 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeakly-supervised Audio Temporal Forgery Localization via Progressive Audio-language Co-learning Network
May 03, 2025Audio temporal forgery localization (ATFL) aims to find the precise forgery regions of the partial spoof audio that is purposefully modified. Existing ATFL methods rely on training efficient networks using fine-grained annotations, which are obtained costly and challenging in real-world scenarios. To meet this challenge, in this paper, we propose a progressive audio-language co-learning network (LOCO) that adopts co-learning and self-supervision manners to prompt localization performance under weak supervision scenarios. Specifically, an audio-language co-learning module is first designed to capture forgery consensus features by aligning semantics from temporal and global perspectives. In this module, forgery-aware prompts are constructed by using utterance-level annotations together with learnable prompts, which can incorporate semantic priors into temporal content features dynamically. In addition, a forgery localization module is applied to produce forgery proposals based on fused forgery-class activation sequences. Finally, a progressive refinement strategy is introduced to generate pseudo frame-level labels and leverage supervised semantic contrastive learning to amplify the semantic distinction between real and fake content, thereby continuously optimizing forgery-aware features. Extensive experiments show that the proposed LOCO achieves SOTA performance on three public benchmarks.
Weakness Analysis of Cyberspace Configuration Based on Reinforcement Learning
Jul 09, 2020

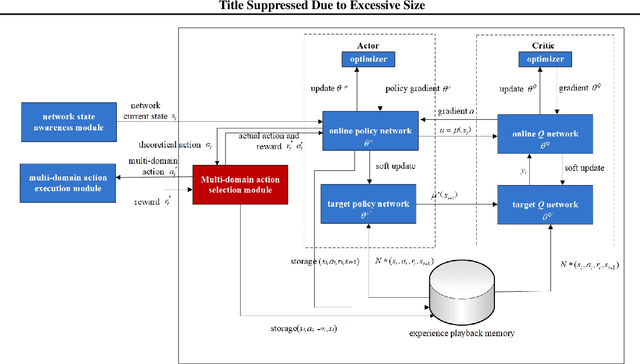
In this work, we present a learning-based approach to analysis cyberspace configuration. Unlike prior methods, our approach has the ability to learn from past experience and improve over time. In particular, as we train over a greater number of agents as attackers, our method becomes better at rapidly finding attack paths for previously hidden paths, especially in multiple domain cyberspace. To achieve these results, we pose finding attack paths as a Reinforcement Learning (RL) problem and train an agent to find multiple domain attack paths. To enable our RL policy to find more hidden attack paths, we ground representation introduction an multiple domain action select module in RL. By designing a simulated cyberspace experimental environment to verify our method. Our objective is to find more hidden attack paths, to analysis the weakness of cyberspace configuration. The experimental results show that our method can find more hidden multiple domain attack paths than existing baselines methods.