 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVimRAG: Navigating Massive Visual Context in Retrieval-Augmented Generation via Multimodal Memory Graph
Feb 13, 2026Effectively retrieving, reasoning, and understanding multimodal information remains a critical challenge for agentic systems. Traditional Retrieval-augmented Generation (RAG) methods rely on linear interaction histories, which struggle to handle long-context tasks, especially those involving information-sparse yet token-heavy visual data in iterative reasoning scenarios. To bridge this gap, we introduce VimRAG, a framework tailored for multimodal Retrieval-augmented Reasoning across text, images, and videos. Inspired by our systematic study, we model the reasoning process as a dynamic directed acyclic graph that structures the agent states and retrieved multimodal evidence. Building upon this structured memory, we introduce a Graph-Modulated Visual Memory Encoding mechanism, with which the significance of memory nodes is evaluated via their topological position, allowing the model to dynamically allocate high-resolution tokens to pivotal evidence while compressing or discarding trivial clues. To implement this paradigm, we propose a Graph-Guided Policy Optimization strategy. This strategy disentangles step-wise validity from trajectory-level rewards by pruning memory nodes associated with redundant actions, thereby facilitating fine-grained credit assignment. Extensive experiments demonstrate that VimRAG consistently achieves state-of-the-art performance on diverse multimodal RAG benchmarks. The code is available at https://github.com/Alibaba-NLP/VRAG.
ArenaRL: Scaling RL for Open-Ended Agents via Tournament-based Relative Ranking
Jan 10, 2026Reinforcement learning has substantially improved the performance of LLM agents on tasks with verifiable outcomes, but it still struggles on open-ended agent tasks with vast solution spaces (e.g., complex travel planning). Due to the absence of objective ground-truth for these tasks, current RL algorithms largely rely on reward models that assign scalar scores to individual responses. We contend that such pointwise scoring suffers from an inherent discrimination collapse: the reward model struggles to distinguish subtle advantages among different trajectories, resulting in scores within a group being compressed into a narrow range. Consequently, the effective reward signal becomes dominated by noise from the reward model, leading to optimization stagnation. To address this, we propose ArenaRL, a reinforcement learning paradigm that shifts from pointwise scalar scoring to intra-group relative ranking. ArenaRL introduces a process-aware pairwise evaluation mechanism, employing multi-level rubrics to assign fine-grained relative scores to trajectories. Additionally, we construct an intra-group adversarial arena and devise a tournament-based ranking scheme to obtain stable advantage signals. Empirical results confirm that the built seeded single-elimination scheme achieves nearly equivalent advantage estimation accuracy to full pairwise comparisons with O(N^2) complexity, while operating with only O(N) complexity, striking an optimal balance between efficiency and precision. Furthermore, to address the lack of full-cycle benchmarks for open-ended agents, we build Open-Travel and Open-DeepResearch, two high-quality benchmarks featuring a comprehensive pipeline covering SFT, RL training, and multi-dimensional evaluation. Extensive experiments show that ArenaRL substantially outperforms standard RL baselines, enabling LLM agents to generate more robust solutions for complex real-world tasks.
VRAG-RL: Empower Vision-Perception-Based RAG for Visually Rich Information Understanding via Iterative Reasoning with Reinforcement Learning
May 28, 2025Effectively retrieving, reasoning and understanding visually rich information remains a challenge for RAG methods. Traditional text-based methods cannot handle visual-related information. On the other hand, current vision-based RAG approaches are often limited by fixed pipelines and frequently struggle to reason effectively due to the insufficient activation of the fundamental capabilities of models. As RL has been proven to be beneficial for model reasoning, we introduce VRAG-RL, a novel RL framework tailored for complex reasoning across visually rich information. With this framework, VLMs interact with search engines, autonomously sampling single-turn or multi-turn reasoning trajectories with the help of visual perception tokens and undergoing continual optimization based on these samples. Our approach highlights key limitations of RL in RAG domains: (i) Prior Multi-modal RAG approaches tend to merely incorporate images into the context, leading to insufficient reasoning token allocation and neglecting visual-specific perception; and (ii) When models interact with search engines, their queries often fail to retrieve relevant information due to the inability to articulate requirements, thereby leading to suboptimal performance. To address these challenges, we define an action space tailored for visually rich inputs, with actions including cropping and scaling, allowing the model to gather information from a coarse-to-fine perspective. Furthermore, to bridge the gap between users' original inquiries and the retriever, we employ a simple yet effective reward that integrates query rewriting and retrieval performance with a model-based reward. Our VRAG-RL optimizes VLMs for RAG tasks using specially designed RL strategies, aligning the model with real-world applications. The code is available at \hyperlink{https://github.com/Alibaba-NLP/VRAG}{https://github.com/Alibaba-NLP/VRAG}.
ViDoRAG: Visual Document Retrieval-Augmented Generation via Dynamic Iterative Reasoning Agents
Feb 25, 2025



Understanding information from visually rich documents remains a significant challenge for traditional Retrieval-Augmented Generation (RAG) methods. Existing benchmarks predominantly focus on image-based question answering (QA), overlooking the fundamental challenges of efficient retrieval, comprehension, and reasoning within dense visual documents. To bridge this gap, we introduce ViDoSeek, a novel dataset designed to evaluate RAG performance on visually rich documents requiring complex reasoning. Based on it, we identify key limitations in current RAG approaches: (i) purely visual retrieval methods struggle to effectively integrate both textual and visual features, and (ii) previous approaches often allocate insufficient reasoning tokens, limiting their effectiveness. To address these challenges, we propose ViDoRAG, a novel multi-agent RAG framework tailored for complex reasoning across visual documents. ViDoRAG employs a Gaussian Mixture Model (GMM)-based hybrid strategy to effectively handle multi-modal retrieval. To further elicit the model's reasoning capabilities, we introduce an iterative agent workflow incorporating exploration, summarization, and reflection, providing a framework for investigating test-time scaling in RAG domains. Extensive experiments on ViDoSeek validate the effectiveness and generalization of our approach. Notably, ViDoRAG outperforms existing methods by over 10% on the competitive ViDoSeek benchmark.
CoFE-RAG: A Comprehensive Full-chain Evaluation Framework for Retrieval-Augmented Generation with Enhanced Data Diversity
Oct 16, 2024Retrieval-Augmented Generation (RAG) aims to enhance large language models (LLMs) to generate more accurate and reliable answers with the help of the retrieved context from external knowledge sources, thereby reducing the incidence of hallucinations. Despite the advancements, evaluating these systems remains a crucial research area due to the following issues: (1) Limited data diversity: The insufficient diversity of knowledge sources and query types constrains the applicability of RAG systems; (2) Obscure problems location: Existing evaluation methods have difficulty in locating the stage of the RAG pipeline where problems occur; (3) Unstable retrieval evaluation: These methods often fail to effectively assess retrieval performance, particularly when the chunking strategy changes. To tackle these challenges, we propose a Comprehensive Full-chain Evaluation (CoFE-RAG) framework to facilitate thorough evaluation across the entire RAG pipeline, including chunking, retrieval, reranking, and generation. To effectively evaluate the first three phases, we introduce multi-granularity keywords, including coarse-grained and fine-grained keywords, to assess the retrieved context instead of relying on the annotation of golden chunks. Moreover, we release a holistic benchmark dataset tailored for diverse data scenarios covering a wide range of document formats and query types. We demonstrate the utility of the CoFE-RAG framework by conducting experiments to evaluate each stage of RAG systems. Our evaluation method provides unique insights into the effectiveness of RAG systems in handling diverse data scenarios, offering a more nuanced understanding of their capabilities and limitations.
Let LLMs Take on the Latest Challenges! A Chinese Dynamic Question Answering Benchmark
Mar 02, 2024



How to better evaluate the capabilities of Large Language Models (LLMs) is the focal point and hot topic in current LLMs research. Previous work has noted that due to the extremely high cost of iterative updates of LLMs, they are often unable to answer the latest dynamic questions well. To promote the improvement of Chinese LLMs' ability to answer dynamic questions, in this paper, we introduce CDQA, a Chinese Dynamic QA benchmark containing question-answer pairs related to the latest news on the Chinese Internet. We obtain high-quality data through a pipeline that combines humans and models, and carefully classify the samples according to the frequency of answer changes to facilitate a more fine-grained observation of LLMs' capabilities. We have also evaluated and analyzed mainstream and advanced Chinese LLMs on CDQA. Extensive experiments and valuable insights suggest that our proposed CDQA is challenging and worthy of more further study. We believe that the benchmark we provide will become one of the key data resources for improving LLMs' Chinese question-answering ability in the future.
Geo-Encoder: A Chunk-Argument Bi-Encoder Framework for Chinese Geographic Re-Ranking
Sep 04, 2023



Chinese geographic re-ranking task aims to find the most relevant addresses among retrieved candidates, which is crucial for location-related services such as navigation maps. Unlike the general sentences, geographic contexts are closely intertwined with geographical concepts, from general spans (e.g., province) to specific spans (e.g., road). Given this feature, we propose an innovative framework, namely Geo-Encoder, to more effectively integrate Chinese geographical semantics into re-ranking pipelines. Our methodology begins by employing off-the-shelf tools to associate text with geographical spans, treating them as chunking units. Then, we present a multi-task learning module to simultaneously acquire an effective attention matrix that determines chunk contributions to extra semantic representations. Furthermore, we put forth an asynchronous update mechanism for the proposed addition task, aiming to guide the model capable of effectively focusing on specific chunks. Experiments on two distinct Chinese geographic re-ranking datasets, show that the Geo-Encoder achieves significant improvements when compared to state-of-the-art baselines. Notably, it leads to a substantial improvement in the Hit@1 score of MGEO-BERT, increasing it by 6.22% from 62.76 to 68.98 on the GeoTES dataset.
GeoGLUE: A GeoGraphic Language Understanding Evaluation Benchmark
May 11, 2023



With a fast developing pace of geographic applications, automatable and intelligent models are essential to be designed to handle the large volume of information. However, few researchers focus on geographic natural language processing, and there has never been a benchmark to build a unified standard. In this work, we propose a GeoGraphic Language Understanding Evaluation benchmark, named GeoGLUE. We collect data from open-released geographic resources and introduce six natural language understanding tasks, including geographic textual similarity on recall, geographic textual similarity on rerank, geographic elements tagging, geographic composition analysis, geographic where what cut, and geographic entity alignment. We also pro vide evaluation experiments and analysis of general baselines, indicating the effectiveness and significance of the GeoGLUE benchmark.
A Multi-Modal Geographic Pre-Training Method
Jan 11, 2023



As a core task in location-based services (LBS) (e.g., navigation maps), query and point of interest (POI) matching connects users' intent with real-world geographic information. Recently, pre-trained models (PTMs) have made advancements in many natural language processing (NLP) tasks. Generic text-based PTMs do not have enough geographic knowledge for query-POI matching. To overcome this limitation, related literature attempts to employ domain-adaptive pre-training based on geo-related corpus. However, a query generally contains mentions of multiple geographic objects, such as nearby roads and regions of interest (ROIs). The geographic context (GC), i.e., these diverse geographic objects and their relationships, is therefore pivotal to retrieving the most relevant POI. Single-modal PTMs can barely make use of the important GC and therefore have limited performance. In this work, we propose a novel query-POI matching method Multi-modal Geographic language model (MGeo), which comprises a geographic encoder and a multi-modal interaction module. MGeo represents GC as a new modality and is able to fully extract multi-modal correlations for accurate query-POI matching. Besides, there is no publicly available benchmark for this topic. In order to facilitate further research, we build a new open-source large-scale benchmark Geographic TExtual Similarity (GeoTES). The POIs come from an open-source geographic information system (GIS). The queries are manually generated by annotators to prevent privacy issues. Compared with several strong baselines, the extensive experiment results and detailed ablation analyses on GeoTES demonstrate that our proposed multi-modal pre-training method can significantly improve the query-POI matching capability of generic PTMs, even when the queries' GC is not provided. Our code and dataset are publicly available at https://github.com/PhantomGrapes/MGeo.
Forging Multiple Training Objectives for Pre-trained Language Models via Meta-Learning
Oct 19, 2022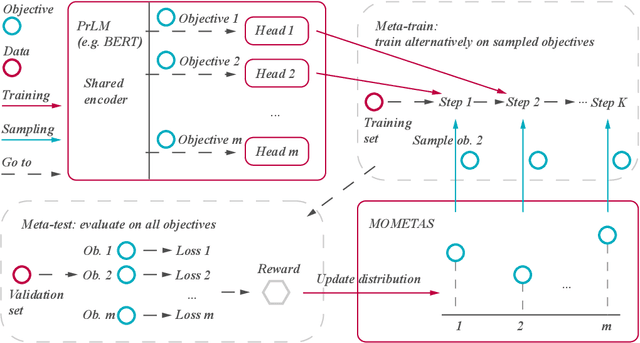
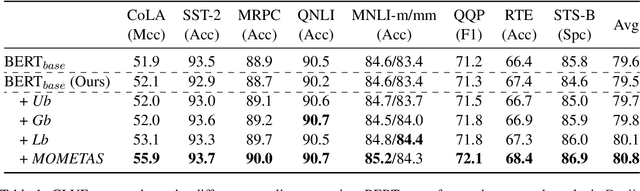
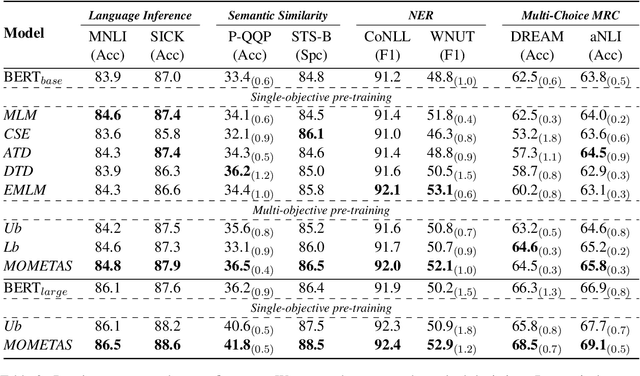
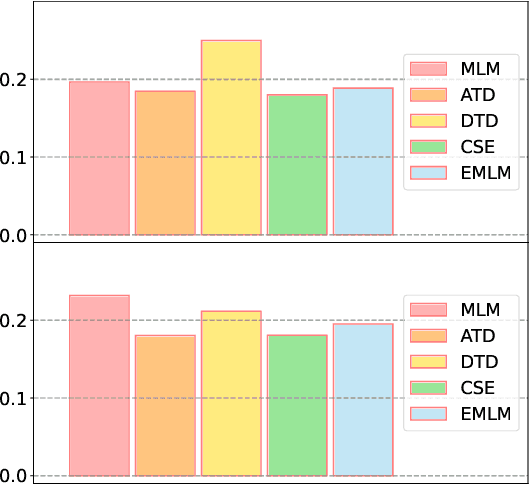
Multiple pre-training objectives fill the vacancy of the understanding capability of single-objective language modeling, which serves the ultimate purpose of pre-trained language models (PrLMs), generalizing well on a mass of scenarios. However, learning multiple training objectives in a single model is challenging due to the unknown relative significance as well as the potential contrariety between them. Empirical studies have shown that the current objective sampling in an ad-hoc manual setting makes the learned language representation barely converge to the desired optimum. Thus, we propose \textit{MOMETAS}, a novel adaptive sampler based on meta-learning, which learns the latent sampling pattern on arbitrary pre-training objectives. Such a design is lightweight with negligible additional training overhead. To validate our approach, we adopt five objectives and conduct continual pre-training with BERT-base and BERT-large models, where MOMETAS demonstrates universal performance gain over other rule-based sampling strategies on 14 natural language processing tasks.