 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePowerpropagation: A sparsity inducing weight reparameterisation
Oct 06, 2021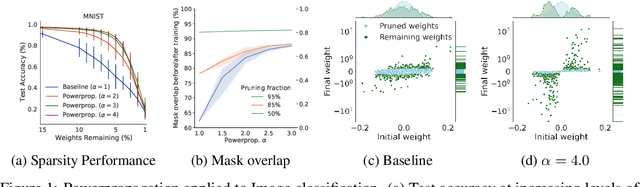
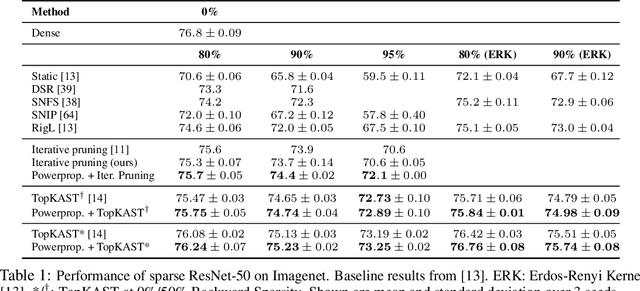
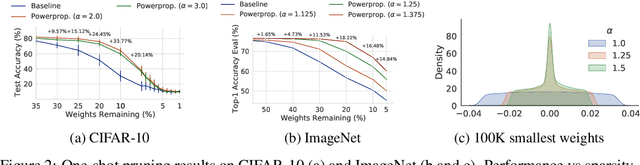
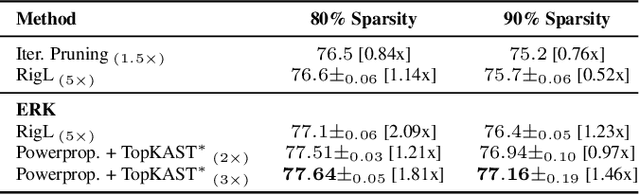
The training of sparse neural networks is becoming an increasingly important tool for reducing the computational footprint of models at training and evaluation, as well enabling the effective scaling up of models. Whereas much work over the years has been dedicated to specialised pruning techniques, little attention has been paid to the inherent effect of gradient based training on model sparsity. In this work, we introduce Powerpropagation, a new weight-parameterisation for neural networks that leads to inherently sparse models. Exploiting the behaviour of gradient descent, our method gives rise to weight updates exhibiting a "rich get richer" dynamic, leaving low-magnitude parameters largely unaffected by learning. Models trained in this manner exhibit similar performance, but have a distribution with markedly higher density at zero, allowing more parameters to be pruned safely. Powerpropagation is general, intuitive, cheap and straight-forward to implement and can readily be combined with various other techniques. To highlight its versatility, we explore it in two very different settings: Firstly, following a recent line of work, we investigate its effect on sparse training for resource-constrained settings. Here, we combine Powerpropagation with a traditional weight-pruning technique as well as recent state-of-the-art sparse-to-sparse algorithms, showing superior performance on the ImageNet benchmark. Secondly, we advocate the use of sparsity in overcoming catastrophic forgetting, where compressed representations allow accommodating a large number of tasks at fixed model capacity. In all cases our reparameterisation considerably increases the efficacy of the off-the-shelf methods.
Top-KAST: Top-K Always Sparse Training
Jun 07, 2021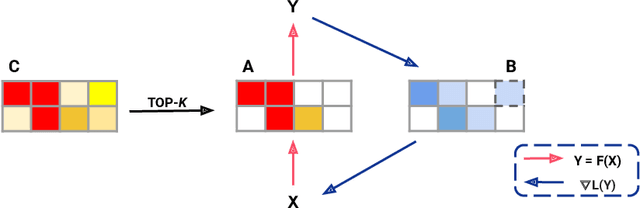
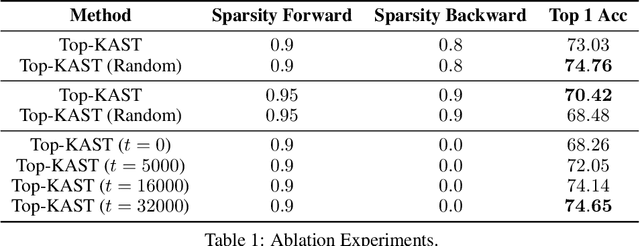
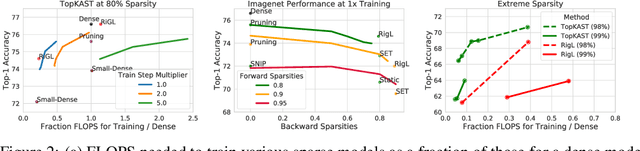
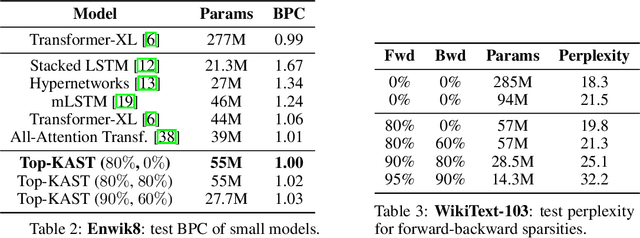
Sparse neural networks are becoming increasingly important as the field seeks to improve the performance of existing models by scaling them up, while simultaneously trying to reduce power consumption and computational footprint. Unfortunately, most existing methods for inducing performant sparse models still entail the instantiation of dense parameters, or dense gradients in the backward-pass, during training. For very large models this requirement can be prohibitive. In this work we propose Top-KAST, a method that preserves constant sparsity throughout training (in both the forward and backward-passes). We demonstrate the efficacy of our approach by showing that it performs comparably to or better than previous works when training models on the established ImageNet benchmark, whilst fully maintaining sparsity. In addition to our ImageNet results, we also demonstrate our approach in the domain of language modeling where the current best performing architectures tend to have tens of billions of parameters and scaling up does not yet seem to have saturated performance. Sparse versions of these architectures can be run with significantly fewer resources, making them more widely accessible and applicable. Furthermore, in addition to being effective, our approach is straightforward and can easily be implemented in a wide range of existing machine learning frameworks with only a few additional lines of code. We therefore hope that our contribution will help enable the broader community to explore the potential held by massive models, without incurring massive computational cost.
Perception-Prediction-Reaction Agents for Deep Reinforcement Learning
Jun 26, 2020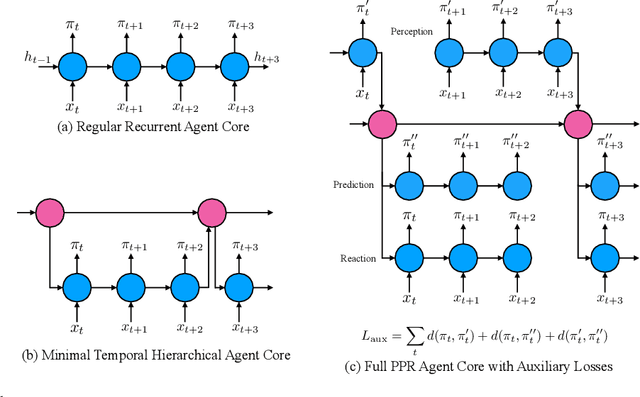

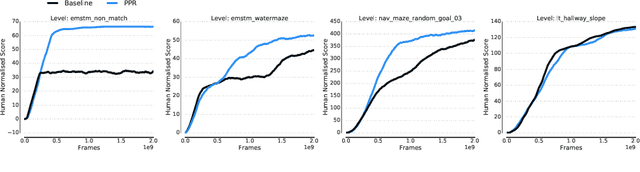
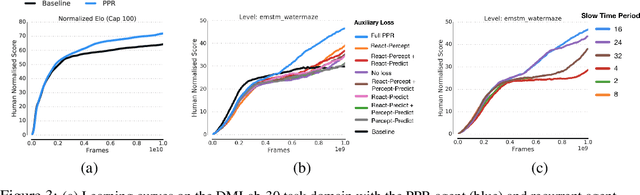
We introduce a new recurrent agent architecture and associated auxiliary losses which improve reinforcement learning in partially observable tasks requiring long-term memory. We employ a temporal hierarchy, using a slow-ticking recurrent core to allow information to flow more easily over long time spans, and three fast-ticking recurrent cores with connections designed to create an information asymmetry. The \emph{reaction} core incorporates new observations with input from the slow core to produce the agent's policy; the \emph{perception} core accesses only short-term observations and informs the slow core; lastly, the \emph{prediction} core accesses only long-term memory. An auxiliary loss regularizes policies drawn from all three cores against each other, enacting the prior that the policy should be expressible from either recent or long-term memory. We present the resulting \emph{Perception-Prediction-Reaction} (PPR) agent and demonstrate its improved performance over a strong LSTM-agent baseline in DMLab-30, particularly in tasks requiring long-term memory. We further show significant improvements in Capture the Flag, an environment requiring agents to acquire a complicated mixture of skills over long time scales. In a series of ablation experiments, we probe the importance of each component of the PPR agent, establishing that the entire, novel combination is necessary for this intriguing result.
Compressive Transformers for Long-Range Sequence Modelling
Nov 13, 2019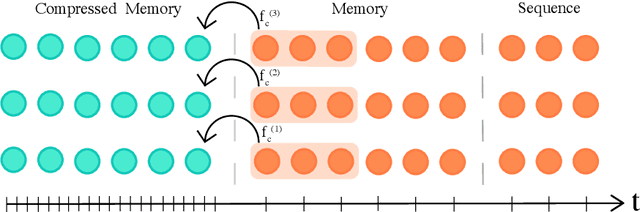
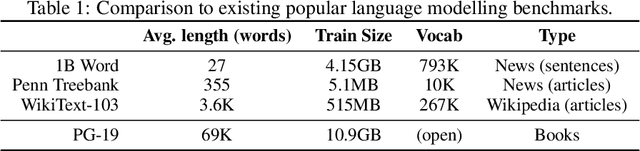
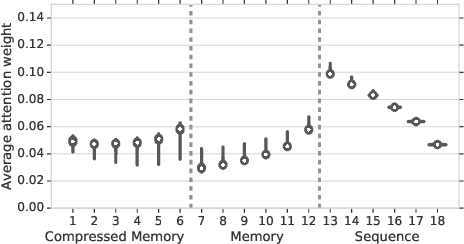
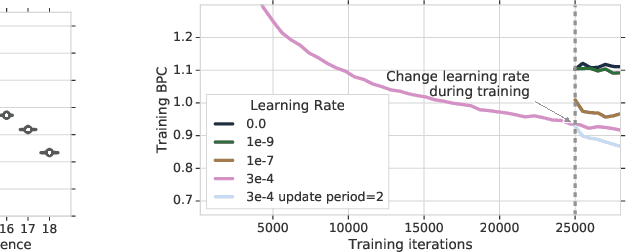
We present the Compressive Transformer, an attentive sequence model which compresses past memories for long-range sequence learning. We find the Compressive Transformer obtains state-of-the-art language modelling results in the WikiText-103 and Enwik8 benchmarks, achieving 17.1 ppl and 0.97 bpc respectively. We also find it can model high-frequency speech effectively and can be used as a memory mechanism for RL, demonstrated on an object matching task. To promote the domain of long-range sequence learning, we propose a new open-vocabulary language modelling benchmark derived from books, PG-19.
Stabilizing Transformers for Reinforcement Learning
Oct 13, 2019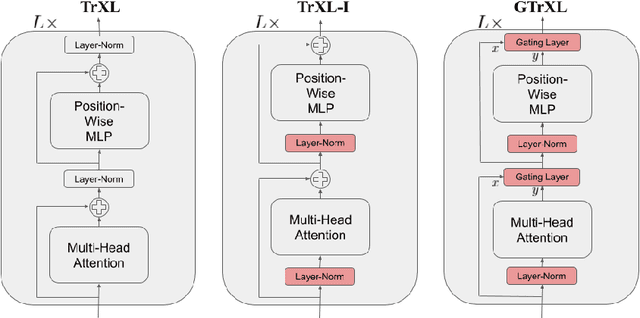
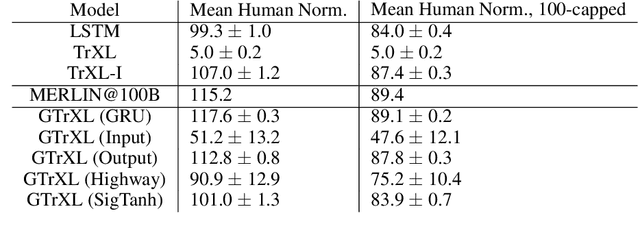
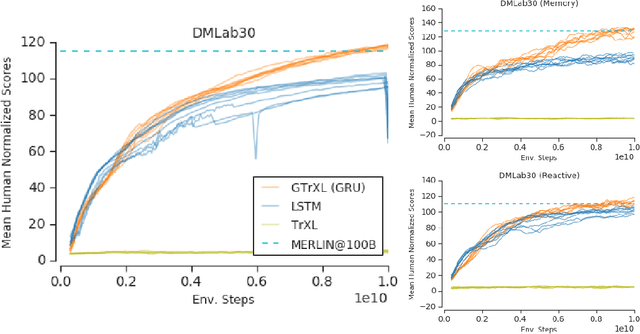
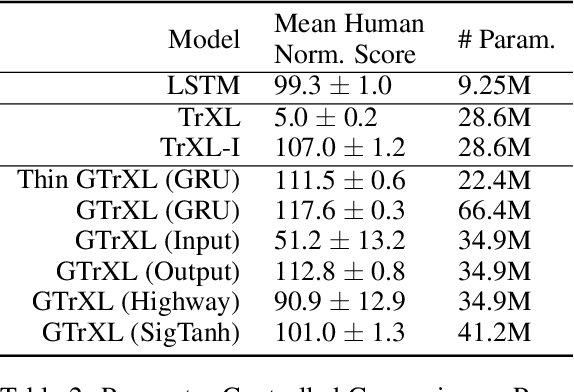
Owing to their ability to both effectively integrate information over long time horizons and scale to massive amounts of data, self-attention architectures have recently shown breakthrough success in natural language processing (NLP), achieving state-of-the-art results in domains such as language modeling and machine translation. Harnessing the transformer's ability to process long time horizons of information could provide a similar performance boost in partially observable reinforcement learning (RL) domains, but the large-scale transformers used in NLP have yet to be successfully applied to the RL setting. In this work we demonstrate that the standard transformer architecture is difficult to optimize, which was previously observed in the supervised learning setting but becomes especially pronounced with RL objectives. We propose architectural modifications that substantially improve the stability and learning speed of the original Transformer and XL variant. The proposed architecture, the Gated Transformer-XL (GTrXL), surpasses LSTMs on challenging memory environments and achieves state-of-the-art results on the multi-task DMLab-30 benchmark suite, exceeding the performance of an external memory architecture. We show that the GTrXL, trained using the same losses, has stability and performance that consistently matches or exceeds a competitive LSTM baseline, including on more reactive tasks where memory is less critical. GTrXL offers an easy-to-train, simple-to-implement but substantially more expressive architectural alternative to the standard multi-layer LSTM ubiquitously used for RL agents in partially observable environments.
Meta-learning of Sequential Strategies
May 08, 2019
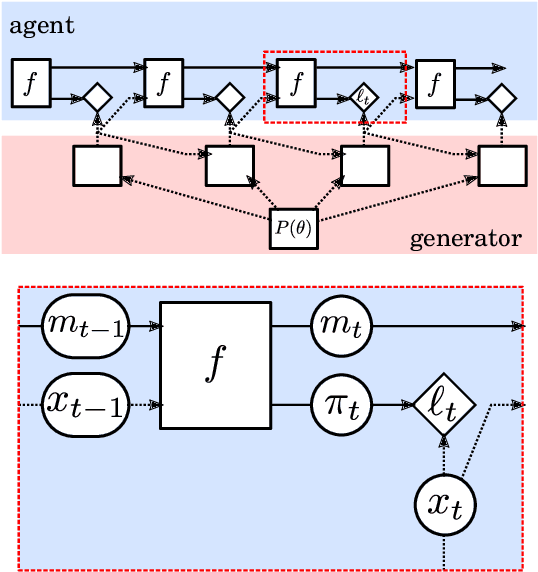
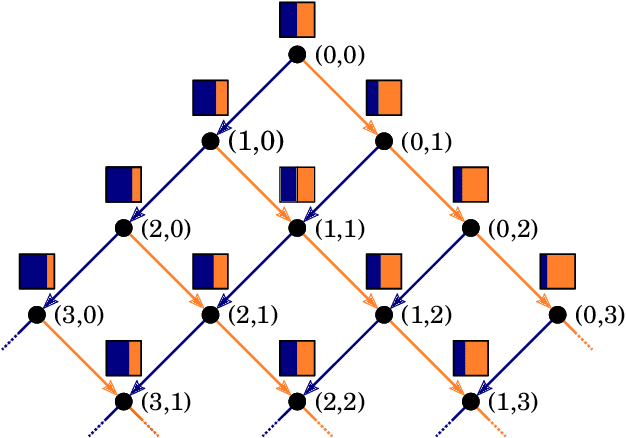
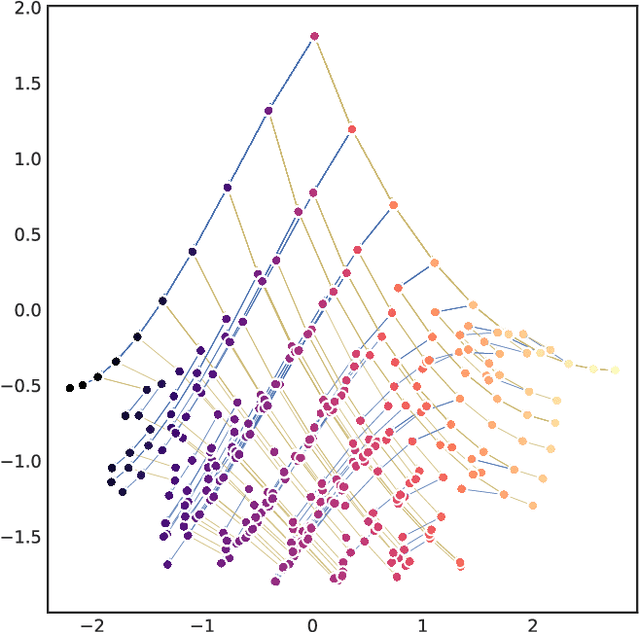
In this report we review memory-based meta-learning as a tool for building sample-efficient strategies that learn from past experience to adapt to any task within a target class. Our goal is to equip the reader with the conceptual foundations of this tool for building new, scalable agents that operate on broad domains. To do so, we present basic algorithmic templates for building near-optimal predictors and reinforcement learners which behave as if they had a probabilistic model that allowed them to efficiently exploit task structure. Furthermore, we recast memory-based meta-learning within a Bayesian framework, showing that the meta-learned strategies are near-optimal because they amortize Bayes-filtered data, where the adaptation is implemented in the memory dynamics as a state-machine of sufficient statistics. Essentially, memory-based meta-learning translates the hard problem of probabilistic sequential inference into a regression problem.
Information asymmetry in KL-regularized RL
May 03, 2019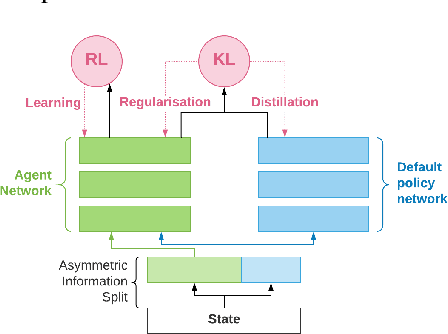

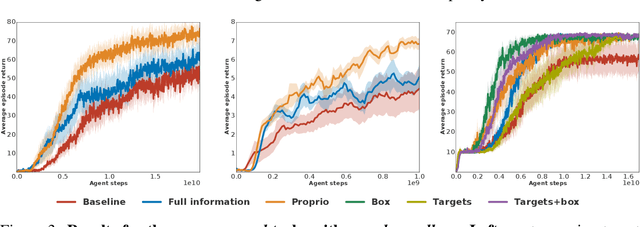
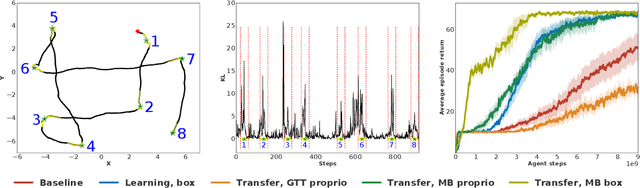
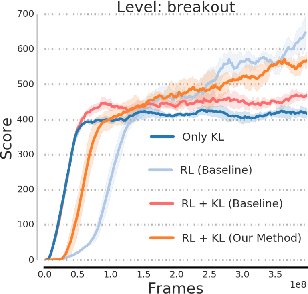
Many real world tasks exhibit rich structure that is repeated across different parts of the state space or in time. In this work we study the possibility of leveraging such repeated structure to speed up and regularize learning. We start from the KL regularized expected reward objective which introduces an additional component, a default policy. Instead of relying on a fixed default policy, we learn it from data. But crucially, we restrict the amount of information the default policy receives, forcing it to learn reusable behaviors that help the policy learn faster. We formalize this strategy and discuss connections to information bottleneck approaches and to the variational EM algorithm. We present empirical results in both discrete and continuous action domains and demonstrate that, for certain tasks, learning a default policy alongside the policy can significantly speed up and improve learning.
Distilling Policy Distillation
Feb 06, 2019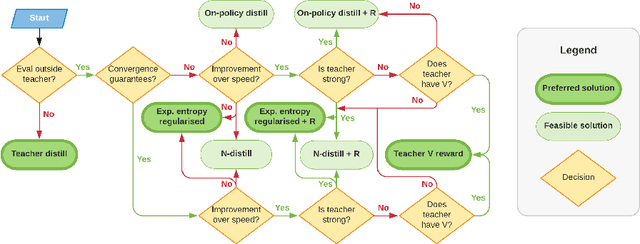



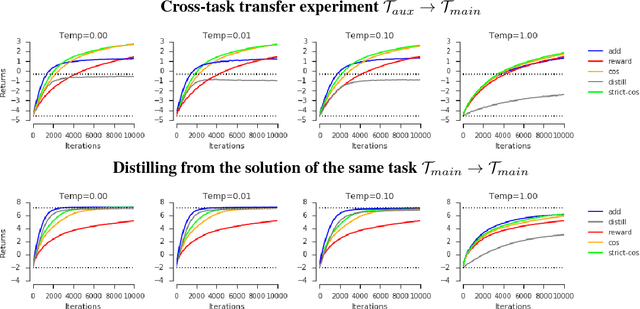
The transfer of knowledge from one policy to another is an important tool in Deep Reinforcement Learning. This process, referred to as distillation, has been used to great success, for example, by enhancing the optimisation of agents, leading to stronger performance faster, on harder domains [26, 32, 5, 8]. Despite the widespread use and conceptual simplicity of distillation, many different formulations are used in practice, and the subtle variations between them can often drastically change the performance and the resulting objective that is being optimised. In this work, we rigorously explore the entire landscape of policy distillation, comparing the motivations and strengths of each variant through theoretical and empirical analysis. Our results point to three distillation techniques, that are preferred depending on specifics of the task. Specifically a newly proposed expected entropy regularised distillation allows for quicker learning in a wide range of situations, while still guaranteeing convergence.
Adapting Auxiliary Losses Using Gradient Similarity
Dec 05, 2018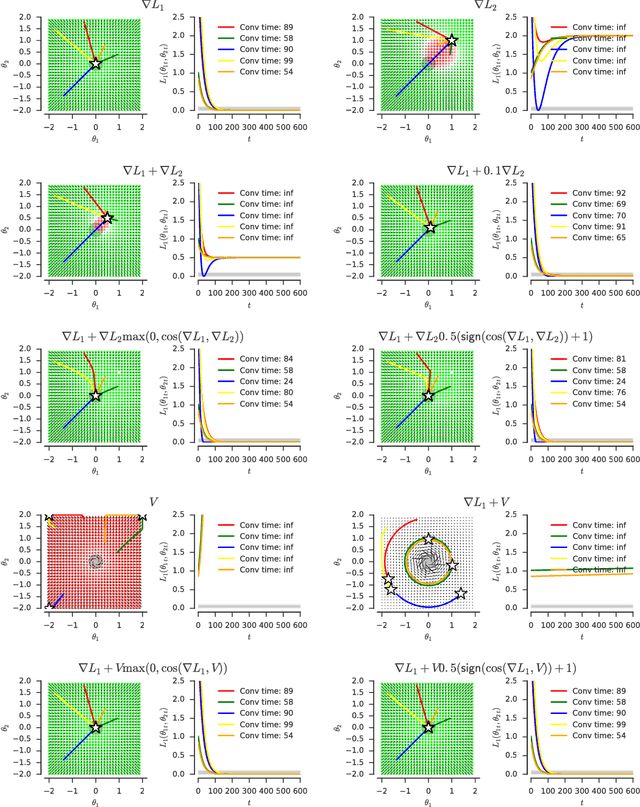
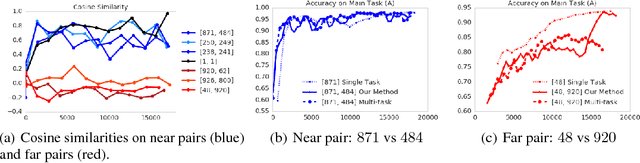
One approach to deal with the statistical inefficiency of neural networks is to rely on auxiliary losses that help to build useful representations. However, it is not always trivial to know if an auxiliary task will be helpful for the main task and when it could start hurting. We propose to use the cosine similarity between gradients of tasks as an adaptive weight to detect when an auxiliary loss is helpful to the main loss. We show that our approach is guaranteed to converge to critical points of the main task and demonstrate the practical usefulness of the proposed algorithm in a few domains: multi-task supervised learning on subsets of ImageNet, reinforcement learning on gridworld, and reinforcement learning on Atari games.
Been There, Done That: Meta-Learning with Episodic Recall
Jul 06, 2018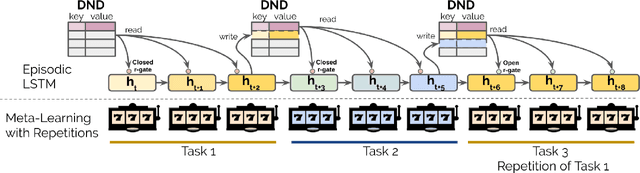
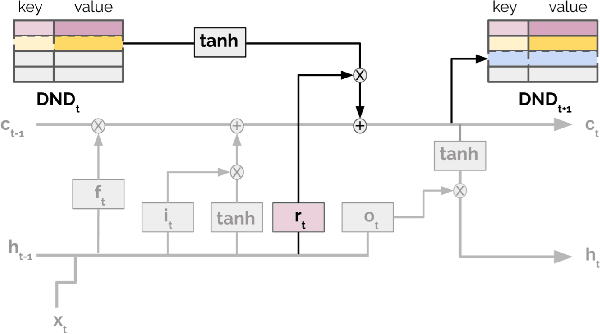
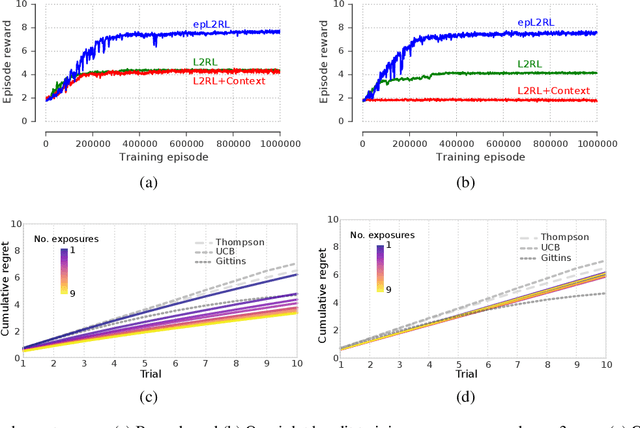
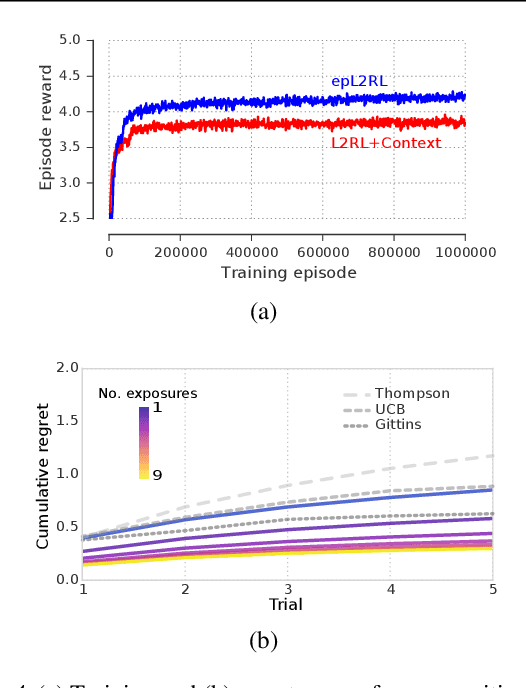
Meta-learning agents excel at rapidly learning new tasks from open-ended task distributions; yet, they forget what they learn about each task as soon as the next begins. When tasks reoccur - as they do in natural environments - metalearning agents must explore again instead of immediately exploiting previously discovered solutions. We propose a formalism for generating open-ended yet repetitious environments, then develop a meta-learning architecture for solving these environments. This architecture melds the standard LSTM working memory with a differentiable neural episodic memory. We explore the capabilities of agents with this episodic LSTM in five meta-learning environments with reoccurring tasks, ranging from bandits to navigation and stochastic sequential decision problems.