 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePartial Fairness Awareness: Belief-Guided Strategic Mechanism for Strategic Agents
May 30, 2026Strategic machine learning investigates scenarios where agents manipulate their features to receive favorable decisions from predictive models. To address fairness concerns intrinsic to strategic classification, recent work has introduced group-specific fairness constraints. However, current fairness-aware approaches face a fundamental dilemma in the issue of fairness exposure: making these constraints public enables strategic manipulation and can lead to fairness reversal, while keeping them hidden may reduce social welfare and discourage genuine improvement. To fill this gap, we subsequently propose the problem of partial fairness awareness (PFA), as our theoretical analysis informs that such a dilemma can be mitigated by releasing the candidate set of fairness constraints and concealing the grounding constraint. To be specific, we introduce a belief-guided strategic mechanism, wherein agents iteratively interact with the decision system and maintain a belief distribution over the candidate set of fairness constraints. This belief-guided process enables agents, through iterative interaction and feedback, to update their belief distribution over the candidate set, thereby gradually aligning their belief with the grounding fairness constraint employed by the system. Extensive experiments on real-world and synthetic datasets demonstrate that PFA achieves lower group fairness gaps, higher acceptance of truly qualified individuals, and more stable outcomes compared to fully public or private fairness regimes.
Detecting Unobserved Confounders: A Kernelized Regression Approach
Jan 01, 2026Detecting unobserved confounders is crucial for reliable causal inference in observational studies. Existing methods require either linearity assumptions or multiple heterogeneous environments, limiting applicability to nonlinear single-environment settings. To bridge this gap, we propose Kernel Regression Confounder Detection (KRCD), a novel method for detecting unobserved confounding in nonlinear observational data under single-environment conditions. KRCD leverages reproducing kernel Hilbert spaces to model complex dependencies. By comparing standard and higherorder kernel regressions, we derive a test statistic whose significant deviation from zero indicates unobserved confounding. Theoretically, we prove two key results: First, in infinite samples, regression coefficients coincide if and only if no unobserved confounders exist. Second, finite-sample differences converge to zero-mean Gaussian distributions with tractable variance. Extensive experiments on synthetic benchmarks and the Twins dataset demonstrate that KRCD not only outperforms existing baselines but also achieves superior computational efficiency.
Conformer: Local Features Coupling Global Representations for Visual Recognition
May 09, 2021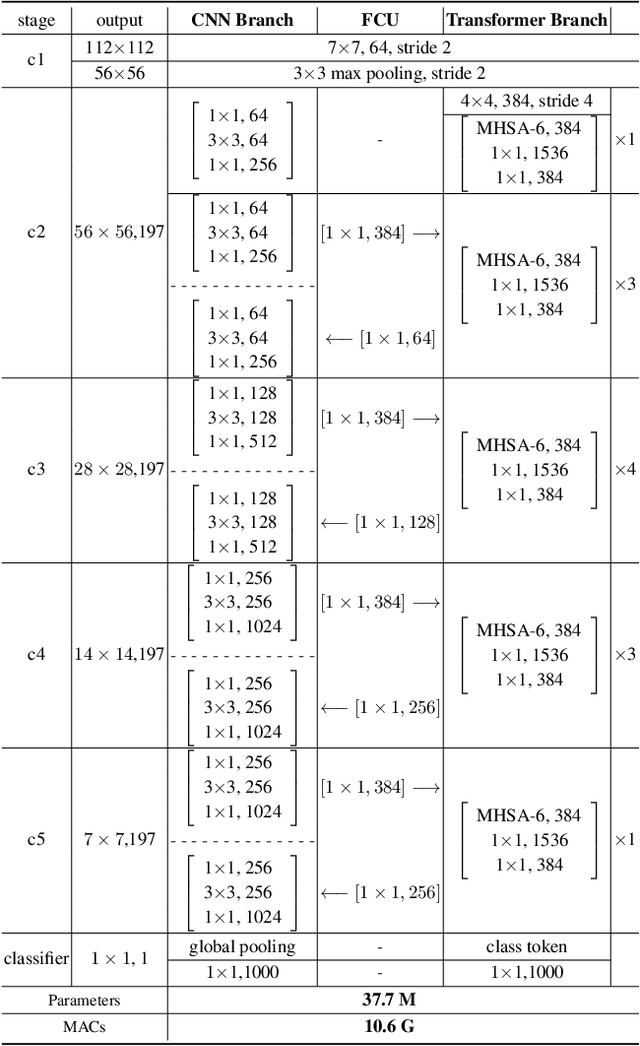
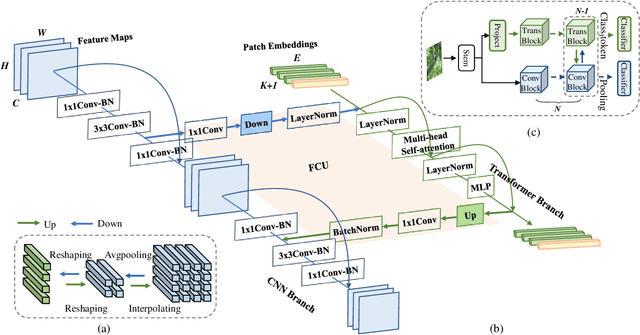
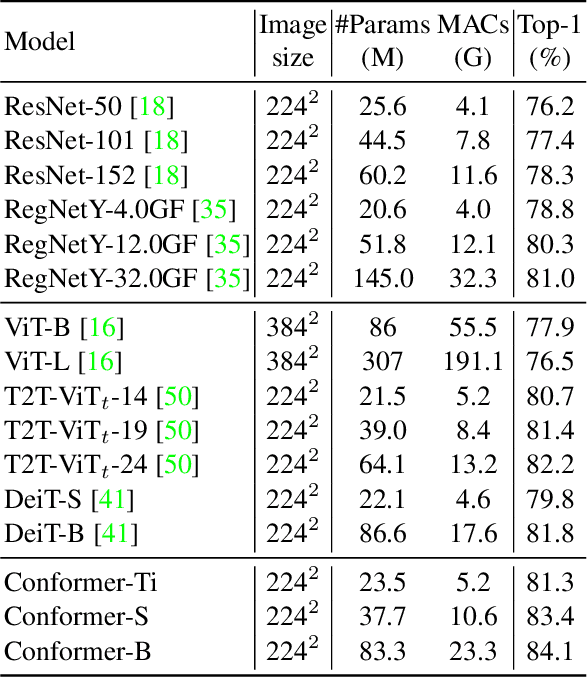
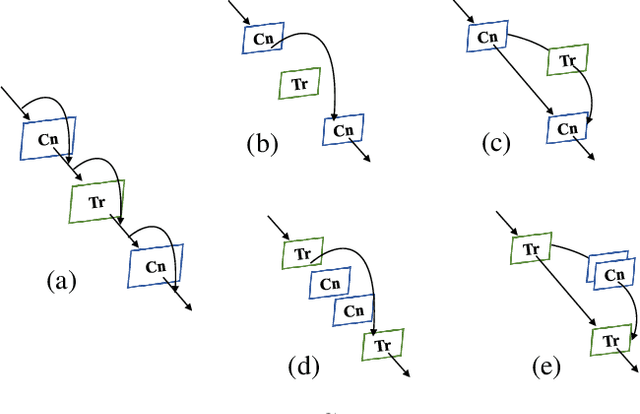
Within Convolutional Neural Network (CNN), the convolution operations are good at extracting local features but experience difficulty to capture global representations. Within visual transformer, the cascaded self-attention modules can capture long-distance feature dependencies but unfortunately deteriorate local feature details. In this paper, we propose a hybrid network structure, termed Conformer, to take advantage of convolutional operations and self-attention mechanisms for enhanced representation learning. Conformer roots in the Feature Coupling Unit (FCU), which fuses local features and global representations under different resolutions in an interactive fashion. Conformer adopts a concurrent structure so that local features and global representations are retained to the maximum extent. Experiments show that Conformer, under the comparable parameter complexity, outperforms the visual transformer (DeiT-B) by 2.3% on ImageNet. On MSCOCO, it outperforms ResNet-101 by 3.7% and 3.6% mAPs for object detection and instance segmentation, respectively, demonstrating the great potential to be a general backbone network. Code is available at https://github.com/pengzhiliang/Conformer.
PanGu-$α$: Large-scale Autoregressive Pretrained Chinese Language Models with Auto-parallel Computation
Apr 26, 2021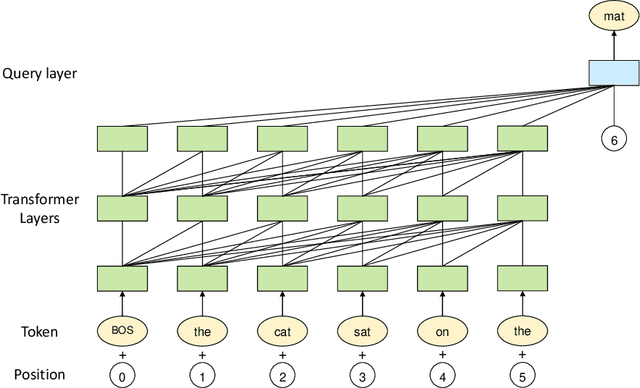
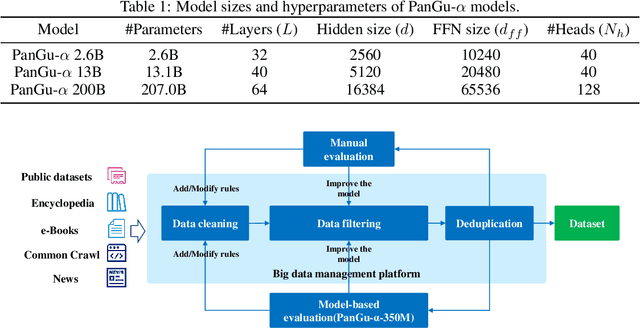
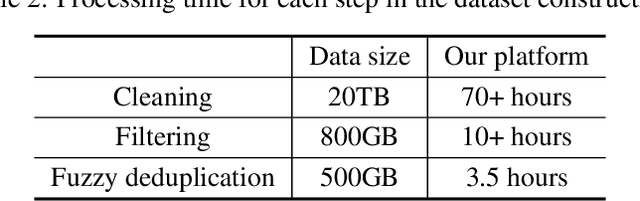
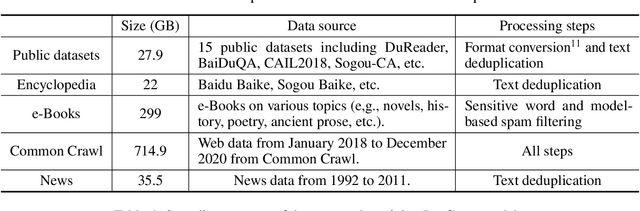
Large-scale Pretrained Language Models (PLMs) have become the new paradigm for Natural Language Processing (NLP). PLMs with hundreds of billions parameters such as GPT-3 have demonstrated strong performances on natural language understanding and generation with \textit{few-shot in-context} learning. In this work, we present our practice on training large-scale autoregressive language models named PanGu-$\alpha$, with up to 200 billion parameters. PanGu-$\alpha$ is developed under the MindSpore and trained on a cluster of 2048 Ascend 910 AI processors. The training parallelism strategy is implemented based on MindSpore Auto-parallel, which composes five parallelism dimensions to scale the training task to 2048 processors efficiently, including data parallelism, op-level model parallelism, pipeline model parallelism, optimizer model parallelism and rematerialization. To enhance the generalization ability of PanGu-$\alpha$, we collect 1.1TB high-quality Chinese data from a wide range of domains to pretrain the model. We empirically test the generation ability of PanGu-$\alpha$ in various scenarios including text summarization, question answering, dialogue generation, etc. Moreover, we investigate the effect of model scales on the few-shot performances across a broad range of Chinese NLP tasks. The experimental results demonstrate the superior capabilities of PanGu-$\alpha$ in performing various tasks under few-shot or zero-shot settings.