 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplaining Synergistic Effects in Social Recommendations
Jan 26, 2026In social recommenders, the inherent nonlinearity and opacity of synergistic effects across multiple social networks hinders users from understanding how diverse information is leveraged for recommendations, consequently diminishing explainability. However, existing explainers can only identify the topological information in social networks that significantly influences recommendations, failing to further explain the synergistic effects among this information. Inspired by existing findings that synergistic effects enhance mutual information between inputs and predictions to generate information gain, we extend this discovery to graph data. We quantify graph information gain to identify subgraphs embodying synergistic effects. Based on the theoretical insights, we propose SemExplainer, which explains synergistic effects by identifying subgraphs that embody them. SemExplainer first extracts explanatory subgraphs from multi-view social networks to generate preliminary importance explanations for recommendations. A conditional entropy optimization strategy to maximize information gain is developed, thereby further identifying subgraphs that embody synergistic effects from explanatory subgraphs. Finally, SemExplainer searches for paths from users to recommended items within the synergistic subgraphs to generate explanations for the recommendations. Extensive experiments on three datasets demonstrate the superiority of SemExplainer over baseline methods, providing superior explanations of synergistic effects.
VoiceSculptor: Your Voice, Designed By You
Jan 15, 2026Despite rapid progress in text-to-speech (TTS), open-source systems still lack truly instruction-following, fine-grained control over core speech attributes (e.g., pitch, speaking rate, age, emotion, and style). We present VoiceSculptor, an open-source unified system that bridges this gap by integrating instruction-based voice design and high-fidelity voice cloning in a single framework. It generates controllable speaker timbre directly from natural-language descriptions, supports iterative refinement via Retrieval-Augmented Generation (RAG), and provides attribute-level edits across multiple dimensions. The designed voice is then rendered into a prompt waveform and fed into a cloning model to enable high-fidelity timbre transfer for downstream speech synthesis. VoiceSculptor achieves open-source state-of-the-art (SOTA) on InstructTTSEval-Zh, and is fully open-sourced, including code and pretrained models, to advance reproducible instruction-controlled TTS research.
Burn-After-Use for Preventing Data Leakage through a Secure Multi-Tenant Architecture in Enterprise LLM
Jan 10, 2026This study presents a Secure Multi-Tenant Architecture (SMTA) combined with a novel concept Burn-After-Use (BAU) mechanism for enterprise LLM environments to effectively prevent data leakage. As institutions increasingly adopt LLMs across departments, the risks of data leakage have become a critical security and compliance concern. The proposed SMTA isolates LLM instances across departments and enforces rigorous context ownership boundaries within an internally deployed infrastructure. The BAU mechanism introduces data confidentiality by enforcing ephemeral conversational contexts that are automatically destroyed after use, preventing cross-session or cross-user inference. The evaluation to SMTA and BAU is through two sets of realistic and reproducible experiments comprising of 127 test iterations. One aspect of this experiment is to assess prompt-based and semantic leakage attacks in a multi-tenant architecture (Appendix A) across 55 infrastructure-level attack tests, including vector-database credential compromise and shared logging pipeline exposure. SMTA achieves 92% defense success rate, demonstrating strong semantic isolation while highlighting residual risks from credential misconfiguration and observability pipelines. Another aspect is to evaluate the robustness of BAU under realistic failure scenarios (Appendix B) using four empirical metrics: Local Residual Persistence Rate (LRPR), Remote Residual Persistence Rate (RRPR), Image Frame Exposure Rate (IFER), and Burn Timer Persistence Rate (BTPR). Across 72 test iterations, BAU achieves a 76.75% success rate in mitigating post-session leakage threats across the client, server, application, infrastructure, and cache layers. These results show that SMTA and BAU together enforce strict isolation, complete session ephemerality, strong confidentiality guarantees, non-persistence, and policy-aligned behavior for enterprise LLMs.
ArenaRL: Scaling RL for Open-Ended Agents via Tournament-based Relative Ranking
Jan 10, 2026Reinforcement learning has substantially improved the performance of LLM agents on tasks with verifiable outcomes, but it still struggles on open-ended agent tasks with vast solution spaces (e.g., complex travel planning). Due to the absence of objective ground-truth for these tasks, current RL algorithms largely rely on reward models that assign scalar scores to individual responses. We contend that such pointwise scoring suffers from an inherent discrimination collapse: the reward model struggles to distinguish subtle advantages among different trajectories, resulting in scores within a group being compressed into a narrow range. Consequently, the effective reward signal becomes dominated by noise from the reward model, leading to optimization stagnation. To address this, we propose ArenaRL, a reinforcement learning paradigm that shifts from pointwise scalar scoring to intra-group relative ranking. ArenaRL introduces a process-aware pairwise evaluation mechanism, employing multi-level rubrics to assign fine-grained relative scores to trajectories. Additionally, we construct an intra-group adversarial arena and devise a tournament-based ranking scheme to obtain stable advantage signals. Empirical results confirm that the built seeded single-elimination scheme achieves nearly equivalent advantage estimation accuracy to full pairwise comparisons with O(N^2) complexity, while operating with only O(N) complexity, striking an optimal balance between efficiency and precision. Furthermore, to address the lack of full-cycle benchmarks for open-ended agents, we build Open-Travel and Open-DeepResearch, two high-quality benchmarks featuring a comprehensive pipeline covering SFT, RL training, and multi-dimensional evaluation. Extensive experiments show that ArenaRL substantially outperforms standard RL baselines, enabling LLM agents to generate more robust solutions for complex real-world tasks.
REFA: Real-time Egocentric Facial Animations for Virtual Reality
Jan 07, 2026We present a novel system for real-time tracking of facial expressions using egocentric views captured from a set of infrared cameras embedded in a virtual reality (VR) headset. Our technology facilitates any user to accurately drive the facial expressions of virtual characters in a non-intrusive manner and without the need of a lengthy calibration step. At the core of our system is a distillation based approach to train a machine learning model on heterogeneous data and labels coming form multiple sources, \eg synthetic and real images. As part of our dataset, we collected 18k diverse subjects using a lightweight capture setup consisting of a mobile phone and a custom VR headset with extra cameras. To process this data, we developed a robust differentiable rendering pipeline enabling us to automatically extract facial expression labels. Our system opens up new avenues for communication and expression in virtual environments, with applications in video conferencing, gaming, entertainment, and remote collaboration.
Efficient Sequential Recommendation for Long Term User Interest Via Personalization
Jan 07, 2026Recent years have witnessed success of sequential modeling, generative recommender, and large language model for recommendation. Though the scaling law has been validated for sequential models, it showed inefficiency in computational capacity when considering real-world applications like recommendation, due to the non-linear(quadratic) increasing nature of the transformer model. To improve the efficiency of the sequential model, we introduced a novel approach to sequential recommendation that leverages personalization techniques to enhance efficiency and performance. Our method compresses long user interaction histories into learnable tokens, which are then combined with recent interactions to generate recommendations. This approach significantly reduces computational costs while maintaining high recommendation accuracy. Our method could be applied to existing transformer based recommendation models, e.g., HSTU and HLLM. Extensive experiments on multiple sequential models demonstrate its versatility and effectiveness. Source code is available at \href{https://github.com/facebookresearch/PerSRec}{https://github.com/facebookresearch/PerSRec}.
Evo-TFS: Evolutionary Time-Frequency Domain-Based Synthetic Minority Oversampling Approach to Imbalanced Time Series Classification
Jan 03, 2026Time series classification is a fundamental machine learning task with broad real-world applications. Although many deep learning methods have proven effective in learning time-series data for classification, they were originally developed under the assumption of balanced data distributions. Once data distribution is uneven, these methods tend to ignore the minority class that is typically of higher practical significance. Oversampling methods have been designed to address this by generating minority-class samples, but their reliance on linear interpolation often hampers the preservation of temporal dynamics and the generation of diverse samples. Therefore, in this paper, we propose Evo-TFS, a novel evolutionary oversampling method that integrates both time- and frequency-domain characteristics. In Evo-TFS, strongly typed genetic programming is employed to evolve diverse, high-quality time series, guided by a fitness function that incorporates both time-domain and frequency-domain characteristics. Experiments conducted on imbalanced time series datasets demonstrate that Evo-TFS outperforms existing oversampling methods, significantly enhancing the performance of time-domain and frequency-domain classifiers.
ClinDEF: A Dynamic Evaluation Framework for Large Language Models in Clinical Reasoning
Dec 29, 2025Clinical diagnosis begins with doctor-patient interaction, during which physicians iteratively gather information, determine examination and refine differential diagnosis through patients' response. This dynamic clinical-reasoning process is poorly represented by existing LLM benchmarks that focus on static question-answering. To mitigate these gaps, recent methods explore dynamic medical frameworks involving interactive clinical dialogues. Although effective, they often rely on limited, contamination-prone datasets and lack granular, multi-level evaluation. In this work, we propose ClinDEF, a dynamic framework for assessing clinical reasoning in LLMs through simulated diagnostic dialogues. Grounded in a disease knowledge graph, our method dynamically generates patient cases and facilitates multi-turn interactions between an LLM-based doctor and an automated patient agent. Our evaluation protocol goes beyond diagnostic accuracy by incorporating fine-grained efficiency analysis and rubric-based assessment of diagnostic quality. Experiments show that ClinDEF effectively exposes critical clinical reasoning gaps in state-of-the-art LLMs, offering a more nuanced and clinically meaningful evaluation paradigm.
High-Fidelity and Long-Duration Human Image Animation with Diffusion Transformer
Dec 26, 2025



Recent progress in diffusion models has significantly advanced the field of human image animation. While existing methods can generate temporally consistent results for short or regular motions, significant challenges remain, particularly in generating long-duration videos. Furthermore, the synthesis of fine-grained facial and hand details remains under-explored, limiting the applicability of current approaches in real-world, high-quality applications. To address these limitations, we propose a diffusion transformer (DiT)-based framework which focuses on generating high-fidelity and long-duration human animation videos. First, we design a set of hybrid implicit guidance signals and a sharpness guidance factor, enabling our framework to additionally incorporate detailed facial and hand features as guidance. Next, we incorporate the time-aware position shift fusion module, modify the input format within the DiT backbone, and refer to this mechanism as the Position Shift Adaptive Module, which enables video generation of arbitrary length. Finally, we introduce a novel data augmentation strategy and a skeleton alignment model to reduce the impact of human shape variations across different identities. Experimental results demonstrate that our method outperforms existing state-of-the-art approaches, achieving superior performance in both high-fidelity and long-duration human image animation.
Code-in-the-Loop Forensics: Agentic Tool Use for Image Forgery Detection
Dec 18, 2025
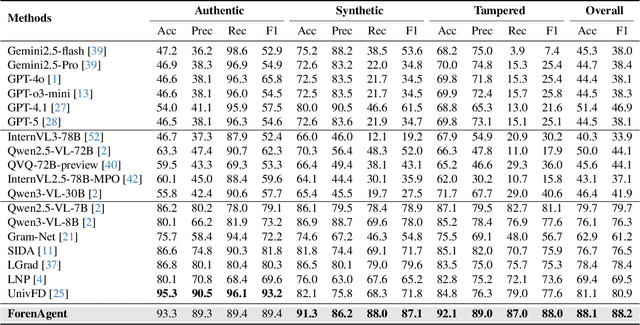
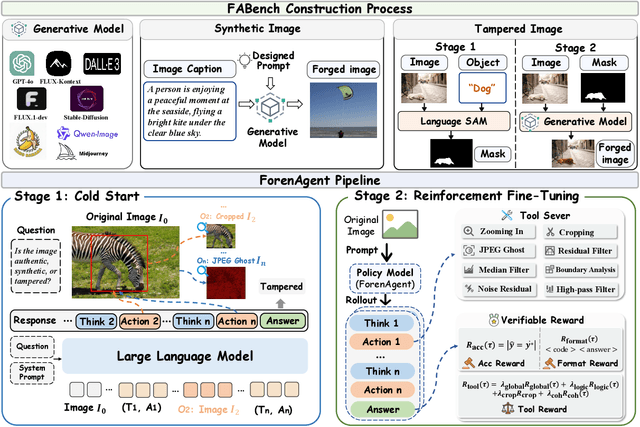
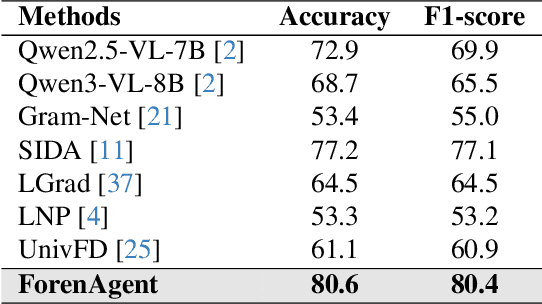
Existing image forgery detection (IFD) methods either exploit low-level, semantics-agnostic artifacts or rely on multimodal large language models (MLLMs) with high-level semantic knowledge. Although naturally complementary, these two information streams are highly heterogeneous in both paradigm and reasoning, making it difficult for existing methods to unify them or effectively model their cross-level interactions. To address this gap, we propose ForenAgent, a multi-round interactive IFD framework that enables MLLMs to autonomously generate, execute, and iteratively refine Python-based low-level tools around the detection objective, thereby achieving more flexible and interpretable forgery analysis. ForenAgent follows a two-stage training pipeline combining Cold Start and Reinforcement Fine-Tuning to enhance its tool interaction capability and reasoning adaptability progressively. Inspired by human reasoning, we design a dynamic reasoning loop comprising global perception, local focusing, iterative probing, and holistic adjudication, and instantiate it as both a data-sampling strategy and a task-aligned process reward. For systematic training and evaluation, we construct FABench, a heterogeneous, high-quality agent-forensics dataset comprising 100k images and approximately 200k agent-interaction question-answer pairs. Experiments show that ForenAgent exhibits emergent tool-use competence and reflective reasoning on challenging IFD tasks when assisted by low-level tools, charting a promising route toward general-purpose IFD. The code will be released after the review process is completed.