 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeS3K: Self-Supervised Semantic Keypoints for Robotic Manipulation via Multi-View Consistency
Oct 13, 2020

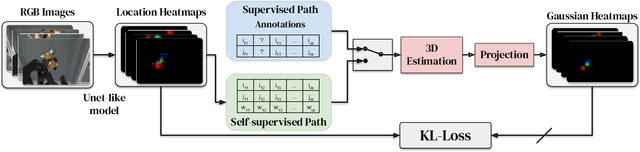
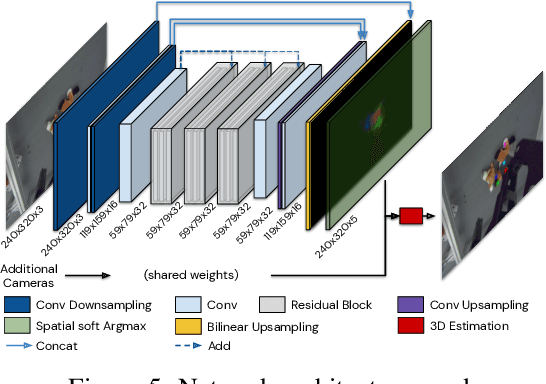
A robot's ability to act is fundamentally constrained by what it can perceive. Many existing approaches to visual representation learning utilize general-purpose training criteria, e.g. image reconstruction, smoothness in latent space, or usefulness for control, or else make use of large datasets annotated with specific features (bounding boxes, segmentations, etc.). However, both approaches often struggle to capture the fine-detail required for precision tasks on specific objects, e.g. grasping and mating a plug and socket. We argue that these difficulties arise from a lack of geometric structure in these models. In this work we advocate semantic 3D keypoints as a visual representation, and present a semi-supervised training objective that can allow instance or category-level keypoints to be trained to 1-5 millimeter-accuracy with minimal supervision. Furthermore, unlike local texture-based approaches, our model integrates contextual information from a large area and is therefore robust to occlusion, noise, and lack of discernible texture. We demonstrate that this ability to locate semantic keypoints enables high level scripting of human understandable behaviours. Finally we show that these keypoints provide a good way to define reward functions for reinforcement learning and are a good representation for training agents.
Deep Reinforcement Learning for Tactile Robotics: Learning to Type on a Braille Keyboard
Aug 06, 2020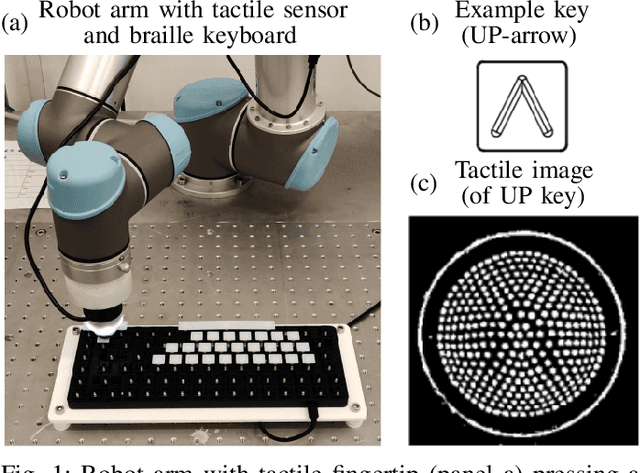
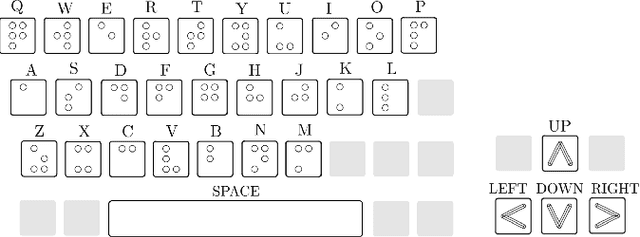
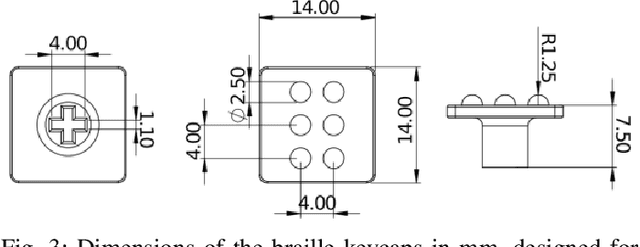
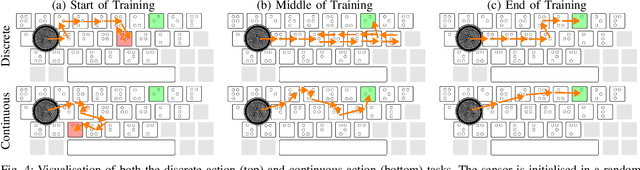
Artificial touch would seem well-suited for Reinforcement Learning (RL), since both paradigms rely on interaction with an environment. Here we propose a new environment and set of tasks to encourage development of tactile reinforcement learning: learning to type on a braille keyboard. Four tasks are proposed, progressing in difficulty from arrow to alphabet keys and from discrete to continuous actions. A simulated counterpart is also constructed by sampling tactile data from the physical environment. Using state-of-the-art deep RL algorithms, we show that all of these tasks can be successfully learnt in simulation, and 3 out of 4 tasks can be learned on the real robot. A lack of sample efficiency currently makes the continuous alphabet task impractical on the robot. To the best of our knowledge, this work presents the first demonstration of successfully training deep RL agents in the real world using observations that exclusively consist of tactile images. To aid future research utilising this environment, the code for this project has been released along with designs of the braille keycaps for 3D printing and a guide for recreating the experiments. A brief video summary is also available at https://youtu.be/eNylCA2uE_E.
A Distributional View on Multi-Objective Policy Optimization
May 15, 2020
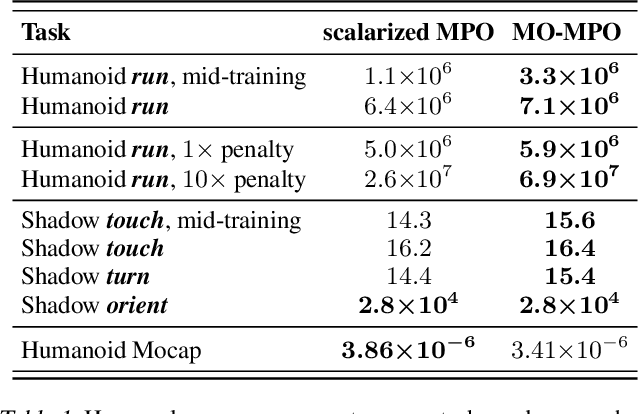
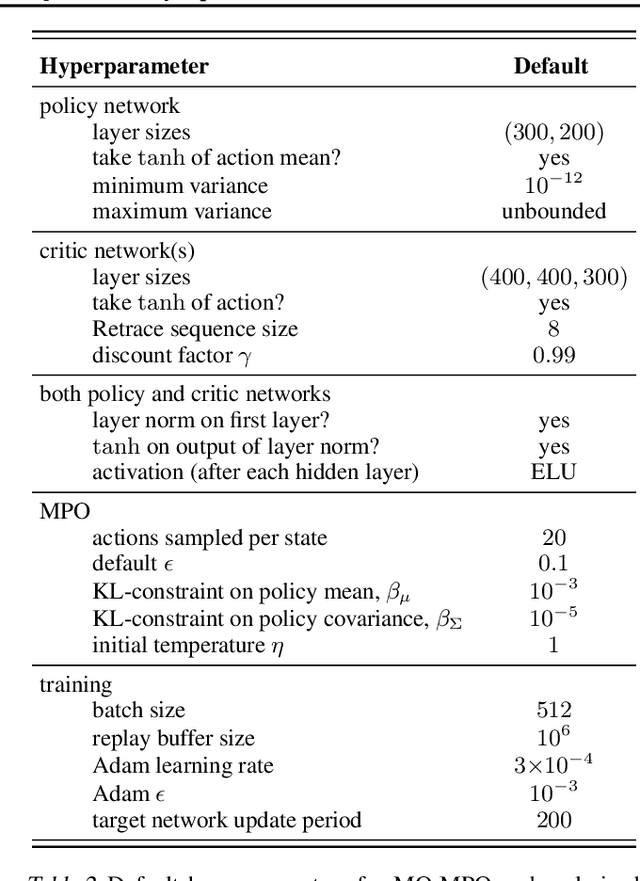
Many real-world problems require trading off multiple competing objectives. However, these objectives are often in different units and/or scales, which can make it challenging for practitioners to express numerical preferences over objectives in their native units. In this paper we propose a novel algorithm for multi-objective reinforcement learning that enables setting desired preferences for objectives in a scale-invariant way. We propose to learn an action distribution for each objective, and we use supervised learning to fit a parametric policy to a combination of these distributions. We demonstrate the effectiveness of our approach on challenging high-dimensional real and simulated robotics tasks, and show that setting different preferences in our framework allows us to trace out the space of nondominated solutions.
Disentangled Cumulants Help Successor Representations Transfer to New Tasks
Nov 25, 2019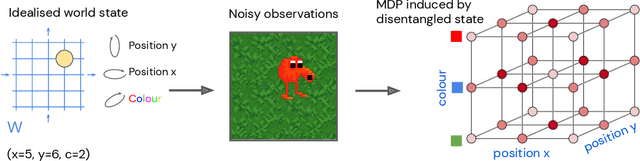
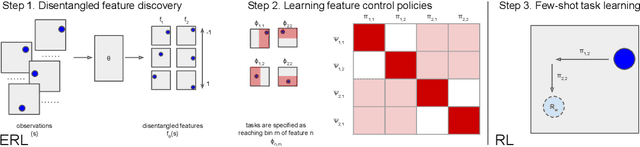
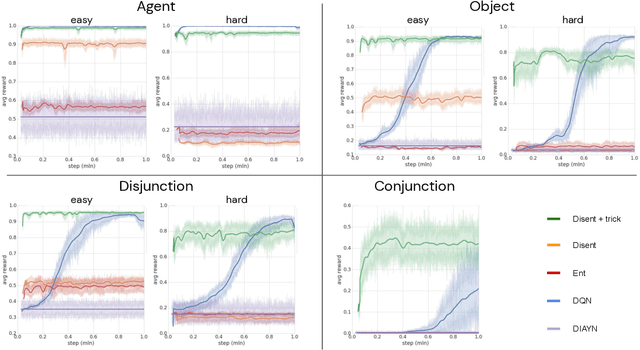
Biological intelligence can learn to solve many diverse tasks in a data efficient manner by re-using basic knowledge and skills from one task to another. Furthermore, many of such skills are acquired without explicit supervision in an intrinsically driven fashion. This is in contrast to the state-of-the-art reinforcement learning agents, which typically start learning each new task from scratch and struggle with knowledge transfer. In this paper we propose a principled way to learn a basis set of policies, which, when recombined through generalised policy improvement, come with guarantees on the coverage of the final task space. In particular, we concentrate on solving goal-based downstream tasks where the execution order of actions is not important. We demonstrate both theoretically and empirically that learning a small number of policies that reach intrinsically specified goal regions in a disentangled latent space can be re-used to quickly achieve a high level of performance on an exponentially larger number of externally specified, often significantly more complex downstream tasks. Our learning pipeline consists of two stages. First, the agent learns to perform intrinsically generated, goal-based tasks in the total absence of environmental rewards. Second, the agent leverages this experience to quickly achieve a high level of performance on numerous diverse externally specified tasks.
Attention Privileged Reinforcement Learning For Domain Transfer
Nov 19, 2019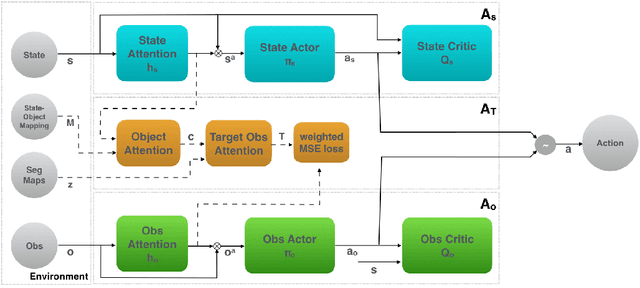
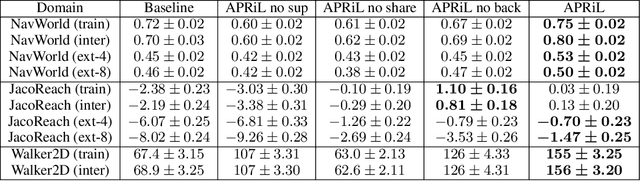
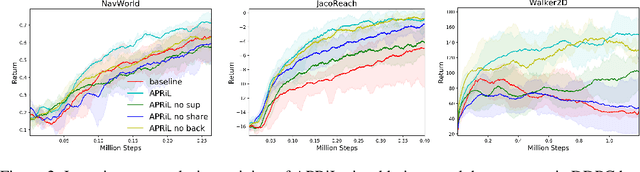
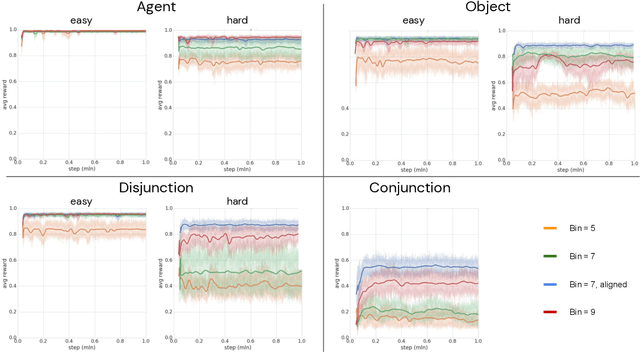
Applying reinforcement learning (RL) to physical systems presents notable challenges, given requirements regarding sample efficiency, safety, and physical constraints compared to simulated environments. To enable transfer of policies trained in simulation, randomising simulation parameters leads to more robust policies, but also significantly extends training time. In this paper, we exploit access to privileged information (such as environment states) often available in simulation, in order to improve and accelerate learning over randomised environments. We introduce Attention Privileged Reinforcement Learning (APRiL), which equips the agent with an attention mechanism and makes use of state information in simulation, learning to align attention between state- and image-based policies while additionally sharing generated data. During deployment we can apply the image-based policy to remove the requirement of access to additional information. We experimentally demonstrate accelerated and more robust learning on a number of diverse domains, leading to improved final performance for environments both within and outside the training distribution.
Continual Unsupervised Representation Learning
Oct 31, 2019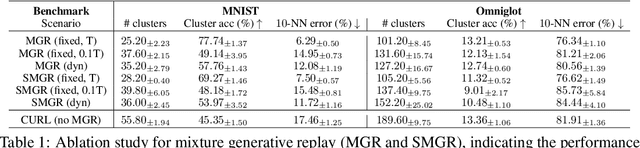
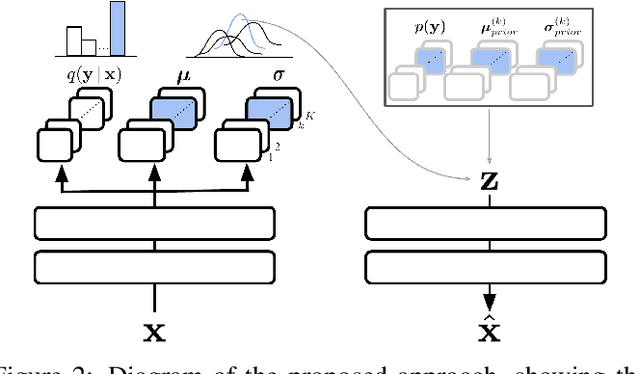

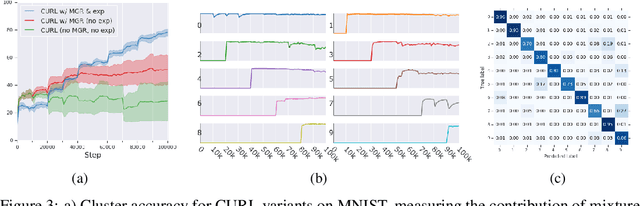
Continual learning aims to improve the ability of modern learning systems to deal with non-stationary distributions, typically by attempting to learn a series of tasks sequentially. Prior art in the field has largely considered supervised or reinforcement learning tasks, and often assumes full knowledge of task labels and boundaries. In this work, we propose an approach (CURL) to tackle a more general problem that we will refer to as unsupervised continual learning. The focus is on learning representations without any knowledge about task identity, and we explore scenarios when there are abrupt changes between tasks, smooth transitions from one task to another, or even when the data is shuffled. The proposed approach performs task inference directly within the model, is able to dynamically expand to capture new concepts over its lifetime, and incorporates additional rehearsal-based techniques to deal with catastrophic forgetting. We demonstrate the efficacy of CURL in an unsupervised learning setting with MNIST and Omniglot, where the lack of labels ensures no information is leaked about the task. Further, we demonstrate strong performance compared to prior art in an i.i.d setting, or when adapting the technique to supervised tasks such as incremental class learning.
Neural Execution of Graph Algorithms
Oct 23, 2019
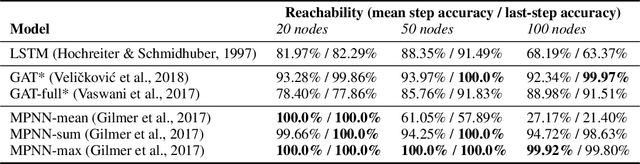
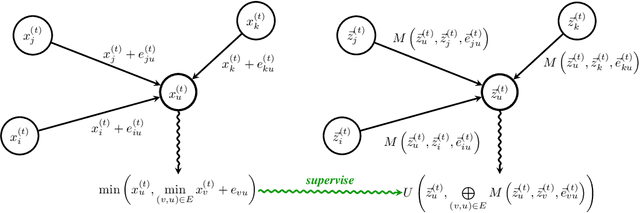
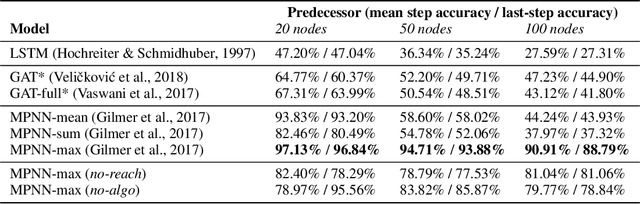
Graph Neural Networks (GNNs) are a powerful representational tool for solving problems on graph-structured inputs. In almost all cases so far, however, they have been applied to directly recovering a final solution from raw inputs, without explicit guidance on how to structure their problem-solving. Here, instead, we focus on learning in the space of algorithms: we train several state-of-the-art GNN architectures to imitate individual steps of classical graph algorithms, parallel (breadth-first search, Bellman-Ford) as well as sequential (Prim's algorithm). As graph algorithms usually rely on making discrete decisions within neighbourhoods, we hypothesise that maximisation-based message passing neural networks are best-suited for such objectives, and validate this claim empirically. We also demonstrate how learning in the space of algorithms can yield new opportunities for positive transfer between tasks---showing how learning a shortest-path algorithm can be substantially improved when simultaneously learning a reachability algorithm.
Stabilizing Transformers for Reinforcement Learning
Oct 13, 2019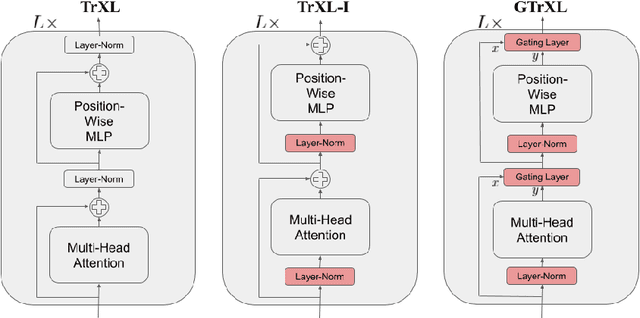
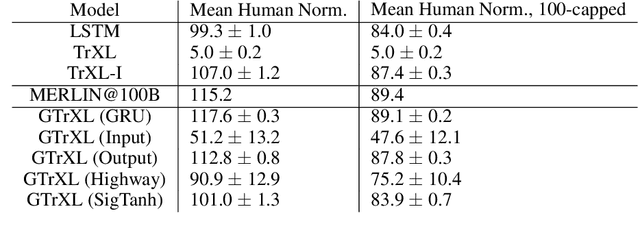
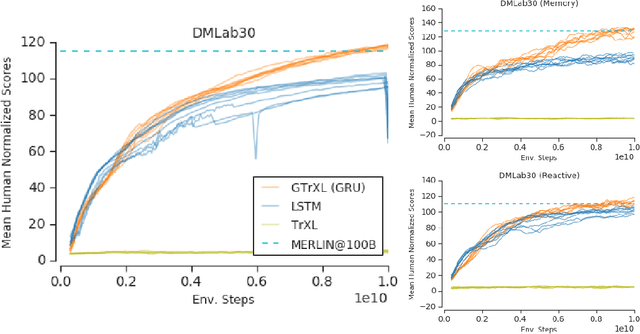
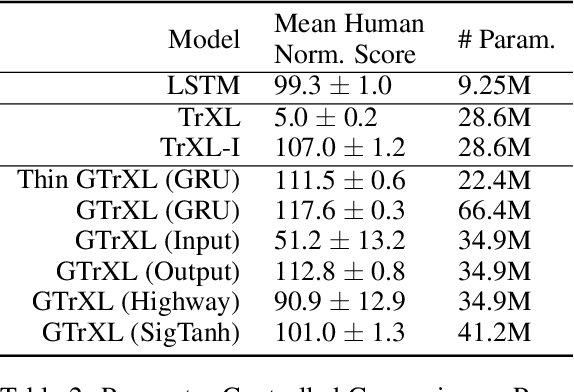
Owing to their ability to both effectively integrate information over long time horizons and scale to massive amounts of data, self-attention architectures have recently shown breakthrough success in natural language processing (NLP), achieving state-of-the-art results in domains such as language modeling and machine translation. Harnessing the transformer's ability to process long time horizons of information could provide a similar performance boost in partially observable reinforcement learning (RL) domains, but the large-scale transformers used in NLP have yet to be successfully applied to the RL setting. In this work we demonstrate that the standard transformer architecture is difficult to optimize, which was previously observed in the supervised learning setting but becomes especially pronounced with RL objectives. We propose architectural modifications that substantially improve the stability and learning speed of the original Transformer and XL variant. The proposed architecture, the Gated Transformer-XL (GTrXL), surpasses LSTMs on challenging memory environments and achieves state-of-the-art results on the multi-task DMLab-30 benchmark suite, exceeding the performance of an external memory architecture. We show that the GTrXL, trained using the same losses, has stability and performance that consistently matches or exceeds a competitive LSTM baseline, including on more reactive tasks where memory is less critical. GTrXL offers an easy-to-train, simple-to-implement but substantially more expressive architectural alternative to the standard multi-layer LSTM ubiquitously used for RL agents in partially observable environments.
Meta-Learning with Warped Gradient Descent
Aug 30, 2019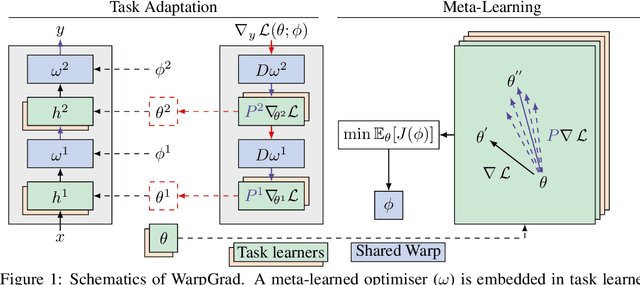
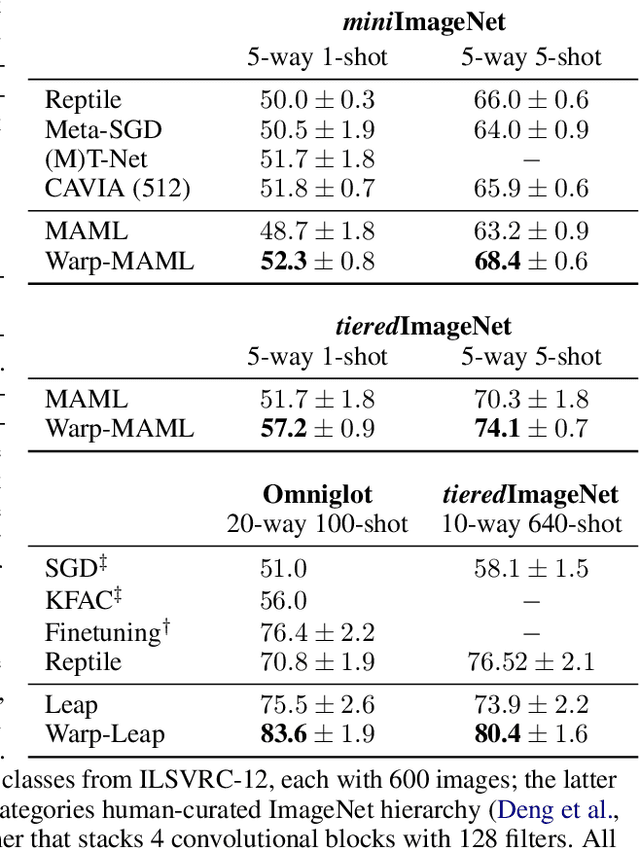
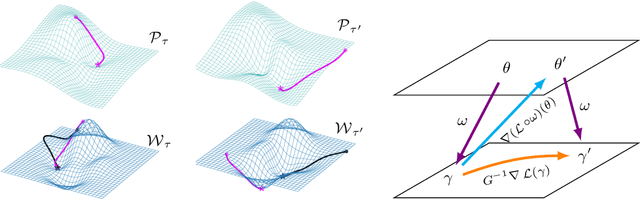
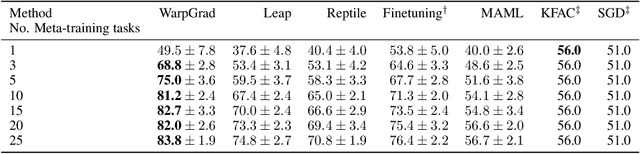
A versatile and effective approach to meta-learning is to infer a gradient-based up-date rule directly from data that promotes rapid learning of new tasks from the same distribution. Current methods rely on backpropagating through the learning process, limiting their scope to few-shot learning. In this work, we introduce Warped Gradient Descent (WarpGrad), a family of modular optimisers that can scale to arbitrary adaptation processes. WarpGrad methods meta-learn to warp task loss surfaces across the joint task-parameter distribution to facilitate gradient descent, which is achieved by a reparametrisation of neural networks that interleaves warp layers in the architecture. These layers are shared across task learners and fixed during adaptation; they represent a projection of task parameters into a meta-learned space that is conducive to task adaptation and standard backpropagation induces a form of gradient preconditioning. WarpGrad methods are computationally efficient and easy to implement as they rely on parameter sharing and backpropagation. They are readily combined with other meta-learners and can scale both in terms of model size and length of adaptation trajectories as meta-learning warp parameters do not require differentiation through task adaptation processes. We show empirically that WarpGrad optimisers meta-learn a warped space where gradient descent is well behaved, with faster convergence and better performance in a variety of settings, including few-shot, standard supervised, continual, and reinforcement learning.
Sim-to-Real via Sim-to-Sim: Data-efficient Robotic Grasping via Randomized-to-Canonical Adaptation Networks
Mar 25, 2019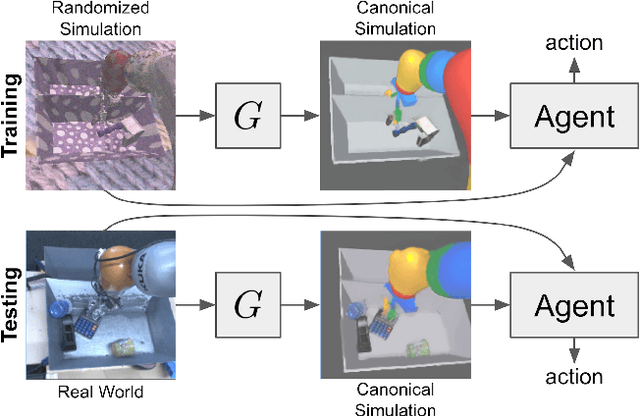
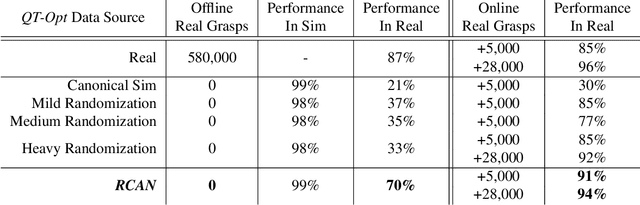


Real world data, especially in the domain of robotics, is notoriously costly to collect. One way to circumvent this can be to leverage the power of simulation to produce large amounts of labelled data. However, training models on simulated images does not readily transfer to real-world ones. Using domain adaptation methods to cross this "reality gap" requires a large amount of unlabelled real-world data, whilst domain randomization alone can waste modeling power. In this paper, we present Randomized-to-Canonical Adaptation Networks (RCANs), a novel approach to crossing the visual reality gap that uses no real-world data. Our method learns to translate randomized rendered images into their equivalent non-randomized, canonical versions. This in turn allows for real images to also be translated into canonical sim images. We demonstrate the effectiveness of this sim-to-real approach by training a vision-based closed-loop grasping reinforcement learning agent in simulation, and then transferring it to the real world to attain 70% zero-shot grasp success on unseen objects, a result that almost doubles the success of learning the same task directly on domain randomization alone. Additionally, by joint finetuning in the real-world with only 5,000 real-world grasps, our method achieves 91%, attaining comparable performance to a state-of-the-art system trained with 580,000 real-world grasps, resulting in a reduction of real-world data by more than 99%.