 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Sequential Recommendation for Long Term User Interest Via Personalization
Jan 07, 2026Recent years have witnessed success of sequential modeling, generative recommender, and large language model for recommendation. Though the scaling law has been validated for sequential models, it showed inefficiency in computational capacity when considering real-world applications like recommendation, due to the non-linear(quadratic) increasing nature of the transformer model. To improve the efficiency of the sequential model, we introduced a novel approach to sequential recommendation that leverages personalization techniques to enhance efficiency and performance. Our method compresses long user interaction histories into learnable tokens, which are then combined with recent interactions to generate recommendations. This approach significantly reduces computational costs while maintaining high recommendation accuracy. Our method could be applied to existing transformer based recommendation models, e.g., HSTU and HLLM. Extensive experiments on multiple sequential models demonstrate its versatility and effectiveness. Source code is available at \href{https://github.com/facebookresearch/PerSRec}{https://github.com/facebookresearch/PerSRec}.
Breaking the Curse of Quality Saturation with User-Centric Ranking
May 24, 2023



A key puzzle in search, ads, and recommendation is that the ranking model can only utilize a small portion of the vastly available user interaction data. As a result, increasing data volume, model size, or computation FLOPs will quickly suffer from diminishing returns. We examined this problem and found that one of the root causes may lie in the so-called ``item-centric'' formulation, which has an unbounded vocabulary and thus uncontrolled model complexity. To mitigate quality saturation, we introduce an alternative formulation named ``user-centric ranking'', which is based on a transposed view of the dyadic user-item interaction data. We show that this formulation has a promising scaling property, enabling us to train better-converged models on substantially larger data sets.
Class-Similarity Based Label Smoothing for Generalized Confidence Calibration
Jun 24, 2020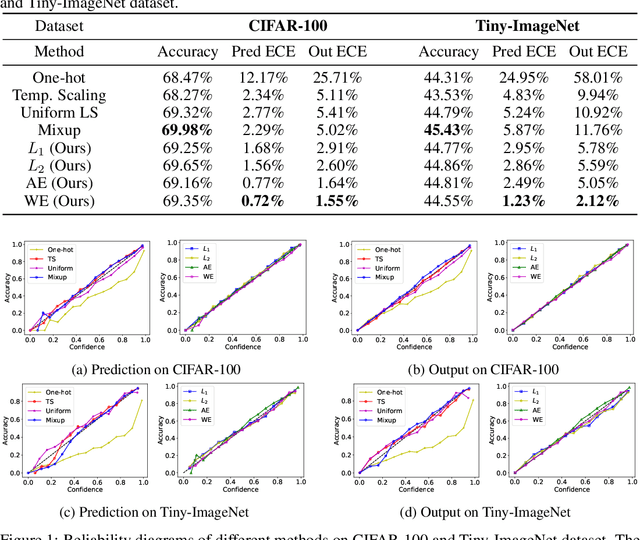
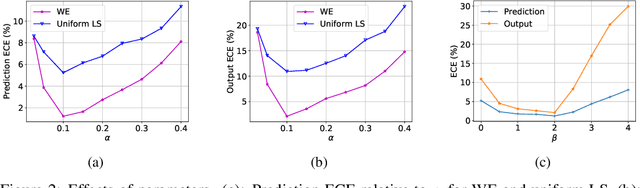
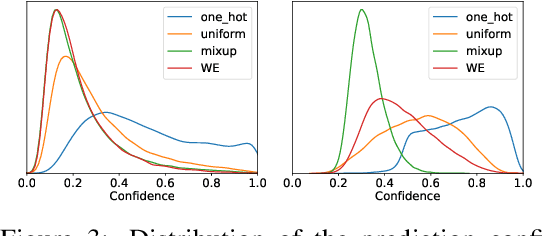
Since modern neural networks are known to be overconfident, several techniques have been recently introduced to address this problem and improve calibration. However, the current notion of calibration is overly simple since only single prediction confidence is considered while the information regarding the rest of the classes is ignored. The output of a neural network is a probability distribution where the scores are estimated confidences of the input belonging to the corresponding classes, and hence they represent a complete estimate of the output likelihood that should be calibrated. In this paper, we first introduce a generalized definition of confidence calibration, which motivates the development of a novel form of label smoothing where the value of each class label is based on its similarity with the reference class. We adopt different similarity measurements, including those that capture semantic similarity, and demonstrate through extensive experiments the advantage of our method over both uniform label smoothing and other techniques.