 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeK-Order Graph-oriented Transformer with GraAttention for 3D Pose and Shape Estimation
Aug 24, 2022
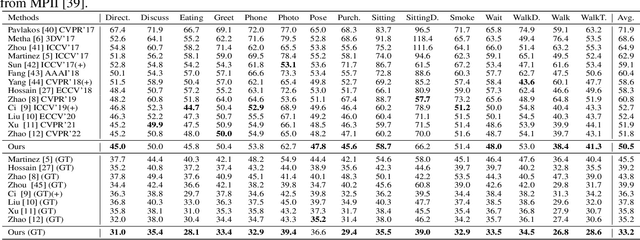
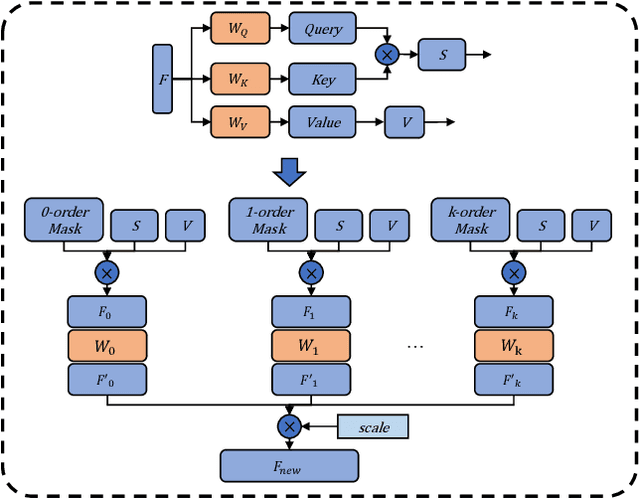

We propose a novel attention-based 2D-to-3D pose estimation network for graph-structured data, named KOG-Transformer, and a 3D pose-to-shape estimation network for hand data, named GASE-Net. Previous 3D pose estimation methods have focused on various modifications to the graph convolution kernel, such as abandoning weight sharing or increasing the receptive field. Some of these methods employ attention-based non-local modules as auxiliary modules. In order to better model the relationship between nodes in graph-structured data and fuse the information of different neighbor nodes in a differentiated way, we make targeted modifications to the attention module and propose two modules designed for graph-structured data, graph relative positional encoding multi-head self-attention (GR-MSA) and K-order graph-oriented multi-head self-attention (KOG-MSA). By stacking GR-MSA and KOG-MSA, we propose a novel network KOG-Transformer for 2D-to-3D pose estimation. Furthermore, we propose a network for shape estimation on hand data, called GraAttention shape estimation network (GASE-Net), which takes a 3D pose as input and gradually models the shape of the hand from sparse to dense. We have empirically shown the superiority of KOG-Transformer through extensive experiments. Experimental results show that KOG-Transformer significantly outperforms the previous state-of-the-art methods on the benchmark dataset Human3.6M. We evaluate the effect of GASE-Net on two public available hand datasets, ObMan and InterHand2.6M. GASE-Net can predict the corresponding shape for input pose with strong generalization ability.
GraFormer: Graph Convolution Transformer for 3D Pose Estimation
Sep 17, 2021Exploiting relations among 2D joints plays a crucial role yet remains semi-developed in 2D-to-3D pose estimation. To alleviate this issue, we propose GraFormer, a novel transformer architecture combined with graph convolution for 3D pose estimation. The proposed GraFormer comprises two repeatedly stacked core modules, GraAttention and ChebGConv block. GraAttention enables all 2D joints to interact in global receptive field without weakening the graph structure information of joints, which introduces vital features for later modules. Unlike vanilla graph convolutions that only model the apparent relationship of joints, ChebGConv block enables 2D joints to interact in the high-order sphere, which formulates their hidden implicit relations. We empirically show the superiority of GraFormer through conducting extensive experiments across popular benchmarks. Specifically, GraFormer outperforms state of the art on Human3.6M dataset while using 18$\%$ parameters. The code is available at https://github.com/Graformer/GraFormer .