 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLong-tailed Distribution Adaptation
Oct 06, 2021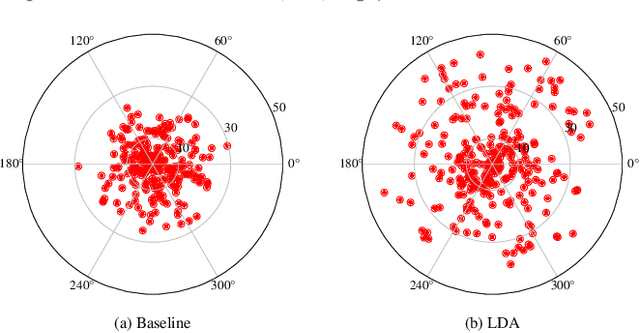
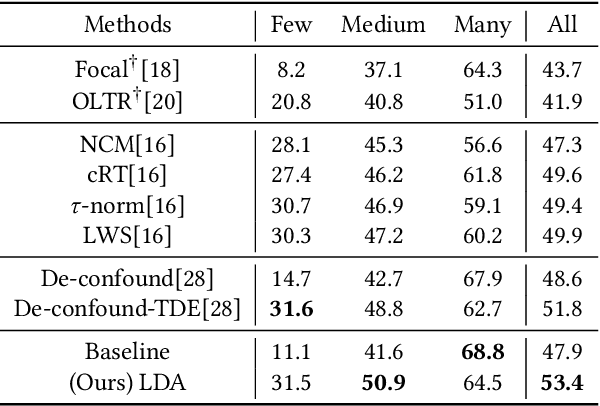
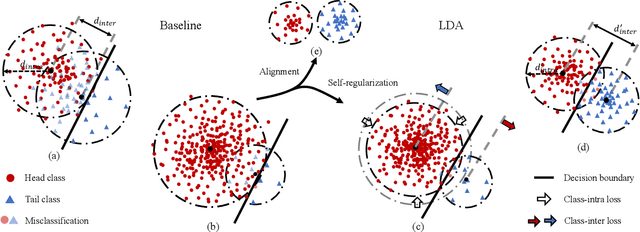
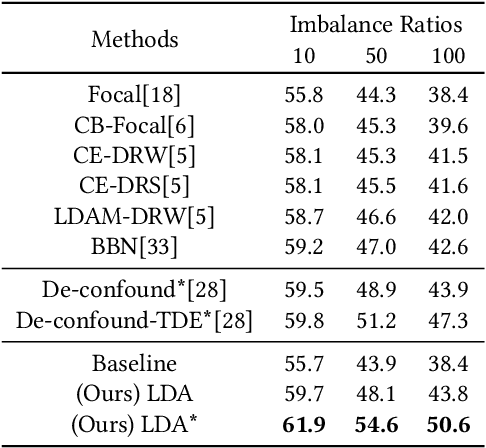
Recognizing images with long-tailed distributions remains a challenging problem while there lacks an interpretable mechanism to solve this problem. In this study, we formulate Long-tailed recognition as Domain Adaption (LDA), by modeling the long-tailed distribution as an unbalanced domain and the general distribution as a balanced domain. Within the balanced domain, we propose to slack the generalization error bound, which is defined upon the empirical risks of unbalanced and balanced domains and the divergence between them. We propose to jointly optimize empirical risks of the unbalanced and balanced domains and approximate their domain divergence by intra-class and inter-class distances, with the aim to adapt models trained on the long-tailed distribution to general distributions in an interpretable way. Experiments on benchmark datasets for image recognition, object detection, and instance segmentation validate that our LDA approach, beyond its interpretability, achieves state-of-the-art performance. Code is available at https://github.com/pengzhiliang/LDA.
GraFormer: Graph Convolution Transformer for 3D Pose Estimation
Sep 17, 2021Exploiting relations among 2D joints plays a crucial role yet remains semi-developed in 2D-to-3D pose estimation. To alleviate this issue, we propose GraFormer, a novel transformer architecture combined with graph convolution for 3D pose estimation. The proposed GraFormer comprises two repeatedly stacked core modules, GraAttention and ChebGConv block. GraAttention enables all 2D joints to interact in global receptive field without weakening the graph structure information of joints, which introduces vital features for later modules. Unlike vanilla graph convolutions that only model the apparent relationship of joints, ChebGConv block enables 2D joints to interact in the high-order sphere, which formulates their hidden implicit relations. We empirically show the superiority of GraFormer through conducting extensive experiments across popular benchmarks. Specifically, GraFormer outperforms state of the art on Human3.6M dataset while using 18$\%$ parameters. The code is available at https://github.com/Graformer/GraFormer .
Prioritized Subnet Sampling for Resource-Adaptive Supernet Training
Sep 12, 2021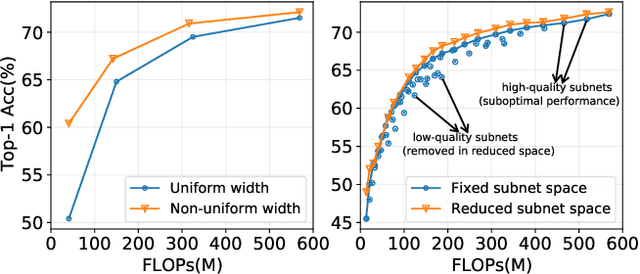
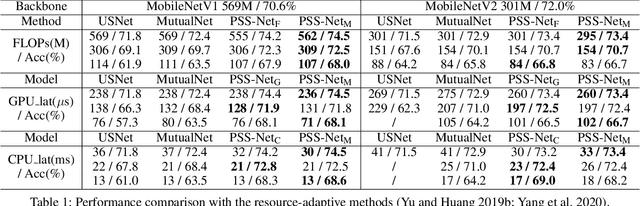
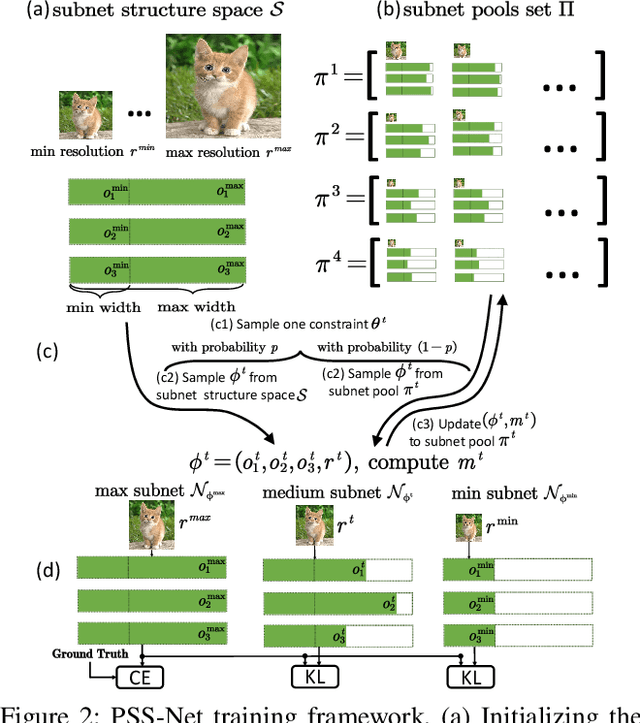
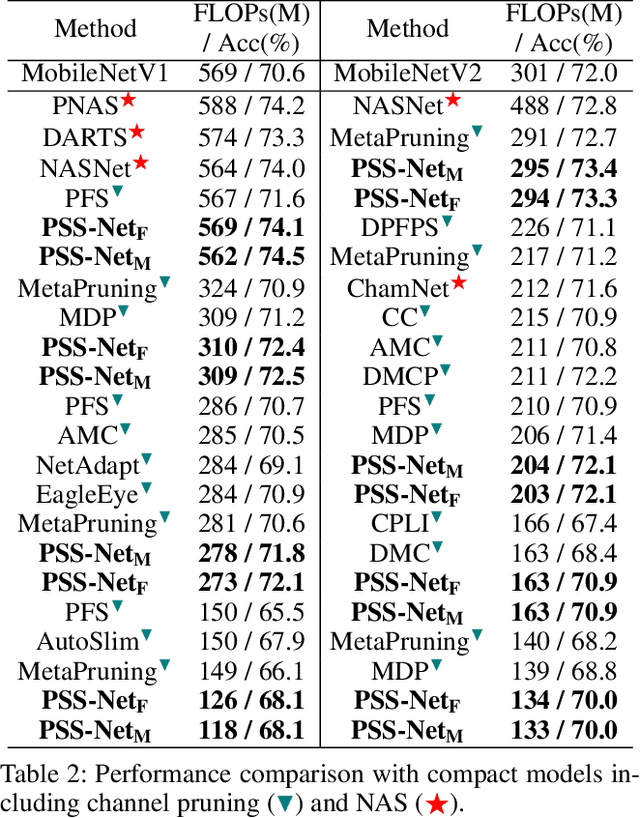
A resource-adaptive supernet adjusts its subnets for inference to fit the dynamically available resources. In this paper, we propose Prioritized Subnet Sampling to train a resource-adaptive supernet, termed PSS-Net. We maintain multiple subnet pools, each of which stores the information of substantial subnets with similar resource consumption. Considering a resource constraint, subnets conditioned on this resource constraint are sampled from a pre-defined subnet structure space and high-quality ones will be inserted into the corresponding subnet pool. Then, the sampling will gradually be prone to sampling subnets from the subnet pools. Moreover, the one with a better performance metric is assigned with higher priority to train our PSS-Net, if sampling is from a subnet pool. At the end of training, our PSS-Net retains the best subnet in each pool to entitle a fast switch of high-quality subnets for inference when the available resources vary. Experiments on ImageNet using MobileNetV1/V2 show that our PSS-Net can well outperform state-of-the-art resource-adaptive supernets. Our project is at https://github.com/chenbong/PSS-Net.
Adversarial Reinforced Instruction Attacker for Robust Vision-Language Navigation
Jul 23, 2021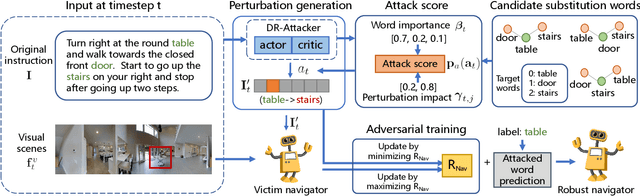
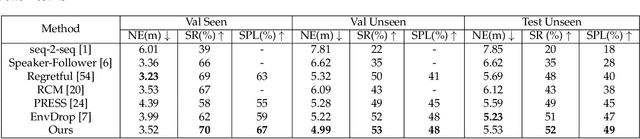
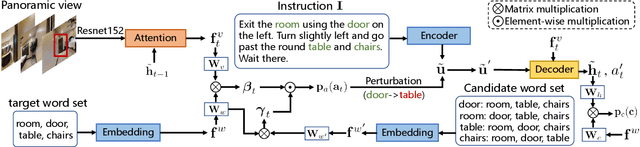

Language instruction plays an essential role in the natural language grounded navigation tasks. However, navigators trained with limited human-annotated instructions may have difficulties in accurately capturing key information from the complicated instruction at different timesteps, leading to poor navigation performance. In this paper, we exploit to train a more robust navigator which is capable of dynamically extracting crucial factors from the long instruction, by using an adversarial attacking paradigm. Specifically, we propose a Dynamic Reinforced Instruction Attacker (DR-Attacker), which learns to mislead the navigator to move to the wrong target by destroying the most instructive information in instructions at different timesteps. By formulating the perturbation generation as a Markov Decision Process, DR-Attacker is optimized by the reinforcement learning algorithm to generate perturbed instructions sequentially during the navigation, according to a learnable attack score. Then, the perturbed instructions, which serve as hard samples, are used for improving the robustness of the navigator with an effective adversarial training strategy and an auxiliary self-supervised reasoning task. Experimental results on both Vision-and-Language Navigation (VLN) and Navigation from Dialog History (NDH) tasks show the superiority of our proposed method over state-of-the-art methods. Moreover, the visualization analysis shows the effectiveness of the proposed DR-Attacker, which can successfully attack crucial information in the instructions at different timesteps. Code is available at https://github.com/expectorlin/DR-Attacker.
* Accepted by TPAMI 2021
Group Sampling for Unsupervised Person Re-identification
Jul 07, 2021
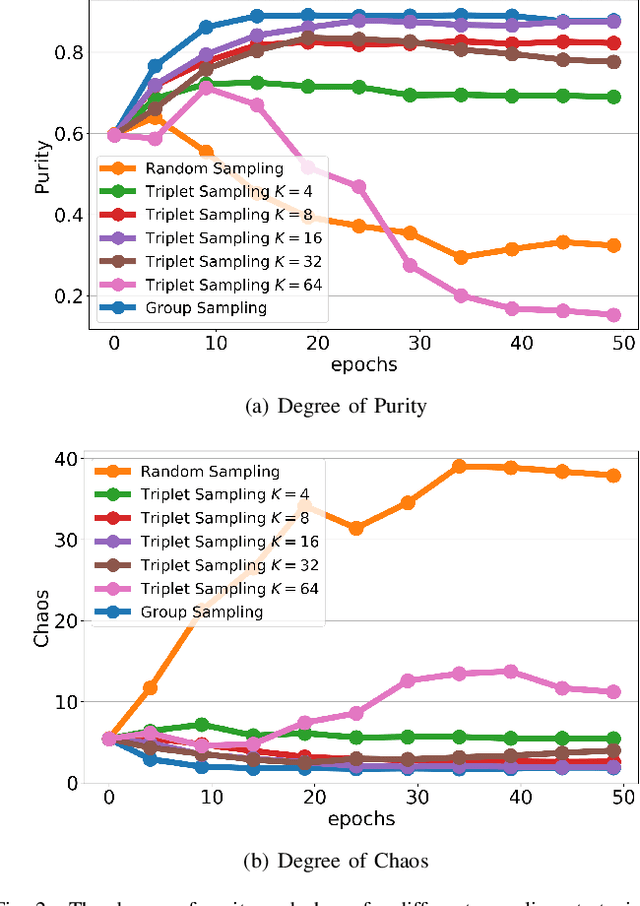
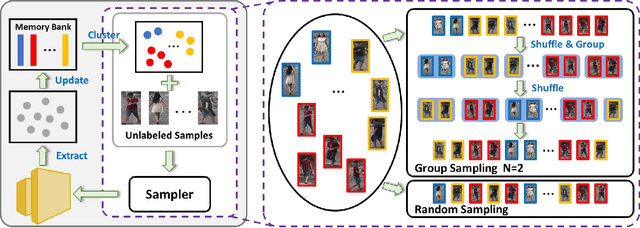
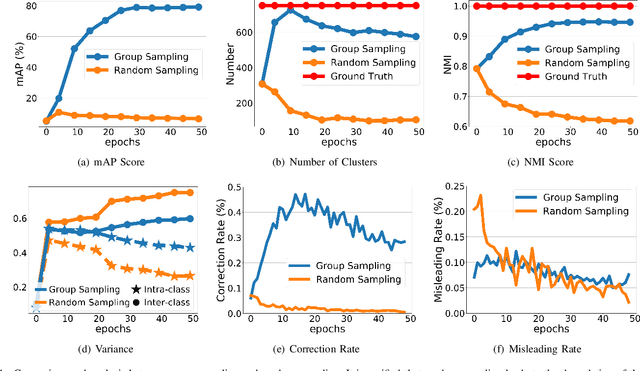
Unsupervised person re-identification (re-ID) remains a challenging task, where the classifier and feature representation could be easily misled by the noisy pseudo labels towards deteriorated over-fitting. In this paper, we propose a simple yet effective approach, termed Group Sampling, to alleviate the negative impact of noisy pseudo labels within unsupervised person re-ID models. The idea behind Group Sampling is that it can gather a group of samples from the same class in the same mini-batch, such that the model is trained upon group normalized samples while alleviating the effect of a single sample. Group sampling updates the pipeline of pseudo label generation by guaranteeing the samples to be better divided into the correct classes. Group Sampling regularizes classifier training and representation learning, leading to the statistical stability of feature representation in a progressive fashion. Qualitative and quantitative experiments on Market-1501, DukeMTMC-reID, and MSMT17 show that Grouping Sampling improves the state-of-the-arts by up to 2.2%~6.1%. Code is available at https://github.com/wavinflaghxm/GroupSampling.
Cogradient Descent for Dependable Learning
Jun 20, 2021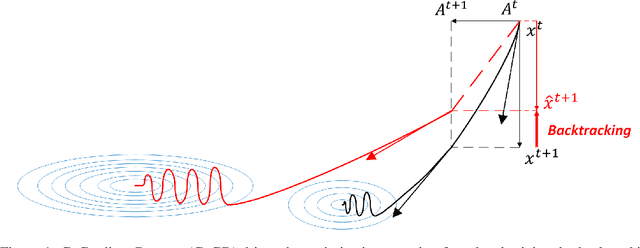
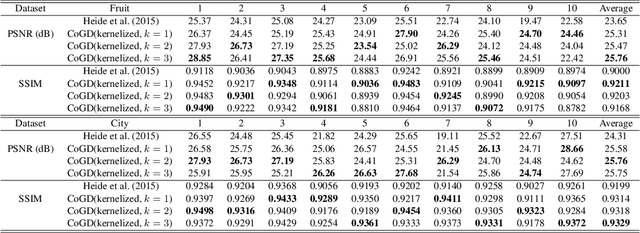
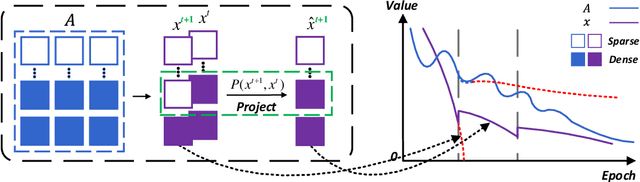
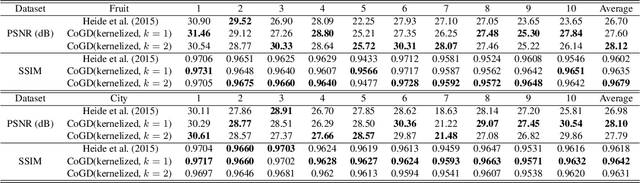
Conventional gradient descent methods compute the gradients for multiple variables through the partial derivative. Treating the coupled variables independently while ignoring the interaction, however, leads to an insufficient optimization for bilinear models. In this paper, we propose a dependable learning based on Cogradient Descent (CoGD) algorithm to address the bilinear optimization problem, providing a systematic way to coordinate the gradients of coupling variables based on a kernelized projection function. CoGD is introduced to solve bilinear problems when one variable is with sparsity constraint, as often occurs in modern learning paradigms. CoGD can also be used to decompose the association of features and weights, which further generalizes our method to better train convolutional neural networks (CNNs) and improve the model capacity. CoGD is applied in representative bilinear problems, including image reconstruction, image inpainting, network pruning and CNN training. Extensive experiments show that CoGD improves the state-of-the-arts by significant margins. Code is available at {https://github.com/bczhangbczhang/CoGD}.
Anti-aliasing Semantic Reconstruction for Few-Shot Semantic Segmentation
Jun 01, 2021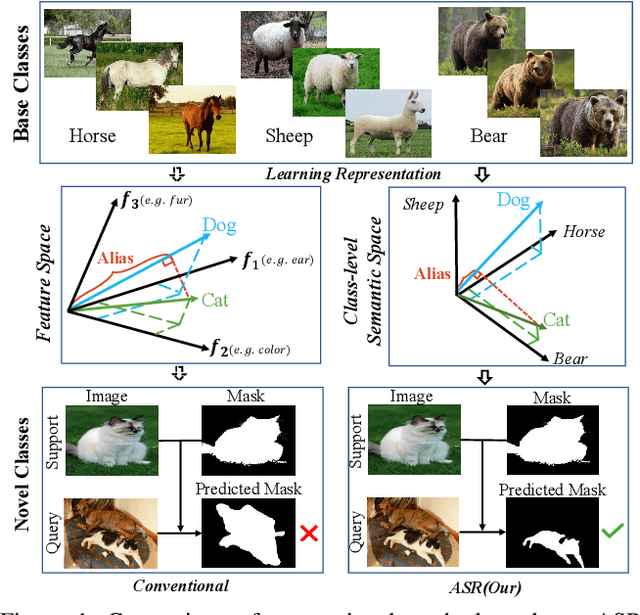
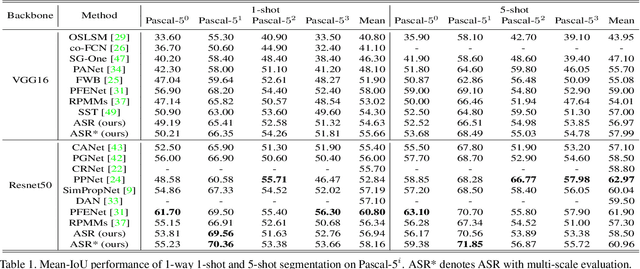
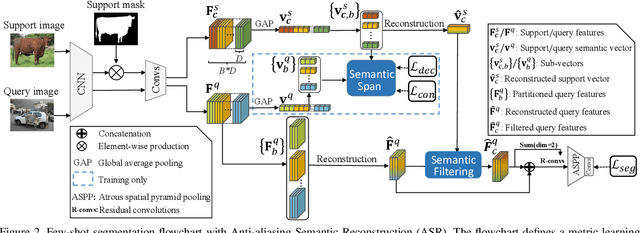
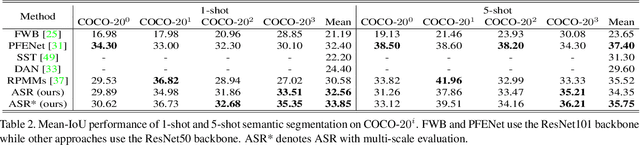
Encouraging progress in few-shot semantic segmentation has been made by leveraging features learned upon base classes with sufficient training data to represent novel classes with few-shot examples. However, this feature sharing mechanism inevitably causes semantic aliasing between novel classes when they have similar compositions of semantic concepts. In this paper, we reformulate few-shot segmentation as a semantic reconstruction problem, and convert base class features into a series of basis vectors which span a class-level semantic space for novel class reconstruction. By introducing contrastive loss, we maximize the orthogonality of basis vectors while minimizing semantic aliasing between classes. Within the reconstructed representation space, we further suppress interference from other classes by projecting query features to the support vector for precise semantic activation. Our proposed approach, referred to as anti-aliasing semantic reconstruction (ASR), provides a systematic yet interpretable solution for few-shot learning problems. Extensive experiments on PASCAL VOC and MS COCO datasets show that ASR achieves strong results compared with the prior works.
Towards Compact CNNs via Collaborative Compression
May 24, 2021
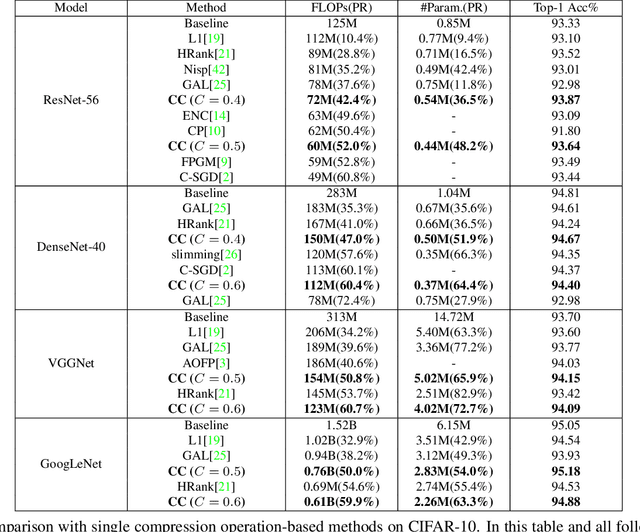
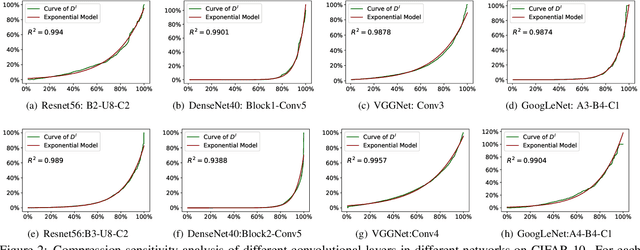
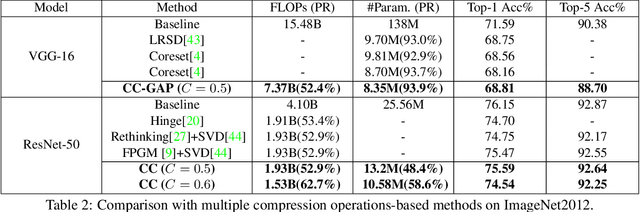
Channel pruning and tensor decomposition have received extensive attention in convolutional neural network compression. However, these two techniques are traditionally deployed in an isolated manner, leading to significant accuracy drop when pursuing high compression rates. In this paper, we propose a Collaborative Compression (CC) scheme, which joints channel pruning and tensor decomposition to compress CNN models by simultaneously learning the model sparsity and low-rankness. Specifically, we first investigate the compression sensitivity of each layer in the network, and then propose a Global Compression Rate Optimization that transforms the decision problem of compression rate into an optimization problem. After that, we propose multi-step heuristic compression to remove redundant compression units step-by-step, which fully considers the effect of the remaining compression space (i.e., unremoved compression units). Our method demonstrates superior performance gains over previous ones on various datasets and backbone architectures. For example, we achieve 52.9% FLOPs reduction by removing 48.4% parameters on ResNet-50 with only a Top-1 accuracy drop of 0.56% on ImageNet 2012.
Conformer: Local Features Coupling Global Representations for Visual Recognition
May 09, 2021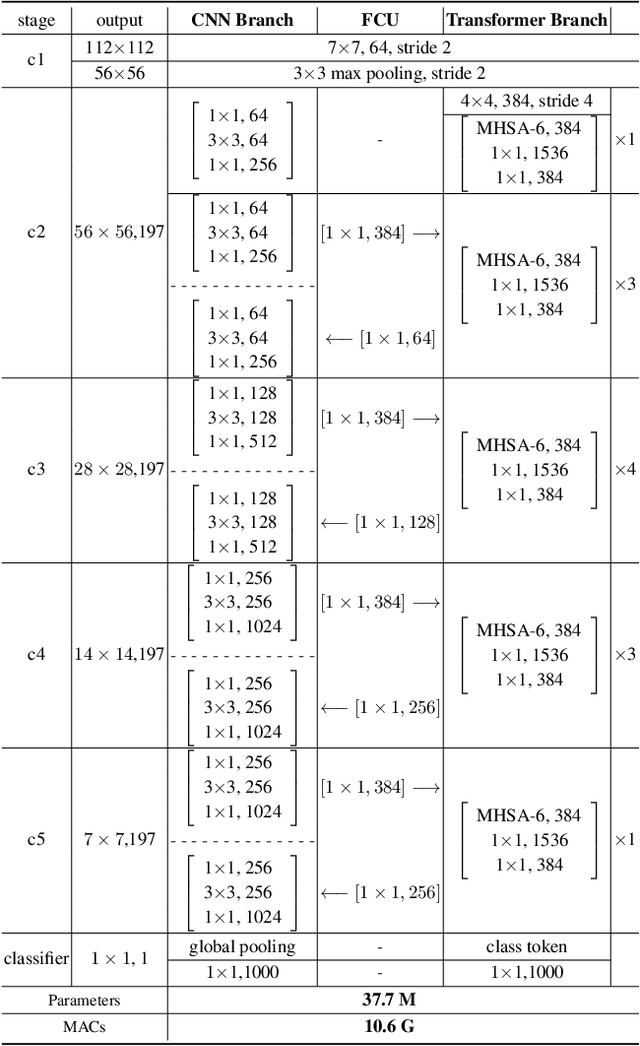
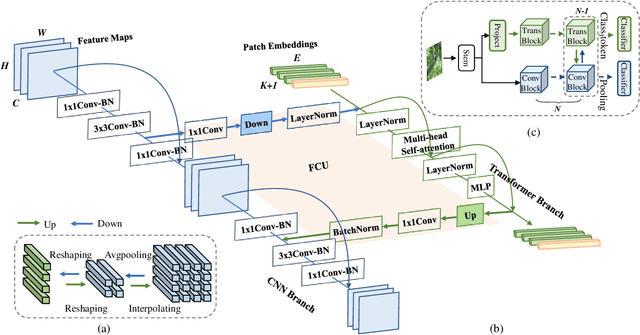
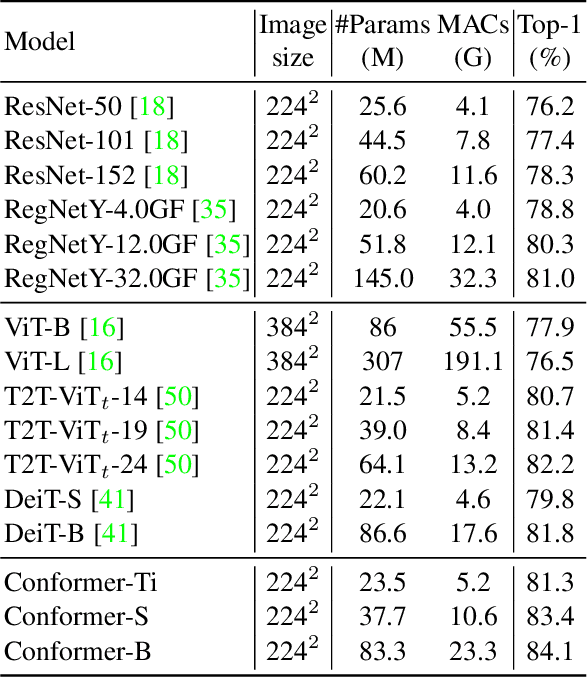
Within Convolutional Neural Network (CNN), the convolution operations are good at extracting local features but experience difficulty to capture global representations. Within visual transformer, the cascaded self-attention modules can capture long-distance feature dependencies but unfortunately deteriorate local feature details. In this paper, we propose a hybrid network structure, termed Conformer, to take advantage of convolutional operations and self-attention mechanisms for enhanced representation learning. Conformer roots in the Feature Coupling Unit (FCU), which fuses local features and global representations under different resolutions in an interactive fashion. Conformer adopts a concurrent structure so that local features and global representations are retained to the maximum extent. Experiments show that Conformer, under the comparable parameter complexity, outperforms the visual transformer (DeiT-B) by 2.3% on ImageNet. On MSCOCO, it outperforms ResNet-101 by 3.7% and 3.6% mAPs for object detection and instance segmentation, respectively, demonstrating the great potential to be a general backbone network. Code is available at https://github.com/pengzhiliang/Conformer.
Multiple instance active learning for object detection
Apr 06, 2021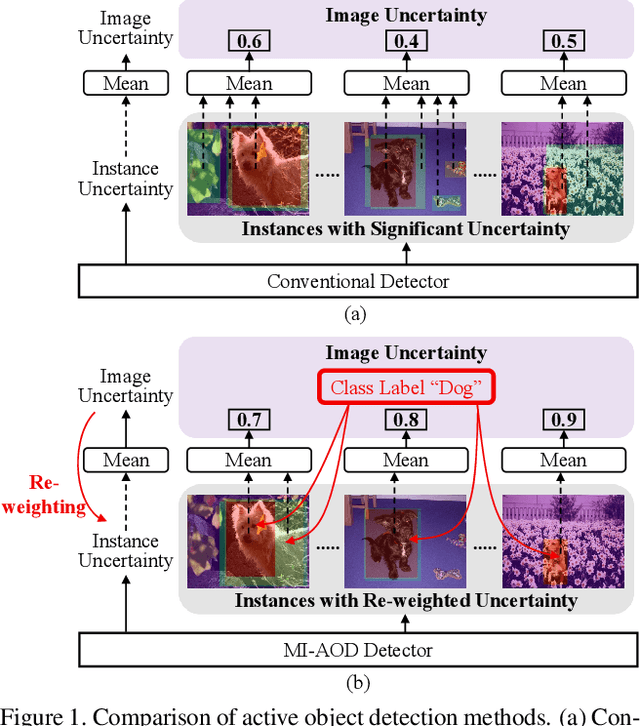
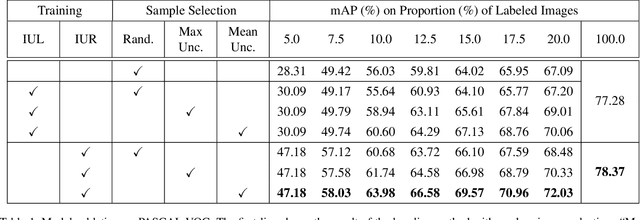
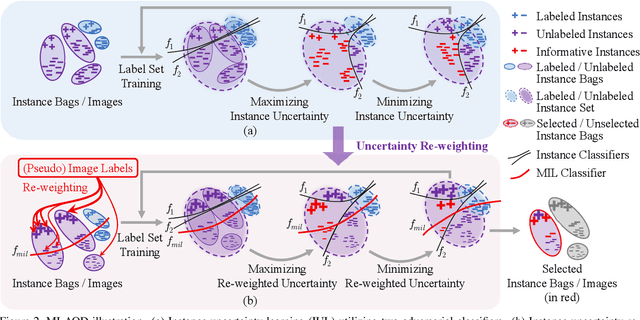
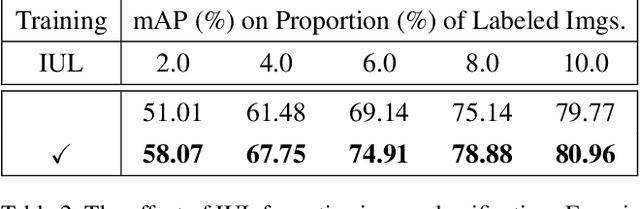
Despite the substantial progress of active learning for image recognition, there still lacks an instance-level active learning method specified for object detection. In this paper, we propose Multiple Instance Active Object Detection (MI-AOD), to select the most informative images for detector training by observing instance-level uncertainty. MI-AOD defines an instance uncertainty learning module, which leverages the discrepancy of two adversarial instance classifiers trained on the labeled set to predict instance uncertainty of the unlabeled set. MI-AOD treats unlabeled images as instance bags and feature anchors in images as instances, and estimates the image uncertainty by re-weighting instances in a multiple instance learning (MIL) fashion. Iterative instance uncertainty learning and re-weighting facilitate suppressing noisy instances, toward bridging the gap between instance uncertainty and image-level uncertainty. Experiments validate that MI-AOD sets a solid baseline for instance-level active learning. On commonly used object detection datasets, MI-AOD outperforms state-of-the-art methods with significant margins, particularly when the labeled sets are small. Code is available at https://github.com/yuantn/MI-AOD.