 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntentionNav: A Benchmark for Intent-Driven Object Navigation from Implicit Human Instruction
May 22, 2026Existing object navigation benchmarks usually tell an embodied agent which object category to find, such as microwave or chair. Human-facing embodied AI is often asked something less direct: "I need something to warm this food" or "the room feels stuffy." The agent must infer the object that can satisfy the need, find a scene-grounded instance, and decide whether the goal has been reached. We study this setting as intent-driven object navigation and introduce IntentionNav, a diagnostic benchmark for active object search from implicit human instructions. Each episode provides a free-text intent, RGB-D observations, and pose, but withholds the target object name. IntentionNav contains 500 intents over 176 Isaac Sim scenes and 64 target categories. Each intent is rewritten in four controlled instruction styles and annotated with one of four intent modes, separating surface phrasing from semantic cue type under matched geometry. This paired design supports analysis of target inference, language robustness, neighborhood reachability, and terminal success rather than only aggregate success. We evaluated three VLMs using a fixed active-navigation agent. Models identify the intended target in 48.3 percent of episodes and enter its 2 m neighborhood in 68.7 percent, but terminate successfully in only 24.9 percent and achieve grounded 1 m success in 5.5 percent. Success is highest for event-script intents (28.7 percent) and lower for physical-state and affordance intents (19.2 percent and 18.5 percent), showing that indirect human intent remains a bottleneck for target selection, visual verification, and terminal localization in active embodied search.
ITC-RWKV: Interactive Tissue-Cell Modeling with Recurrent Key-Value Aggregation for Histopathological Subtyping
Oct 24, 2025Accurate interpretation of histopathological images demands integration of information across spatial and semantic scales, from nuclear morphology and cellular textures to global tissue organization and disease-specific patterns. Although recent foundation models in pathology have shown strong capabilities in capturing global tissue context, their omission of cell-level feature modeling remains a key limitation for fine-grained tasks such as cancer subtype classification. To address this, we propose a dual-stream architecture that models the interplay between macroscale tissue features and aggregated cellular representations. To efficiently aggregate information from large cell sets, we propose a receptance-weighted key-value aggregation model, a recurrent transformer that captures inter-cell dependencies with linear complexity. Furthermore, we introduce a bidirectional tissue-cell interaction module to enable mutual attention between localized cellular cues and their surrounding tissue environment. Experiments on four histopathological subtype classification benchmarks show that the proposed method outperforms existing models, demonstrating the critical role of cell-level aggregation and tissue-cell interaction in fine-grained computational pathology.
CLEAR-IR: Clarity-Enhanced Active Reconstruction of Infrared Imagery
Oct 06, 2025



This paper presents a novel approach for enabling robust robotic perception in dark environments using infrared (IR) stream. IR stream is less susceptible to noise than RGB in low-light conditions. However, it is dominated by active emitter patterns that hinder high-level tasks such as object detection, tracking and localisation. To address this, a U-Net-based architecture is proposed that reconstructs clean IR images from emitter-populated input, improving both image quality and downstream robotic performance. This approach outperforms existing enhancement techniques and enables reliable operation of vision-driven robotic systems across illumination conditions from well-lit to extreme low-light scenes.
DPC-QA Net: A No-Reference Dual-Stream Perceptual and Cellular Quality Assessment Network for Histopathology Images
Sep 19, 2025Reliable whole slide imaging (WSI) hinges on image quality,yet staining artefacts, defocus, and cellular degradations are common. We present DPC-QA Net, a no-reference dual-stream network that couples wavelet-based global difference perception with cellular quality assessment from nuclear and membrane embeddings via an Aggr-RWKV module. Cross-attention fusion and multi-term losses align perceptual and cellular cues. Across different datasets, our model detects staining, membrane, and nuclear issues with >92% accuracy and aligns well with usability scores; on LIVEC and KonIQ it outperforms state-of-the-art NR-IQA. A downstream study further shows strong positive correlations between predicted quality and cell recognition accuracy (e.g., nuclei PQ/Dice, membrane boundary F-score), enabling practical pre-screening of WSI regions for computational pathology.
QWD-GAN: Quality-aware Wavelet-driven GAN for Unsupervised Medical Microscopy Images Denoising
Sep 19, 2025



Image denoising plays a critical role in biomedical and microscopy imaging, especially when acquiring wide-field fluorescence-stained images. This task faces challenges in multiple fronts, including limitations in image acquisition conditions, complex noise types, algorithm adaptability, and clinical application demands. Although many deep learning-based denoising techniques have demonstrated promising results, further improvements are needed in preserving image details, enhancing algorithmic efficiency, and increasing clinical interpretability. We propose an unsupervised image denoising method based on a Generative Adversarial Network (GAN) architecture. The approach introduces a multi-scale adaptive generator based on the Wavelet Transform and a dual-branch discriminator that integrates difference perception feature maps with original features. Experimental results on multiple biomedical microscopy image datasets show that the proposed model achieves state-of-the-art denoising performance, particularly excelling in the preservation of high-frequency information. Furthermore, the dual-branch discriminator is seamlessly compatible with various GAN frameworks. The proposed quality-aware, wavelet-driven GAN denoising model is termed as QWD-GAN.
Reg3D: Reconstructive Geometry Instruction Tuning for 3D Scene Understanding
Sep 03, 2025The rapid development of Large Multimodal Models (LMMs) has led to remarkable progress in 2D visual understanding; however, extending these capabilities to 3D scene understanding remains a significant challenge. Existing approaches predominantly rely on text-only supervision, which fails to provide the geometric constraints required for learning robust 3D spatial representations. In this paper, we introduce Reg3D, a novel Reconstructive Geometry Instruction Tuning framework that addresses this limitation by incorporating geometry-aware supervision directly into the training process. Our key insight is that effective 3D understanding necessitates reconstructing underlying geometric structures rather than merely describing them. Unlike existing methods that inject 3D information solely at the input level, Reg3D adopts a dual-supervision paradigm that leverages 3D geometric information both as input and as explicit learning targets. Specifically, we design complementary object-level and frame-level reconstruction tasks within a dual-encoder architecture, enforcing geometric consistency to encourage the development of spatial reasoning capabilities. Extensive experiments on ScanQA, Scan2Cap, ScanRefer, and SQA3D demonstrate that Reg3D delivers substantial performance improvements, establishing a new training paradigm for spatially aware multimodal models.
PointGS: Point Attention-Aware Sparse View Synthesis with Gaussian Splatting
Jun 12, 20253D Gaussian splatting (3DGS) is an innovative rendering technique that surpasses the neural radiance field (NeRF) in both rendering speed and visual quality by leveraging an explicit 3D scene representation. Existing 3DGS approaches require a large number of calibrated views to generate a consistent and complete scene representation. When input views are limited, 3DGS tends to overfit the training views, leading to noticeable degradation in rendering quality. To address this limitation, we propose a Point-wise Feature-Aware Gaussian Splatting framework that enables real-time, high-quality rendering from sparse training views. Specifically, we first employ the latest stereo foundation model to estimate accurate camera poses and reconstruct a dense point cloud for Gaussian initialization. We then encode the colour attributes of each 3D Gaussian by sampling and aggregating multiscale 2D appearance features from sparse inputs. To enhance point-wise appearance representation, we design a point interaction network based on a self-attention mechanism, allowing each Gaussian point to interact with its nearest neighbors. These enriched features are subsequently decoded into Gaussian parameters through two lightweight multi-layer perceptrons (MLPs) for final rendering. Extensive experiments on diverse benchmarks demonstrate that our method significantly outperforms NeRF-based approaches and achieves competitive performance under few-shot settings compared to the state-of-the-art 3DGS methods.
Geometric Prior-Guided Neural Implicit Surface Reconstruction in the Wild
May 12, 2025Neural implicit surface reconstruction using volume rendering techniques has recently achieved significant advancements in creating high-fidelity surfaces from multiple 2D images. However, current methods primarily target scenes with consistent illumination and struggle to accurately reconstruct 3D geometry in uncontrolled environments with transient occlusions or varying appearances. While some neural radiance field (NeRF)-based variants can better manage photometric variations and transient objects in complex scenes, they are designed for novel view synthesis rather than precise surface reconstruction due to limited surface constraints. To overcome this limitation, we introduce a novel approach that applies multiple geometric constraints to the implicit surface optimization process, enabling more accurate reconstructions from unconstrained image collections. First, we utilize sparse 3D points from structure-from-motion (SfM) to refine the signed distance function estimation for the reconstructed surface, with a displacement compensation to accommodate noise in the sparse points. Additionally, we employ robust normal priors derived from a normal predictor, enhanced by edge prior filtering and multi-view consistency constraints, to improve alignment with the actual surface geometry. Extensive testing on the Heritage-Recon benchmark and other datasets has shown that the proposed method can accurately reconstruct surfaces from in-the-wild images, yielding geometries with superior accuracy and granularity compared to existing techniques. Our approach enables high-quality 3D reconstruction of various landmarks, making it applicable to diverse scenarios such as digital preservation of cultural heritage sites.
Sparse Spatial Attention Network for Semantic Segmentation
Sep 04, 2021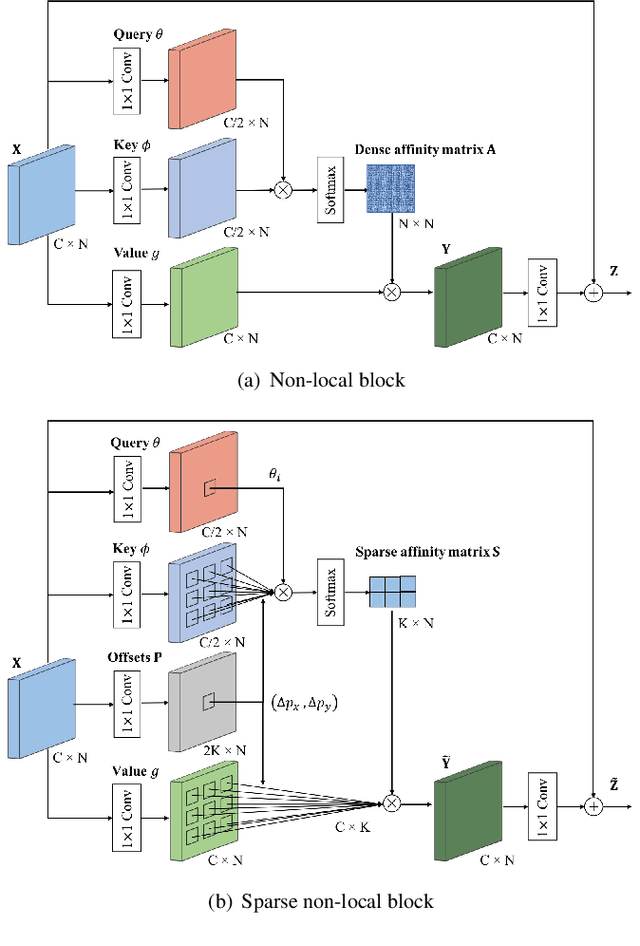
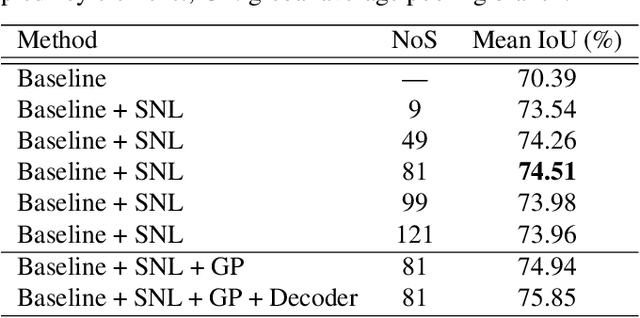
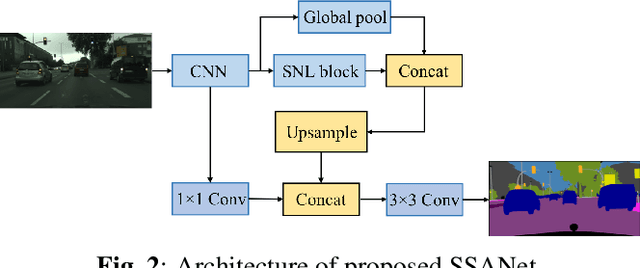

The spatial attention mechanism captures long-range dependencies by aggregating global contextual information to each query location, which is beneficial for semantic segmentation. In this paper, we present a sparse spatial attention network (SSANet) to improve the efficiency of the spatial attention mechanism without sacrificing the performance. Specifically, a sparse non-local (SNL) block is proposed to sample a subset of key and value elements for each query element to capture long-range relations adaptively and generate a sparse affinity matrix to aggregate contextual information efficiently. Experimental results show that the proposed approach outperforms other context aggregation methods and achieves state-of-the-art performance on the Cityscapes, PASCAL Context and ADE20K datasets.
Graph Convolutional Networks in Feature Space for Image Deblurring and Super-resolution
May 21, 2021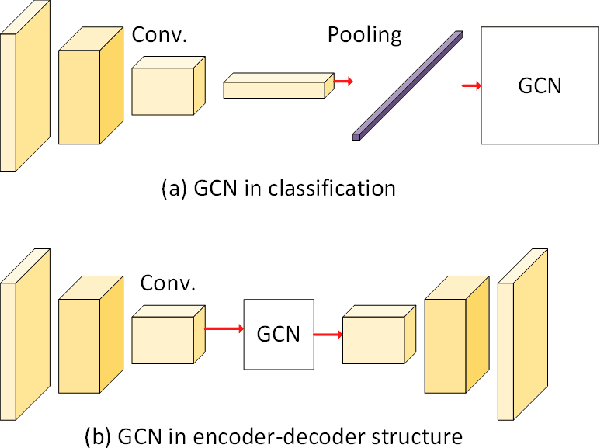
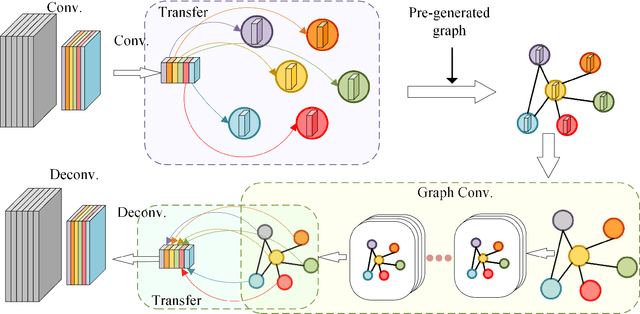
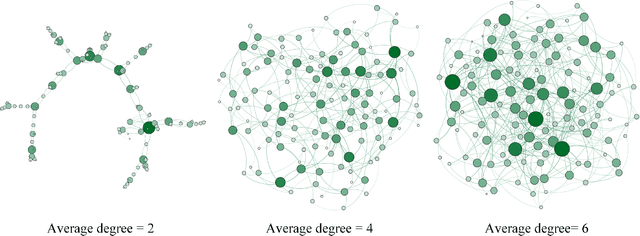

Graph convolutional networks (GCNs) have achieved great success in dealing with data of non-Euclidean structures. Their success directly attributes to fitting graph structures effectively to data such as in social media and knowledge databases. For image processing applications, the use of graph structures and GCNs have not been fully explored. In this paper, we propose a novel encoder-decoder network with added graph convolutions by converting feature maps to vertexes of a pre-generated graph to synthetically construct graph-structured data. By doing this, we inexplicitly apply graph Laplacian regularization to the feature maps, making them more structured. The experiments show that it significantly boosts performance for image restoration tasks, including deblurring and super-resolution. We believe it opens up opportunities for GCN-based approaches in more applications.
* Accepted by IJCNN 2021 (Oral)