 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpectral Souping: A Unified Framework for Online Preference Alignment
May 19, 2026Reinforcement Learning from Human Feedback (RLHF) effectively aligns Large Language Models (LLMs) with aggregate human preferences but often fails to address the diverse and conflicting needs of individual users. To overcome this issue, we introduce Spectral Souping, a unified framework for efficient, online preference alignment. Our contribution is the discovery of a universal spectral representation within LLMs, which is proven to be highly amenable to model merging. This theoretical insight enables a two-phase methodology: we first learn a basis of specialized policies offline, each focused on a distinct, fine-grained preference dimension. An online adaptation algorithm then efficiently ``soups'' these policies at inference time, either by merging their outputs or parameters, enabling rapid model adaptation without the need for costly online retraining w.r.t. tailored preference rewards. Experiments on online preference alignment benchmarks demonstrate that our method achieves significant performance improvements over existing state-of-the-art approaches, presenting a scalable and computationally efficient solution for dynamically adapting LLMs to individual user preferences.
Video as the New Language for Real-World Decision Making
Feb 27, 2024



Both text and video data are abundant on the internet and support large-scale self-supervised learning through next token or frame prediction. However, they have not been equally leveraged: language models have had significant real-world impact, whereas video generation has remained largely limited to media entertainment. Yet video data captures important information about the physical world that is difficult to express in language. To address this gap, we discuss an under-appreciated opportunity to extend video generation to solve tasks in the real world. We observe how, akin to language, video can serve as a unified interface that can absorb internet knowledge and represent diverse tasks. Moreover, we demonstrate how, like language models, video generation can serve as planners, agents, compute engines, and environment simulators through techniques such as in-context learning, planning and reinforcement learning. We identify major impact opportunities in domains such as robotics, self-driving, and science, supported by recent work that demonstrates how such advanced capabilities in video generation are plausibly within reach. Lastly, we identify key challenges in video generation that mitigate progress. Addressing these challenges will enable video generation models to demonstrate unique value alongside language models in a wider array of AI applications.
Temporal Abstraction in Reinforcement Learning with the Successor Representation
Oct 12, 2021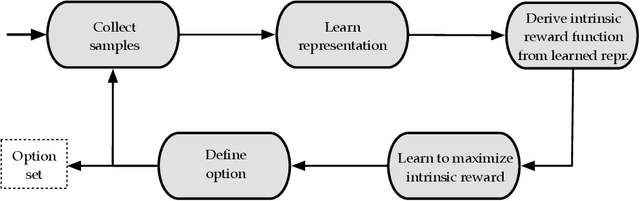
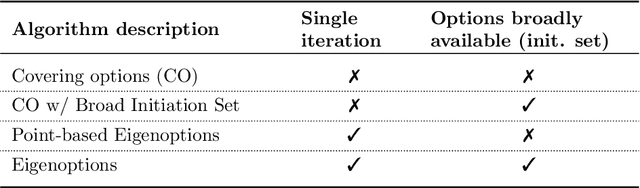
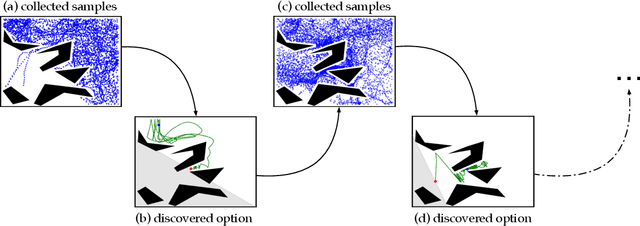
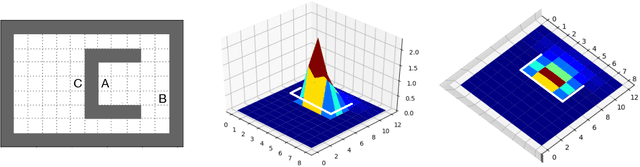
Reasoning at multiple levels of temporal abstraction is one of the key attributes of intelligence. In reinforcement learning, this is often modeled through temporally extended courses of actions called options. Options allow agents to make predictions and to operate at different levels of abstraction within an environment. Nevertheless, approaches based on the options framework often start with the assumption that a reasonable set of options is known beforehand. When this is not the case, there are no definitive answers for which options one should consider. In this paper, we argue that the successor representation (SR), which encodes states based on the pattern of state visitation that follows them, can be seen as a natural substrate for the discovery and use of temporal abstractions. To support our claim, we take a big picture view of recent results, showing how the SR can be used to discover options that facilitate either temporally-extended exploration or planning. We cast these results as instantiations of a general framework for option discovery in which the agent's representation is used to identify useful options, which are then used to further improve its representation. This results in a virtuous, never-ending, cycle in which both the representation and the options are constantly refined based on each other. Beyond option discovery itself, we discuss how the SR allows us to augment a set of options into a combinatorially large counterpart without additional learning. This is achieved through the combination of previously learned options. Our empirical evaluation focuses on options discovered for temporally-extended exploration and on the use of the SR to combine them. The results of our experiments shed light on design decisions involved in the definition of options and demonstrate the synergy of different methods based on the SR, such as eigenoptions and the option keyboard.
Discovering Diverse Nearly Optimal Policies withSuccessor Features
Jun 01, 2021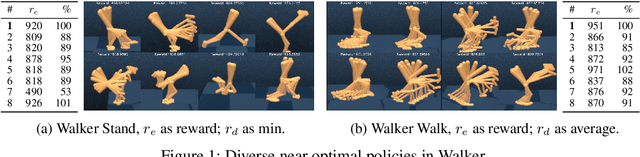


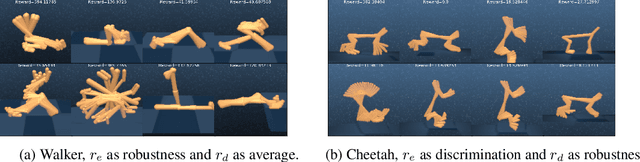
Finding different solutions to the same problem is a key aspect of intelligence associated with creativity and adaptation to novel situations. In reinforcement learning, a set of diverse policies can be useful for exploration, transfer, hierarchy, and robustness. We propose Diverse Successive Policies, a method for discovering policies that are diverse in the space of Successor Features, while assuring that they are near optimal. We formalize the problem as a Constrained Markov Decision Process (CMDP) where the goal is to find policies that maximize diversity, characterized by an intrinsic diversity reward, while remaining near-optimal with respect to the extrinsic reward of the MDP. We also analyze how recently proposed robustness and discrimination rewards perform and find that they are sensitive to the initialization of the procedure and may converge to sub-optimal solutions. To alleviate this, we propose new explicit diversity rewards that aim to minimize the correlation between the Successor Features of the policies in the set. We compare the different diversity mechanisms in the DeepMind Control Suite and find that the type of explicit diversity we are proposing is important to discover distinct behavior, like for example different locomotion patterns.
Coverage as a Principle for Discovering Transferable Behavior in Reinforcement Learning
Feb 24, 2021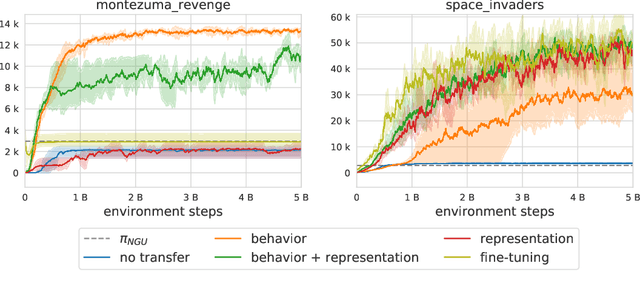
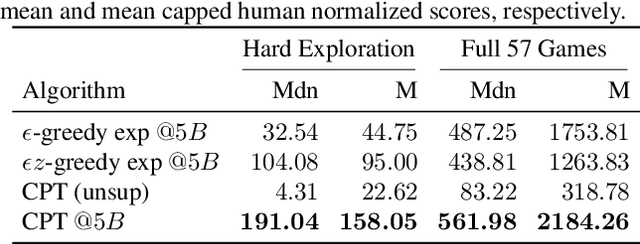
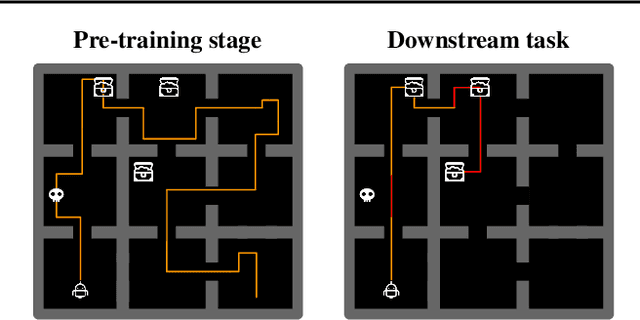
Designing agents that acquire knowledge autonomously and use it to solve new tasks efficiently is an important challenge in reinforcement learning, and unsupervised learning provides a useful paradigm for autonomous acquisition of task-agnostic knowledge. In supervised settings, representations discovered through unsupervised pre-training offer important benefits when transferred to downstream tasks. Given the nature of the reinforcement learning problem, we argue that representation alone is not enough for efficient transfer in challenging domains and explore how to transfer knowledge through behavior. The behavior of pre-trained policies may be used for solving the task at hand (exploitation), as well as for collecting useful data to solve the problem (exploration). We argue that policies pre-trained to maximize coverage will produce behavior that is useful for both strategies. When using these policies for both exploitation and exploration, our agents discover better solutions. The largest gains are generally observed in domains requiring structured exploration, including settings where the behavior of the pre-trained policies is misaligned with the downstream task.
Discovering a set of policies for the worst case reward
Feb 08, 2021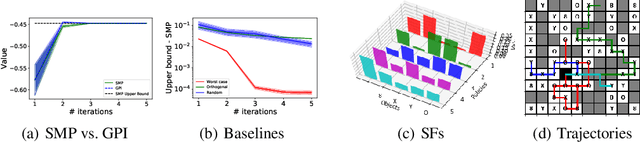
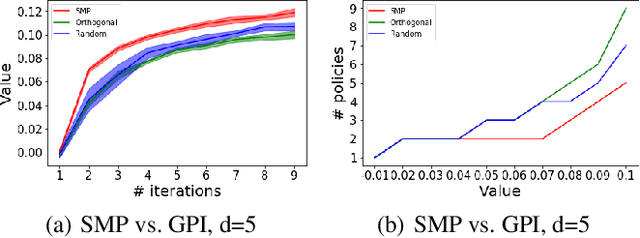
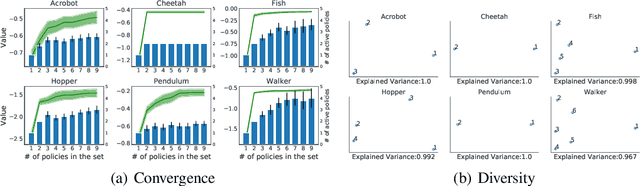

We study the problem of how to construct a set of policies that can be composed together to solve a collection of reinforcement learning tasks. Each task is a different reward function defined as a linear combination of known features. We consider a specific class of policy compositions which we call set improving policies (SIPs): given a set of policies and a set of tasks, a SIP is any composition of the former whose performance is at least as good as that of its constituents across all the tasks. We focus on the most conservative instantiation of SIPs, set-max policies (SMPs), so our analysis extends to any SIP. This includes known policy-composition operators like generalized policy improvement. Our main contribution is a policy iteration algorithm that builds a set of policies in order to maximize the worst-case performance of the resulting SMP on the set of tasks. The algorithm works by successively adding new policies to the set. We show that the worst-case performance of the resulting SMP strictly improves at each iteration, and the algorithm only stops when there does not exist a policy that leads to improved performance. We empirically evaluate our algorithm on a grid world and also on a set of domains from the DeepMind control suite. We confirm our theoretical results regarding the monotonically improving performance of our algorithm. Interestingly, we also show empirically that the sets of policies computed by the algorithm are diverse, leading to different trajectories in the grid world and very distinct locomotion skills in the control suite.
Temporal Difference Uncertainties as a Signal for Exploration
Oct 05, 2020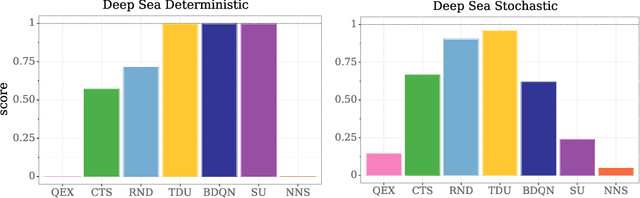
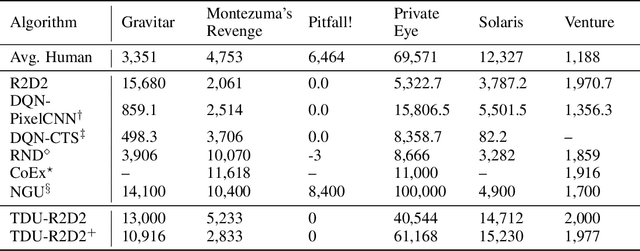
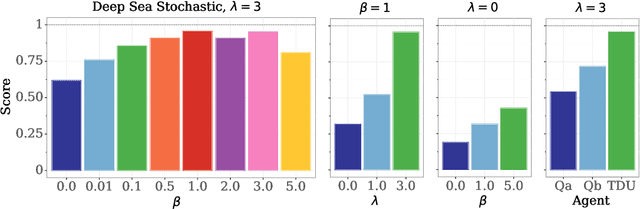

An effective approach to exploration in reinforcement learning is to rely on an agent's uncertainty over the optimal policy, which can yield near-optimal exploration strategies in tabular settings. However, in non-tabular settings that involve function approximators, obtaining accurate uncertainty estimates is almost as challenging a problem. In this paper, we highlight that value estimates are easily biased and temporally inconsistent. In light of this, we propose a novel method for estimating uncertainty over the value function that relies on inducing a distribution over temporal difference errors. This exploration signal controls for state-action transitions so as to isolate uncertainty in value that is due to uncertainty over the agent's parameters. Because our measure of uncertainty conditions on state-action transitions, we cannot act on this measure directly. Instead, we incorporate it as an intrinsic reward and treat exploration as a separate learning problem, induced by the agent's temporal difference uncertainties. We introduce a distinct exploration policy that learns to collect data with high estimated uncertainty, which gives rise to a curriculum that smoothly changes throughout learning and vanishes in the limit of perfect value estimates. We evaluate our method on hard exploration tasks, including Deep Sea and Atari 2600 environments and find that our proposed form of exploration facilitates both diverse and deep exploration.
Disentangled Cumulants Help Successor Representations Transfer to New Tasks
Nov 25, 2019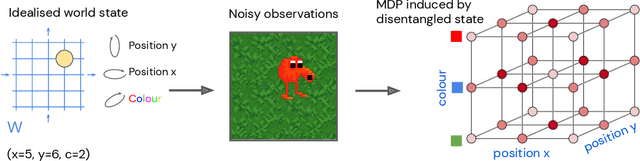
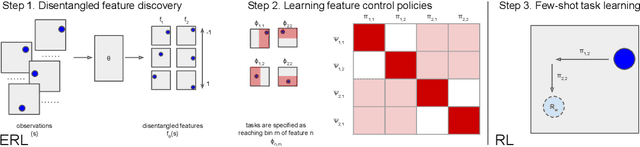
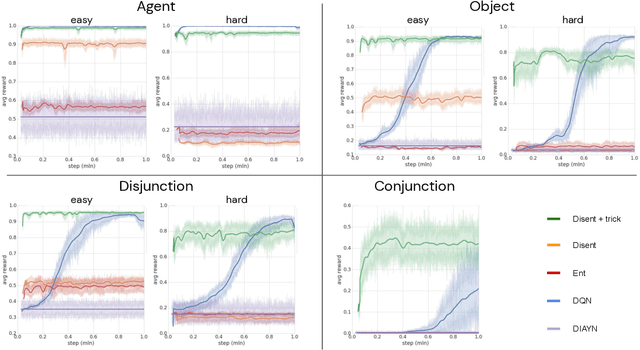
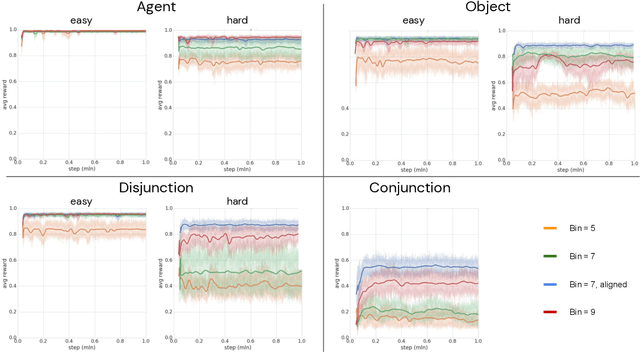
Biological intelligence can learn to solve many diverse tasks in a data efficient manner by re-using basic knowledge and skills from one task to another. Furthermore, many of such skills are acquired without explicit supervision in an intrinsically driven fashion. This is in contrast to the state-of-the-art reinforcement learning agents, which typically start learning each new task from scratch and struggle with knowledge transfer. In this paper we propose a principled way to learn a basis set of policies, which, when recombined through generalised policy improvement, come with guarantees on the coverage of the final task space. In particular, we concentrate on solving goal-based downstream tasks where the execution order of actions is not important. We demonstrate both theoretically and empirically that learning a small number of policies that reach intrinsically specified goal regions in a disentangled latent space can be re-used to quickly achieve a high level of performance on an exponentially larger number of externally specified, often significantly more complex downstream tasks. Our learning pipeline consists of two stages. First, the agent learns to perform intrinsically generated, goal-based tasks in the total absence of environmental rewards. Second, the agent leverages this experience to quickly achieve a high level of performance on numerous diverse externally specified tasks.
General non-linear Bellman equations
Jul 08, 2019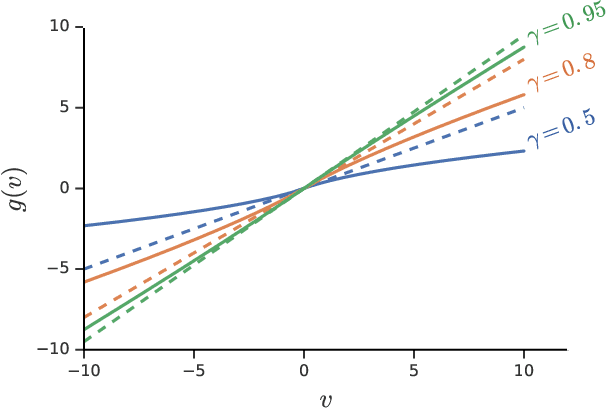
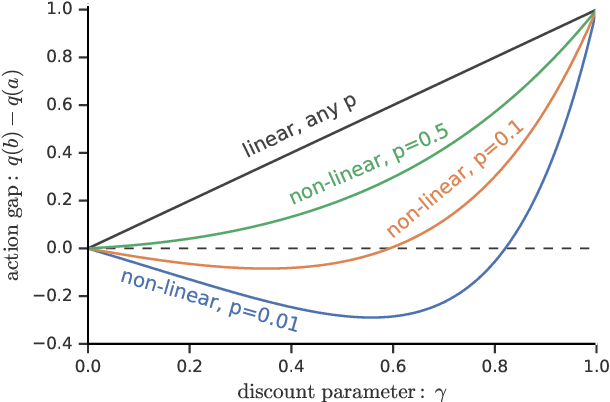
We consider a general class of non-linear Bellman equations. These open up a design space of algorithms that have interesting properties, which has two potential advantages. First, we can perhaps better model natural phenomena. For instance, hyperbolic discounting has been proposed as a mathematical model that matches human and animal data well, and can therefore be used to explain preference orderings. We present a different mathematical model that matches the same data, but that makes very different predictions under other circumstances. Second, the larger design space can perhaps lead to algorithms that perform better, similar to how discount factors are often used in practice even when the true objective is undiscounted. We show that many of the resulting Bellman operators still converge to a fixed point, and therefore that the resulting algorithms are reasonable and inherit many beneficial properties of their linear counterparts.
Adaptive Temporal-Difference Learning for Policy Evaluation with Per-State Uncertainty Estimates
Jun 19, 2019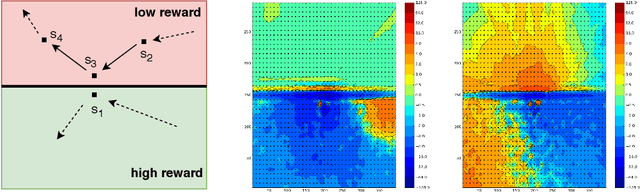
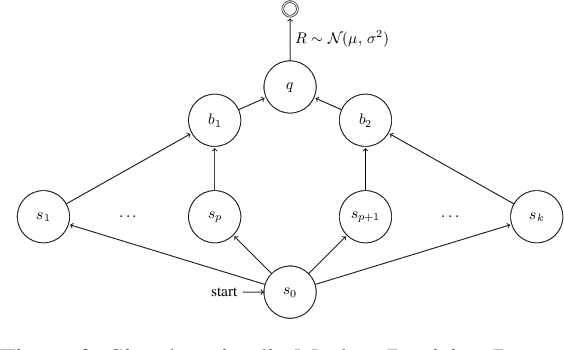
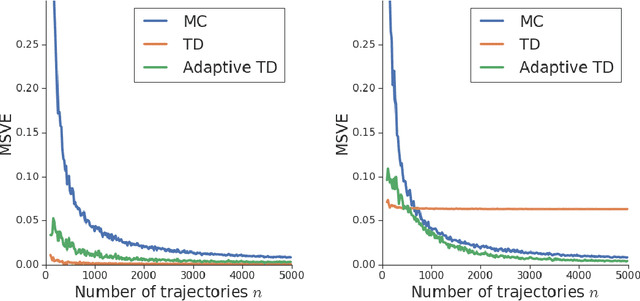
We consider the core reinforcement-learning problem of on-policy value function approximation from a batch of trajectory data, and focus on various issues of Temporal Difference (TD) learning and Monte Carlo (MC) policy evaluation. The two methods are known to achieve complementary bias-variance trade-off properties, with TD tending to achieve lower variance but potentially higher bias. In this paper, we argue that the larger bias of TD can be a result of the amplification of local approximation errors. We address this by proposing an algorithm that adaptively switches between TD and MC in each state, thus mitigating the propagation of errors. Our method is based on learned confidence intervals that detect biases of TD estimates. We demonstrate in a variety of policy evaluation tasks that this simple adaptive algorithm performs competitively with the best approach in hindsight, suggesting that learned confidence intervals are a powerful technique for adapting policy evaluation to use TD or MC returns in a data-driven way.