Model (VLM) framework that integrates a VLM for precise visual grounding with an LLM-based agent to automate a reasoning chain of component identification, graph-based knowledge retrieval, and relationship inference for linguistically accurate interpretation. To support this, we also introduce OB-Radix, an expert-annotated dataset providing structural and semantic data absent from prior corpora, comprising 1,022 character images (934 unique characters) and 1,853 fine-grained component images across 478 distinct components with verified explanations. By evaluating our system across three benchmarks of different tasks, we demonstrate that our framework yields more detailed and precise decipherments compared to baseline methods.
See2Refine: Vision-Language Feedback Improves LLM-Based eHMI Action Designers
Feb 02, 2026Automated vehicles lack natural communication channels with other road users, making external Human-Machine Interfaces (eHMIs) essential for conveying intent and maintaining trust in shared environments. However, most eHMI studies rely on developer-crafted message-action pairs, which are difficult to adapt to diverse and dynamic traffic contexts. A promising alternative is to use Large Language Models (LLMs) as action designers that generate context-conditioned eHMI actions, yet such designers lack perceptual verification and typically depend on fixed prompts or costly human-annotated feedback for improvement. We present See2Refine, a human-free, closed-loop framework that uses vision-language model (VLM) perceptual evaluation as automated visual feedback to improve an LLM-based eHMI action designer. Given a driving context and a candidate eHMI action, the VLM evaluates the perceived appropriateness of the action, and this feedback is used to iteratively revise the designer's outputs, enabling systematic refinement without human supervision. We evaluate our framework across three eHMI modalities (lightbar, eyes, and arm) and multiple LLM model sizes. Across settings, our framework consistently outperforms prompt-only LLM designers and manually specified baselines in both VLM-based metrics and human-subject evaluations. Results further indicate that the improvements generalize across modalities and that VLM evaluations are well aligned with human preferences, supporting the robustness and effectiveness of See2Refine for scalable action design.
Med-CoReasoner: Reducing Language Disparities in Medical Reasoning via Language-Informed Co-Reasoning
Jan 13, 2026While reasoning-enhanced large language models perform strongly on English medical tasks, a persistent multilingual gap remains, with substantially weaker reasoning in local languages, limiting equitable global medical deployment. To bridge this gap, we introduce Med-CoReasoner, a language-informed co-reasoning framework that elicits parallel English and local-language reasoning, abstracts them into structured concepts, and integrates local clinical knowledge into an English logical scaffold via concept-level alignment and retrieval. This design combines the structural robustness of English reasoning with the practice-grounded expertise encoded in local languages. To evaluate multilingual medical reasoning beyond multiple-choice settings, we construct MultiMed-X, a benchmark covering seven languages with expert-annotated long-form question answering and natural language inference tasks, comprising 350 instances per language. Experiments across three benchmarks show that Med-CoReasoner improves multilingual reasoning performance by an average of 5%, with particularly substantial gains in low-resource languages. Moreover, model distillation and expert evaluation analysis further confirm that Med-CoReasoner produces clinically sound and culturally grounded reasoning traces.
ColorGPT: Leveraging Large Language Models for Multimodal Color Recommendation
Aug 12, 2025Colors play a crucial role in the design of vector graphic documents by enhancing visual appeal, facilitating communication, improving usability, and ensuring accessibility. In this context, color recommendation involves suggesting appropriate colors to complete or refine a design when one or more colors are missing or require alteration. Traditional methods often struggled with these challenges due to the complex nature of color design and the limited data availability. In this study, we explored the use of pretrained Large Language Models (LLMs) and their commonsense reasoning capabilities for color recommendation, raising the question: Can pretrained LLMs serve as superior designers for color recommendation tasks? To investigate this, we developed a robust, rigorously validated pipeline, ColorGPT, that was built by systematically testing multiple color representations and applying effective prompt engineering techniques. Our approach primarily targeted color palette completion by recommending colors based on a set of given colors and accompanying context. Moreover, our method can be extended to full palette generation, producing an entire color palette corresponding to a provided textual description. Experimental results demonstrated that our LLM-based pipeline outperformed existing methods in terms of color suggestion accuracy and the distribution of colors in the color palette completion task. For the full palette generation task, our approach also yielded improvements in color diversity and similarity compared to current techniques.
Automating eHMI Action Design with LLMs for Automated Vehicle Communication
May 27, 2025



The absence of explicit communication channels between automated vehicles (AVs) and other road users requires the use of external Human-Machine Interfaces (eHMIs) to convey messages effectively in uncertain scenarios. Currently, most eHMI studies employ predefined text messages and manually designed actions to perform these messages, which limits the real-world deployment of eHMIs, where adaptability in dynamic scenarios is essential. Given the generalizability and versatility of large language models (LLMs), they could potentially serve as automated action designers for the message-action design task. To validate this idea, we make three contributions: (1) We propose a pipeline that integrates LLMs and 3D renderers, using LLMs as action designers to generate executable actions for controlling eHMIs and rendering action clips. (2) We collect a user-rated Action-Design Scoring dataset comprising a total of 320 action sequences for eight intended messages and four representative eHMI modalities. The dataset validates that LLMs can translate intended messages into actions close to a human level, particularly for reasoning-enabled LLMs. (3) We introduce two automated raters, Action Reference Score (ARS) and Vision-Language Models (VLMs), to benchmark 18 LLMs, finding that the VLM aligns with human preferences yet varies across eHMI modalities.
Hybrid Learning: A Novel Combination of Self-Supervised and Supervised Learning for MRI Reconstruction without High-Quality Training Reference
May 09, 2025Purpose: Deep learning has demonstrated strong potential for MRI reconstruction, but conventional supervised learning methods require high-quality reference images, which are often unavailable in practice. Self-supervised learning offers an alternative, yet its performance degrades at high acceleration rates. To overcome these limitations, we propose hybrid learning, a novel two-stage training framework that combines self-supervised and supervised learning for robust image reconstruction. Methods: Hybrid learning is implemented in two sequential stages. In the first stage, self-supervised learning is employed to generate improved images from noisy or undersampled reference data. These enhanced images then serve as pseudo-ground truths for the second stage, which uses supervised learning to refine reconstruction performance and support higher acceleration rates. We evaluated hybrid learning in two representative applications: (1) accelerated 0.55T spiral-UTE lung MRI using noisy reference data, and (2) 3D T1 mapping of the brain without access to fully sampled ground truth. Results: For spiral-UTE lung MRI, hybrid learning consistently improved image quality over both self-supervised and conventional supervised methods across different acceleration rates, as measured by SSIM and NMSE. For 3D T1 mapping, hybrid learning achieved superior T1 quantification accuracy across a wide dynamic range, outperforming self-supervised learning in all tested conditions. Conclusions: Hybrid learning provides a practical and effective solution for training deep MRI reconstruction networks when only low-quality or incomplete reference data are available. It enables improved image quality and accurate quantitative mapping across different applications and field strengths, representing a promising technique toward broader clinical deployment of deep learning-based MRI.
HealthGenie: Empowering Users with Healthy Dietary Guidance through Knowledge Graph and Large Language Models
Apr 20, 2025Seeking dietary guidance often requires navigating complex professional knowledge while accommodating individual health conditions. Knowledge Graphs (KGs) offer structured and interpretable nutritional information, whereas Large Language Models (LLMs) naturally facilitate conversational recommendation delivery. In this paper, we present HealthGenie, an interactive system that combines the strengths of LLMs and KGs to provide personalized dietary recommendations along with hierarchical information visualization for a quick and intuitive overview. Upon receiving a user query, HealthGenie performs query refinement and retrieves relevant information from a pre-built KG. The system then visualizes and highlights pertinent information, organized by defined categories, while offering detailed, explainable recommendation rationales. Users can further tailor these recommendations by adjusting preferences interactively. Our evaluation, comprising a within-subject comparative experiment and an open-ended discussion, demonstrates that HealthGenie effectively supports users in obtaining personalized dietary guidance based on their health conditions while reducing interaction effort and cognitive load. These findings highlight the potential of LLM-KG integration in supporting decision-making through explainable and visualized information. We examine the system's usefulness and effectiveness with an N=12 within-subject study and provide design considerations for future systems that integrate conversational LLM and KG.
PairingNet: A Learning-based Pair-searching and -matching Network for Image Fragments
Dec 14, 2023In this paper, we propose a learning-based image fragment pair-searching and -matching approach to solve the challenging restoration problem. Existing works use rule-based methods to match similar contour shapes or textures, which are always difficult to tune hyperparameters for extensive data and computationally time-consuming. Therefore, we propose a neural network that can effectively utilize neighbor textures with contour shape information to fundamentally improve performance. First, we employ a graph-based network to extract the local contour and texture features of fragments. Then, for the pair-searching task, we adopt a linear transformer-based module to integrate these local features and use contrastive loss to encode the global features of each fragment. For the pair-matching task, we design a weighted fusion module to dynamically fuse extracted local contour and texture features, and formulate a similarity matrix for each pair of fragments to calculate the matching score and infer the adjacent segment of contours. To faithfully evaluate our proposed network, we created a new image fragment dataset through an algorithm we designed that tears complete images into irregular fragments. The experimental results show that our proposed network achieves excellent pair-searching accuracy, reduces matching errors, and significantly reduces computational time. Details, sourcecode, and data are available in our supplementary material.
SpaceEditing: Integrating Human Knowledge into Deep Neural Networks via Interactive Latent Space Editing
Dec 08, 2022



We propose an interactive editing method that allows humans to help deep neural networks (DNNs) learn a latent space more consistent with human knowledge, thereby improving classification accuracy on indistinguishable ambiguous data. Firstly, we visualize high-dimensional data features through dimensionality reduction methods and design an interactive system \textit{SpaceEditing} to display the visualized data. \textit{SpaceEditing} provides a 2D workspace based on the idea of spatial layout. In this workspace, the user can move the projection data in it according to the system guidance. Then, \textit{SpaceEditing} will find the corresponding high-dimensional features according to the projection data moved by the user, and feed the high-dimensional features back to the network for retraining, therefore achieving the purpose of interactively modifying the high-dimensional latent space for the user. Secondly, to more rationally incorporate human knowledge into the training process of neural networks, we design a new loss function that enables the network to learn user-modified information. Finally, We demonstrate how \textit{SpaceEditing} meets user needs through three case studies while evaluating our proposed new method, and the results confirm the effectiveness of our method.
Surface-based 3D Deep Learning Framework for Segmentation of Intracranial Aneurysms from TOF-MRA Images
Jun 29, 2020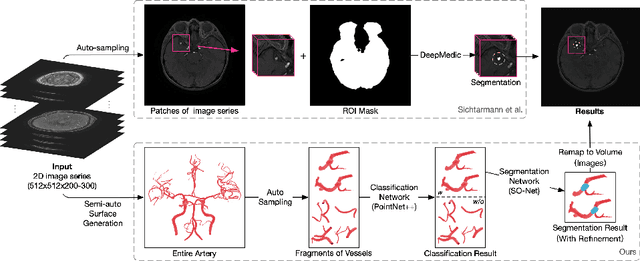
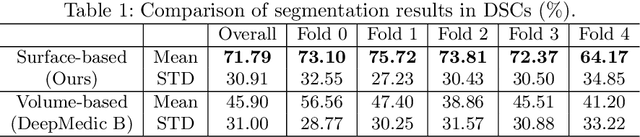
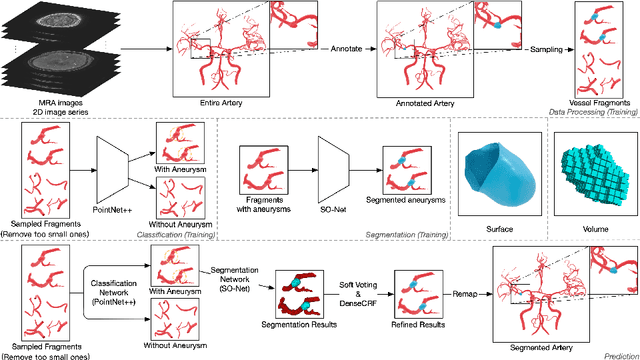
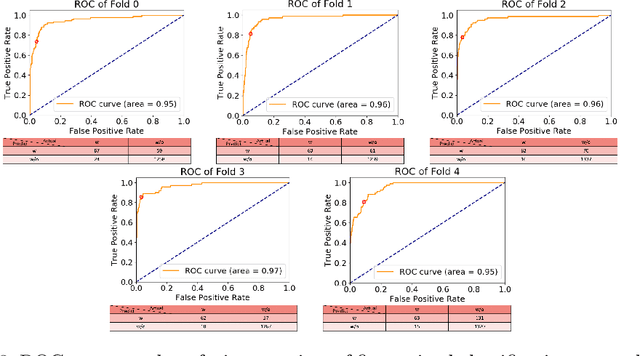
Segmentation of intracranial aneurysms is an important task in medical diagnosis and surgical planning. Volume-based deep learning frameworks have been proposed for this task; however, they are not effective. In this study, we propose a surface-based deep learning framework that achieves higher performance by leveraging human intervention. First, the user semi-automatically generates a surface representation of the principal brain arteries model from time-of-flight magnetic resonance angiography images. The system then samples 3D vessel surface fragments from the entire brain artery model and classifies the surface fragments into those with and without aneurysms using the point-based deep learning network (PointNet++). Next, the system applies surface segmentation (SO-Net) to the surface fragments containing aneurysms. We conduct a head-to-head comparison of segmentation performance by counting voxels between the proposed surface-based framework and existing pixel-based framework, and our framework achieved a much higher dice similarity coefficient score (72%) than the existing one (46%).