 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast Camera Image Denoising on Mobile GPUs with Deep Learning, Mobile AI 2021 Challenge: Report
May 17, 2021

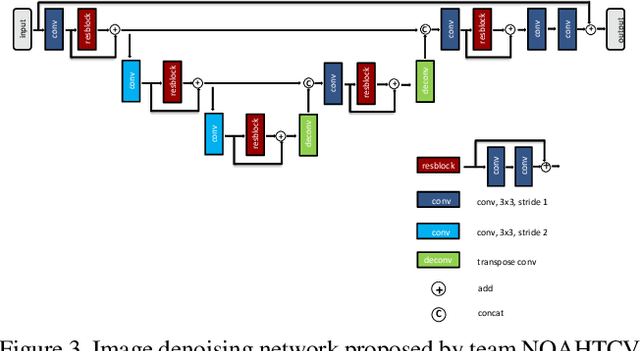
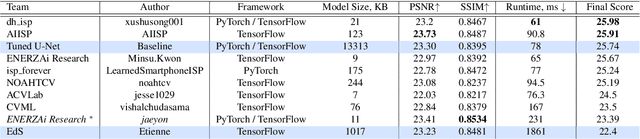
Image denoising is one of the most critical problems in mobile photo processing. While many solutions have been proposed for this task, they are usually working with synthetic data and are too computationally expensive to run on mobile devices. To address this problem, we introduce the first Mobile AI challenge, where the target is to develop an end-to-end deep learning-based image denoising solution that can demonstrate high efficiency on smartphone GPUs. For this, the participants were provided with a novel large-scale dataset consisting of noisy-clean image pairs captured in the wild. The runtime of all models was evaluated on the Samsung Exynos 2100 chipset with a powerful Mali GPU capable of accelerating floating-point and quantized neural networks. The proposed solutions are fully compatible with any mobile GPU and are capable of processing 480p resolution images under 40-80 ms while achieving high fidelity results. A detailed description of all models developed in the challenge is provided in this paper.
Learned Smartphone ISP on Mobile NPUs with Deep Learning, Mobile AI 2021 Challenge: Report
May 17, 2021
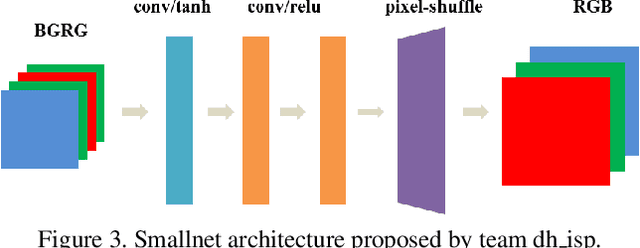
As the quality of mobile cameras starts to play a crucial role in modern smartphones, more and more attention is now being paid to ISP algorithms used to improve various perceptual aspects of mobile photos. In this Mobile AI challenge, the target was to develop an end-to-end deep learning-based image signal processing (ISP) pipeline that can replace classical hand-crafted ISPs and achieve nearly real-time performance on smartphone NPUs. For this, the participants were provided with a novel learned ISP dataset consisting of RAW-RGB image pairs captured with the Sony IMX586 Quad Bayer mobile sensor and a professional 102-megapixel medium format camera. The runtime of all models was evaluated on the MediaTek Dimensity 1000+ platform with a dedicated AI processing unit capable of accelerating both floating-point and quantized neural networks. The proposed solutions are fully compatible with the above NPU and are capable of processing Full HD photos under 60-100 milliseconds while achieving high fidelity results. A detailed description of all models developed in this challenge is provided in this paper.
NTIRE 2021 Challenge on Perceptual Image Quality Assessment
May 11, 2021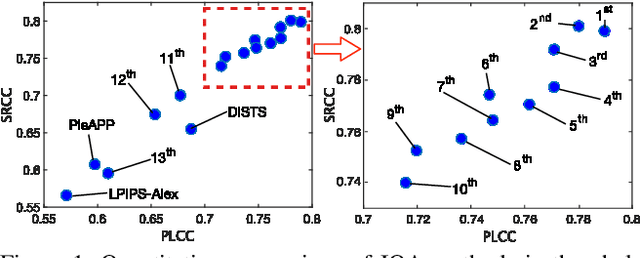
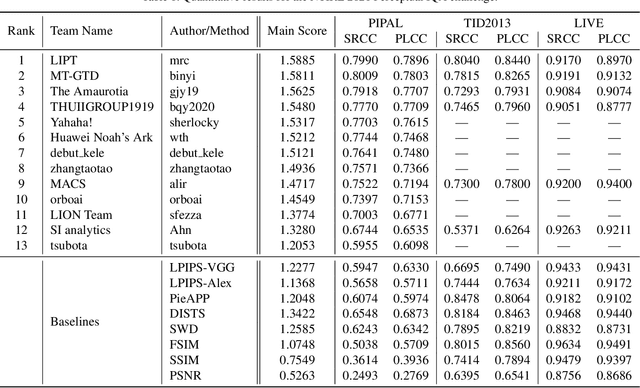

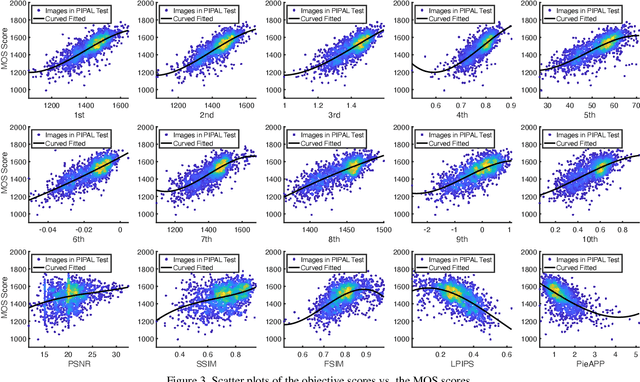
This paper reports on the NTIRE 2021 challenge on perceptual image quality assessment (IQA), held in conjunction with the New Trends in Image Restoration and Enhancement workshop (NTIRE) workshop at CVPR 2021. As a new type of image processing technology, perceptual image processing algorithms based on Generative Adversarial Networks (GAN) have produced images with more realistic textures. These output images have completely different characteristics from traditional distortions, thus pose a new challenge for IQA methods to evaluate their visual quality. In comparison with previous IQA challenges, the training and testing datasets in this challenge include the outputs of perceptual image processing algorithms and the corresponding subjective scores. Thus they can be used to develop and evaluate IQA methods on GAN-based distortions. The challenge has 270 registered participants in total. In the final testing stage, 13 participating teams submitted their models and fact sheets. Almost all of them have achieved much better results than existing IQA methods, while the winning method can demonstrate state-of-the-art performance.
NTIRE 2021 Challenge on Video Super-Resolution
May 10, 2021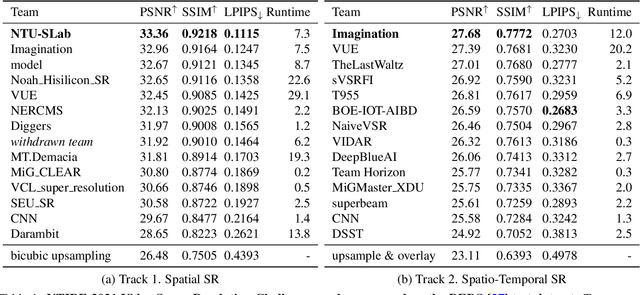


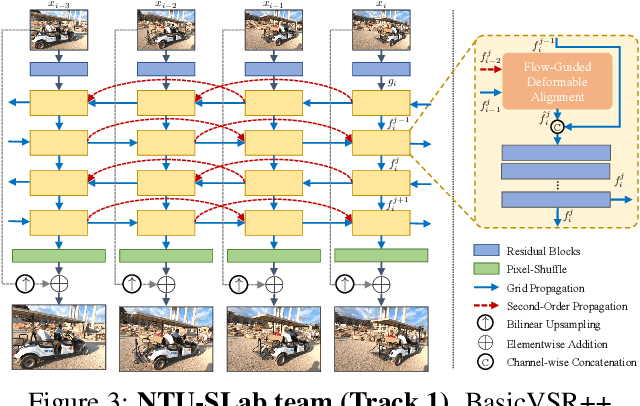
Super-Resolution (SR) is a fundamental computer vision task that aims to obtain a high-resolution clean image from the given low-resolution counterpart. This paper reviews the NTIRE 2021 Challenge on Video Super-Resolution. We present evaluation results from two competition tracks as well as the proposed solutions. Track 1 aims to develop conventional video SR methods focusing on the restoration quality. Track 2 assumes a more challenging environment with lower frame rates, casting spatio-temporal SR problem. In each competition, 247 and 223 participants have registered, respectively. During the final testing phase, 14 teams competed in each track to achieve state-of-the-art performance on video SR tasks.
NTIRE 2021 Challenge on Quality Enhancement of Compressed Video: Methods and Results
May 02, 2021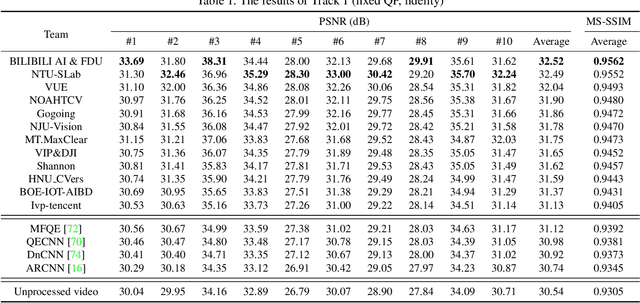
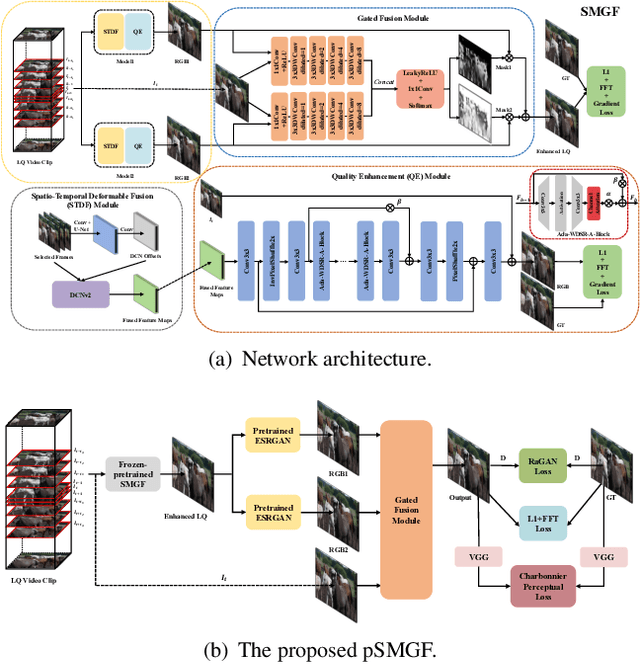
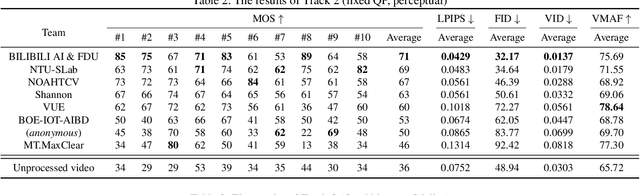
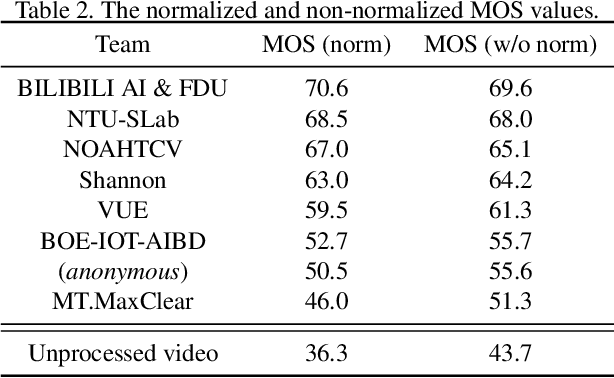
This paper reviews the first NTIRE challenge on quality enhancement of compressed video, with a focus on the proposed methods and results. In this challenge, the new Large-scale Diverse Video (LDV) dataset is employed. The challenge has three tracks. Tracks 1 and 2 aim at enhancing the videos compressed by HEVC at a fixed QP, while Track 3 is designed for enhancing the videos compressed by x265 at a fixed bit-rate. Besides, the quality enhancement of Tracks 1 and 3 targets at improving the fidelity (PSNR), and Track 2 targets at enhancing the perceptual quality. The three tracks totally attract 482 registrations. In the test phase, 12 teams, 8 teams and 11 teams submitted the final results of Tracks 1, 2 and 3, respectively. The proposed methods and solutions gauge the state-of-the-art of video quality enhancement. The homepage of the challenge: https://github.com/RenYang-home/NTIRE21_VEnh
NTIRE 2021 Challenge on Quality Enhancement of Compressed Video: Dataset and Study
May 02, 2021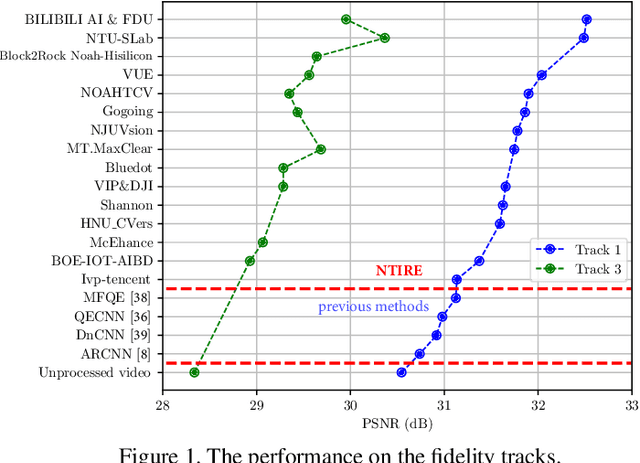
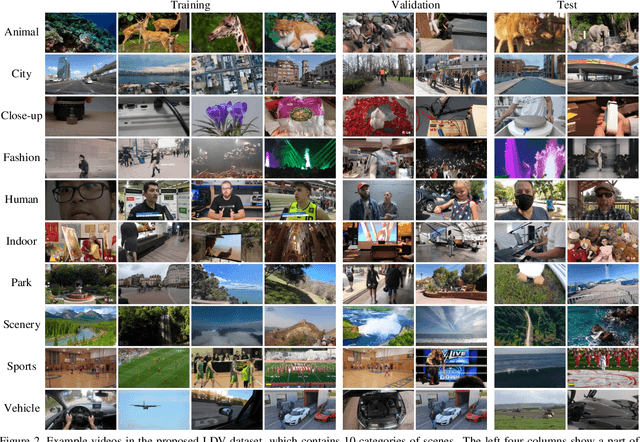
This paper introduces a novel dataset for video enhancement and studies the state-of-the-art methods of the NTIRE 2021 challenge on quality enhancement of compressed video. The challenge is the first NTIRE challenge in this direction, with three competitions, hundreds of participants and tens of proposed solutions. Our newly collected Large-scale Diverse Video (LDV) dataset is employed in the challenge. In our study, we analyze the proposed methods of the challenge and several methods in previous works on the proposed LDV dataset. We find that the NTIRE 2021 challenge advances the state-of-the-art of quality enhancement on compressed video. The proposed LDV dataset is publicly available at the homepage of the challenge: https://github.com/RenYang-home/NTIRE21_VEnh
NTIRE 2021 Challenge on Image Deblurring
Apr 30, 2021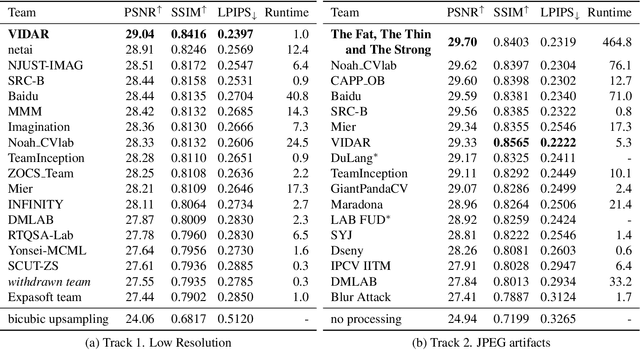


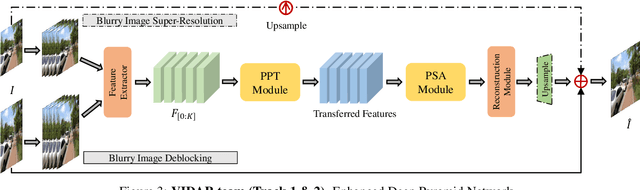
Motion blur is a common photography artifact in dynamic environments that typically comes jointly with the other types of degradation. This paper reviews the NTIRE 2021 Challenge on Image Deblurring. In this challenge report, we describe the challenge specifics and the evaluation results from the 2 competition tracks with the proposed solutions. While both the tracks aim to recover a high-quality clean image from a blurry image, different artifacts are jointly involved. In track 1, the blurry images are in a low resolution while track 2 images are compressed in JPEG format. In each competition, there were 338 and 238 registered participants and in the final testing phase, 18 and 17 teams competed. The winning methods demonstrate the state-of-the-art performance on the image deblurring task with the jointly combined artifacts.
NTIRE 2021 Depth Guided Image Relighting Challenge
Apr 27, 2021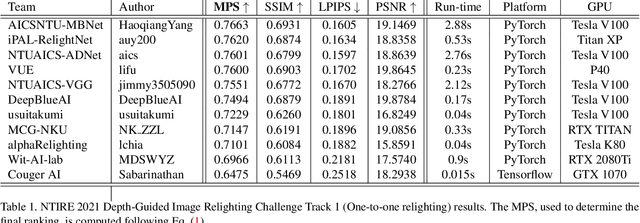

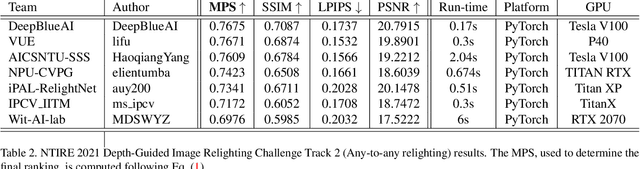

Image relighting is attracting increasing interest due to its various applications. From a research perspective, image relighting can be exploited to conduct both image normalization for domain adaptation, and also for data augmentation. It also has multiple direct uses for photo montage and aesthetic enhancement. In this paper, we review the NTIRE 2021 depth guided image relighting challenge. We rely on the VIDIT dataset for each of our two challenge tracks, including depth information. The first track is on one-to-one relighting where the goal is to transform the illumination setup of an input image (color temperature and light source position) to the target illumination setup. In the second track, the any-to-any relighting challenge, the objective is to transform the illumination settings of the input image to match those of another guide image, similar to style transfer. In both tracks, participants were given depth information about the captured scenes. We had nearly 250 registered participants, leading to 18 confirmed team submissions in the final competition stage. The competitions, methods, and final results are presented in this paper.
* Code and data available on https://github.com/majedelhelou/VIDIT
LocalViT: Bringing Locality to Vision Transformers
Apr 12, 2021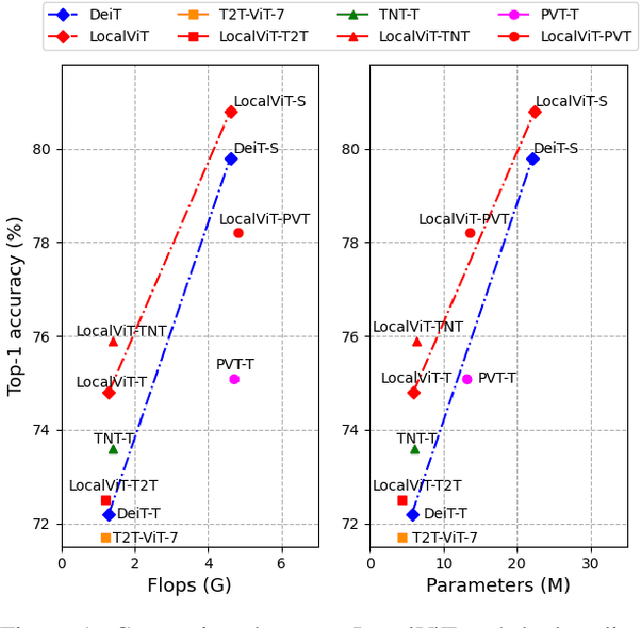
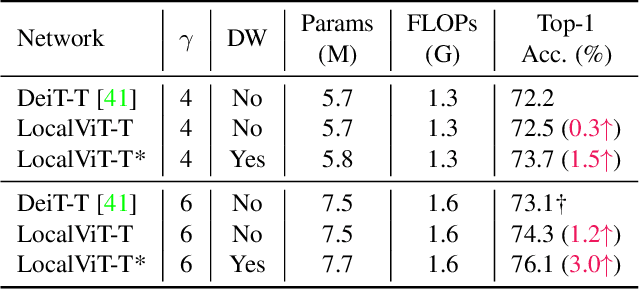
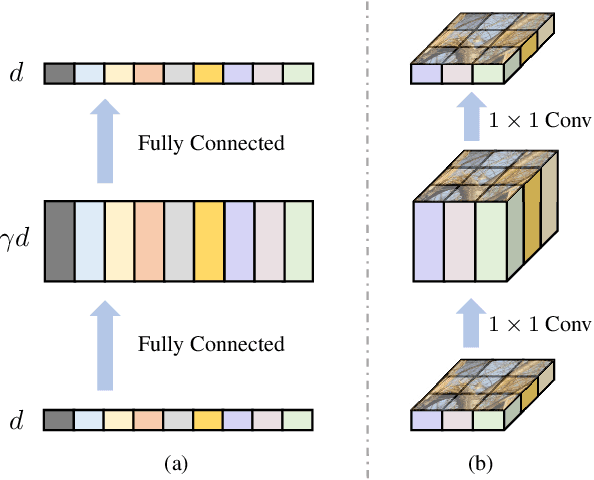
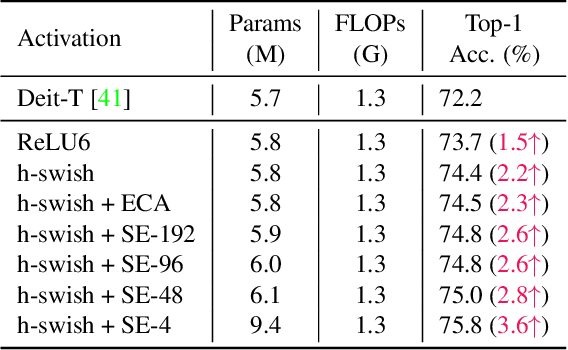
We study how to introduce locality mechanisms into vision transformers. The transformer network originates from machine translation and is particularly good at modelling long-range dependencies within a long sequence. Although the global interaction between the token embeddings could be well modelled by the self-attention mechanism of transformers, what is lacking a locality mechanism for information exchange within a local region. Yet, locality is essential for images since it pertains to structures like lines, edges, shapes, and even objects. We add locality to vision transformers by introducing depth-wise convolution into the feed-forward network. This seemingly simple solution is inspired by the comparison between feed-forward networks and inverted residual blocks. The importance of locality mechanisms is validated in two ways: 1) A wide range of design choices (activation function, layer placement, expansion ratio) are available for incorporating locality mechanisms and all proper choices can lead to a performance gain over the baseline, and 2) The same locality mechanism is successfully applied to 4 vision transformers, which shows the generalization of the locality concept. In particular, for ImageNet2012 classification, the locality-enhanced transformers outperform the baselines DeiT-T and PVT-T by 2.6\% and 3.1\% with a negligible increase in the number of parameters and computational effort. Code is available at \url{https://github.com/ofsoundof/LocalViT}.
Towards Efficient Graph Convolutional Networks for Point Cloud Handling
Apr 12, 2021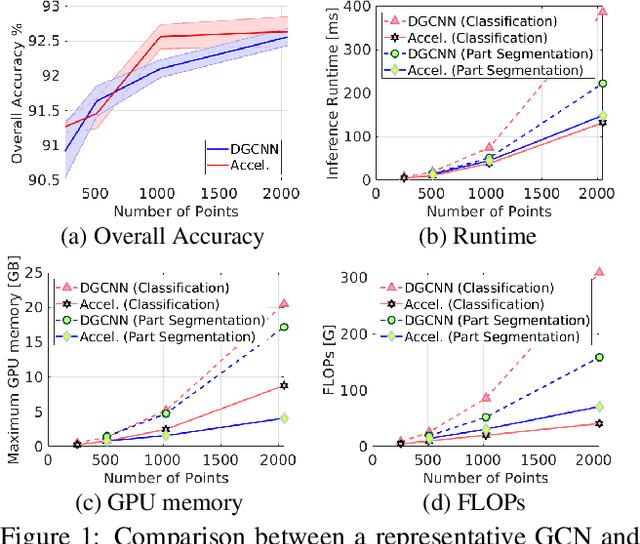
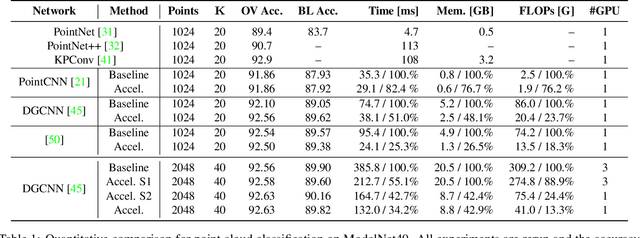
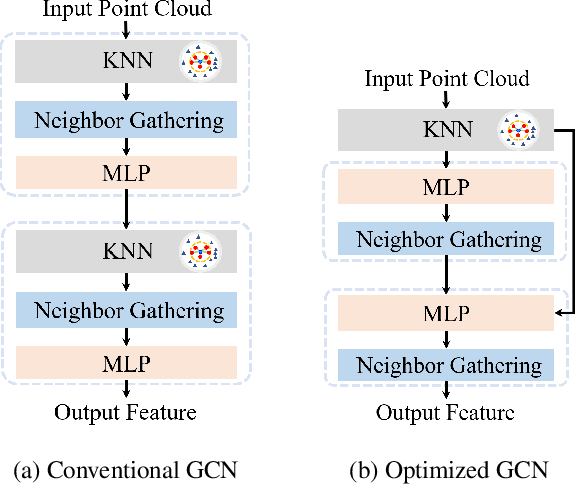

In this paper, we aim at improving the computational efficiency of graph convolutional networks (GCNs) for learning on point clouds. The basic graph convolution that is typically composed of a $K$-nearest neighbor (KNN) search and a multilayer perceptron (MLP) is examined. By mathematically analyzing the operations there, two findings to improve the efficiency of GCNs are obtained. (1) The local geometric structure information of 3D representations propagates smoothly across the GCN that relies on KNN search to gather neighborhood features. This motivates the simplification of multiple KNN searches in GCNs. (2) Shuffling the order of graph feature gathering and an MLP leads to equivalent or similar composite operations. Based on those findings, we optimize the computational procedure in GCNs. A series of experiments show that the optimized networks have reduced computational complexity, decreased memory consumption, and accelerated inference speed while maintaining comparable accuracy for learning on point clouds. Code will be available at \url{https://github.com/ofsoundof/EfficientGCN.git}.