 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExperience Makes Skillful: Enabling Generalizable Medical Agent Reasoning via Self-Evolving Skill Memory
Jun 08, 2026Medical agent systems are increasingly expected to support interactive clinical decision making rather than only static question answering. In such settings, effective agents must reuse prior experience across evolving cases, yet existing memory mechanisms often retain raw historical traces that are redundant, noisy, and difficult to govern. More importantly, they rarely distinguish which memories are truly useful for future reasoning. This limits their ability to accumulate compact and reliable experience for long-horizon clinical reasoning. To close this gap, we propose SkeMex, a post-deployment self-evolution framework that improves medical agents through a skill-based memory without updating model weights. SkeMex distills informative interaction trajectories into structured skills that encode reusable procedural knowledge, and organizes them into a multi-branch repository spanning general, task-specific, and action-level experience. To determine which memories should be reused and retained, SkeMex estimates context-dependent utility from environment feedback and uses it to guide value-aware retrieval and repository governance. A closed-loop ``Read--Write--Assess--Govern" lifecycle further supports continual evolution by writing new skills, updating utilities, promoting useful memories, and removing harmful entries. Experiments across diverse clinical tasks show that SkeMex consistently outperforms representative memory-based agents in both offline and online settings. It also generalizes across model backbones and supports transferable skill memory. All data and code will be released publicly.
ASAP: An Azimuth-Priority Strip-Based Search Approach to Planar Microphone Array DOA Estimation in 3D
Apr 28, 2026Direction-of-arrival (DOA) estimation is an important task in microphone array processing and many downstream applications. The steered response power with phase transform (SRP-PHAT) method has been widely adopted for DOA estimation in recent years. However, accurate SRP-PHAT estimation in 3D scenarios requires evaluating steering responses over thousands of candidate directions, severely limiting real-time performance on resource-constrained platforms. This challenge becomes even more critical for planar arrays, which are widely used in robotics due to their structural simplicity. Motivated by the fact that azimuth estimation is usually more reliable than elevation estimation for most arrays, we propose ASAP, an azimuth-priority strip-based search approach to planar microphone array DOA estimation in 3D. In the first stage, ASAP performs coarse-to-fine region contraction within azimuthal strips to lock azimuth angles while retaining multiple maxima through spherical caps. In the second stage, it refines elevation along the great-circle arc between two close candidates. Extensive simulations and real-world experiments validate the efficiency and merits of the proposed method over existing approaches.
Wired for Overconfidence: A Mechanistic Perspective on Inflated Verbalized Confidence in LLMs
Apr 01, 2026Large language models are often not just wrong, but \emph{confidently wrong}: when they produce factually incorrect answers, they tend to verbalize overly high confidence rather than signal uncertainty. Such verbalized overconfidence can mislead users and weaken confidence scores as a reliable uncertainty signal, yet its internal mechanisms remain poorly understood. We present a circuit-level mechanistic analysis of this inflated verbalized confidence in LLMs, organized around three axes: capturing verbalized confidence as a differentiable internal signal, identifying the circuits that causally inflate it, and leveraging these insights for targeted inference-time recalibration. Across two instruction-tuned LLMs on three datasets, we find that a compact set of MLP blocks and attention heads, concentrated in middle-to-late layers, consistently writes the confidence-inflation signal at the final token position. We further show that targeted inference-time interventions on these circuits substantially improve calibration. Together, our results suggest that verbalized overconfidence in LLMs is driven by identifiable internal circuits and can be mitigated through targeted intervention.
EpiPersona: Persona Projection and Episode Coupling for Pluralistic Preference Modeling
Mar 30, 2026Pluralistic alignment is essential for adapting large language models (LLMs) to the diverse preferences of individuals and minority groups. However, existing approaches often mix stable personal traits with episode-specific factors, limiting their ability to generalize across episodes. To address this challenge, we introduce EpiPersona, a framework for explicit persona-episode coupling. EpiPersona first projects noisy preference feedback into a low-dimensional persona space, where similar personas are aggregated into shared discrete codes. This process separates enduring personal characteristics from situational signals without relying on predefined preference dimensions. The inferred persona representation is then coupled with the current episode, enabling episode-aware preference prediction. Extensive experiments show that EpiPersona consistently outperforms the baselines. It achieves notable performance gains in hard episodic-shift scenarios, while remaining effective with sparse preference data.
MedScope: Incentivizing "Think with Videos" for Clinical Reasoning via Coarse-to-Fine Tool Calling
Feb 11, 2026Long-form clinical videos are central to visual evidence-based decision-making, with growing importance for applications such as surgical robotics and related settings. However, current multimodal large language models typically process videos with passive sampling or weakly grounded inspection, which limits their ability to iteratively locate, verify, and justify predictions with temporally targeted evidence. To close this gap, we propose MedScope, a tool-using clinical video reasoning model that performs coarse-to-fine evidence seeking over long-form procedures. By interleaving intermediate reasoning with targeted tool calls and verification on retrieved observations, MedScope produces more accurate and trustworthy predictions that are explicitly grounded in temporally localized visual evidence. To address the lack of high-fidelity supervision, we build ClinVideoSuite, an evidence-centric, fine-grained clinical video suite. We then optimize MedScope with Grounding-Aware Group Relative Policy Optimization (GA-GRPO), which directly reinforces tool use with grounding-aligned rewards and evidence-weighted advantages. On full and fine-grained video understanding benchmarks, MedScope achieves state-of-the-art performance in both in-domain and out-of-domain evaluations. Our approach illuminates a path toward medical AI agents that can genuinely "think with videos" through tool-integrated reasoning. We will release our code, models, and data.
Angular Sensing by Highly Reconfigurable Pixel Antennas with Joint Radiating Aperture and Feeding Ports Reconfiguration
Jan 19, 2026Angular sensing capability is realized using highly reconfigurable pixel antenna (HRPA) with joint radiating aperture and feeding ports reconfiguration. Pixel antennas represent a general class of reconfigurable antenna designs in which the radiating surface, regardless of its shape or size, is divided into sub-wavelength elements called pixels. Each pixel is connected to its neighboring elements through radio frequency switches. By controlling pixel connections, the pixel antenna topology can be flexibly adjusted so that the resulting radiation pattern can be reconfigured. However, conventional pixel antennas have only a single, fixed-position feeding port, which is not efficient for angular sensing. Therefore, in this work, we further extend the reconfigurability of pixel antennas by introducing the HRPA, which enables both geometry control of the pixel antenna and switching of its feeding ports. The model of the proposed HRPA, including both circuit and radiation parameters, is derived. A codebook is then defined, consisting of pixel connection states and feeding port positions for each sensing area. Based on this codebook, an efficient optimization approach is developed to minimize the Cram\acute{\mathrm{\mathbf{e}}}r-Rao lower bound (CRLB) and obtain the optimal HRPA geometries for angular sensing within a given area. Numerical results show that the HRPA reduces the angle estimation error by more than 50% across the full three-dimensional sphere when compared with a conventional uniform planar array of the same size. This demonstrates the effectiveness of the proposed approach and highlights the potential of HRPA for integrated sensing and communication systems.
RSAgent: Learning to Reason and Act for Text-Guided Segmentation via Multi-Turn Tool Invocations
Dec 30, 2025Text-guided object segmentation requires both cross-modal reasoning and pixel grounding abilities. Most recent methods treat text-guided segmentation as one-shot grounding, where the model predicts pixel prompts in a single forward pass to drive an external segmentor, which limits verification, refocusing and refinement when initial localization is wrong. To address this limitation, we propose RSAgent, an agentic Multimodal Large Language Model (MLLM) which interleaves reasoning and action for segmentation via multi-turn tool invocations. RSAgent queries a segmentation toolbox, observes visual feedback, and revises its spatial hypothesis using historical observations to re-localize targets and iteratively refine masks. We further build a data pipeline to synthesize multi-turn reasoning segmentation trajectories, and train RSAgent with a two-stage framework: cold-start supervised fine-tuning followed by agentic reinforcement learning with fine-grained, task-specific rewards. Extensive experiments show that RSAgent achieves a zero-shot performance of 66.5% gIoU on ReasonSeg test, improving over Seg-Zero-7B by 9%, and reaches 81.5% cIoU on RefCOCOg, demonstrating state-of-the-art performance on both in-domain and out-of-domain benchmarks.
Code-in-the-Loop Forensics: Agentic Tool Use for Image Forgery Detection
Dec 18, 2025
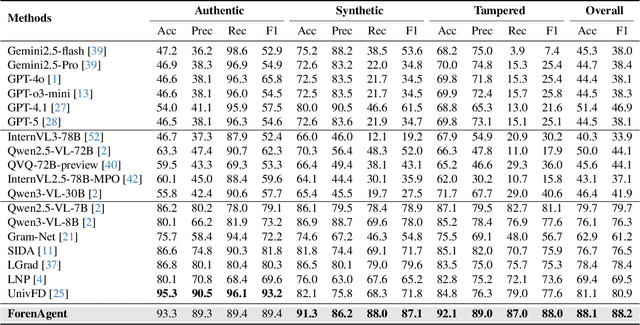
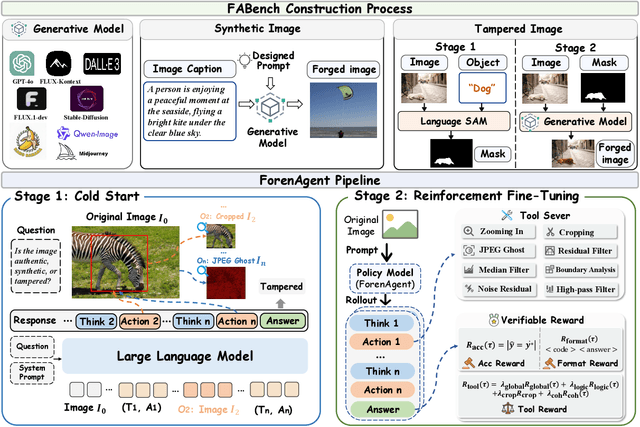
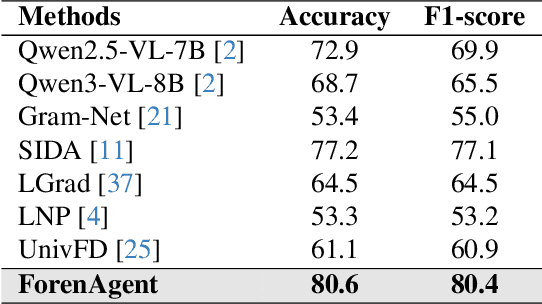
Existing image forgery detection (IFD) methods either exploit low-level, semantics-agnostic artifacts or rely on multimodal large language models (MLLMs) with high-level semantic knowledge. Although naturally complementary, these two information streams are highly heterogeneous in both paradigm and reasoning, making it difficult for existing methods to unify them or effectively model their cross-level interactions. To address this gap, we propose ForenAgent, a multi-round interactive IFD framework that enables MLLMs to autonomously generate, execute, and iteratively refine Python-based low-level tools around the detection objective, thereby achieving more flexible and interpretable forgery analysis. ForenAgent follows a two-stage training pipeline combining Cold Start and Reinforcement Fine-Tuning to enhance its tool interaction capability and reasoning adaptability progressively. Inspired by human reasoning, we design a dynamic reasoning loop comprising global perception, local focusing, iterative probing, and holistic adjudication, and instantiate it as both a data-sampling strategy and a task-aligned process reward. For systematic training and evaluation, we construct FABench, a heterogeneous, high-quality agent-forensics dataset comprising 100k images and approximately 200k agent-interaction question-answer pairs. Experiments show that ForenAgent exhibits emergent tool-use competence and reflective reasoning on challenging IFD tasks when assisted by low-level tools, charting a promising route toward general-purpose IFD. The code will be released after the review process is completed.
Incentivizing Tool-augmented Thinking with Images for Medical Image Analysis
Dec 16, 2025Recent reasoning based medical MLLMs have made progress in generating step by step textual reasoning chains. However, they still struggle with complex tasks that necessitate dynamic and iterative focusing on fine-grained visual regions to achieve precise grounding and diagnosis. We introduce Ophiuchus, a versatile, tool-augmented framework that equips an MLLM to (i) decide when additional visual evidence is needed, (ii) determine where to probe and ground within the medical image, and (iii) seamlessly weave the relevant sub-image content back into an interleaved, multimodal chain of thought. In contrast to prior approaches limited by the performance ceiling of specialized tools, Ophiuchus integrates the model's inherent grounding and perception capabilities with external tools, thereby fostering higher-level reasoning. The core of our method is a three-stage training strategy: cold-start training with tool-integrated reasoning data to achieve basic tool selection and adaptation for inspecting key regions; self-reflection fine-tuning to strengthen reflective reasoning and encourage revisiting tool outputs; and Agentic Tool Reinforcement Learning to directly optimize task-specific rewards and emulate expert-like diagnostic behavior. Extensive experiments show that Ophiuchus consistently outperforms both closed-source and open-source SOTA methods across diverse medical benchmarks, including VQA, detection, and reasoning-based segmentation. Our approach illuminates a path toward medical AI agents that can genuinely "think with images" through tool-integrated reasoning. Datasets, codes, and trained models will be released publicly.
Probing the Critical Point (CritPt) of AI Reasoning: a Frontier Physics Research Benchmark
Oct 01, 2025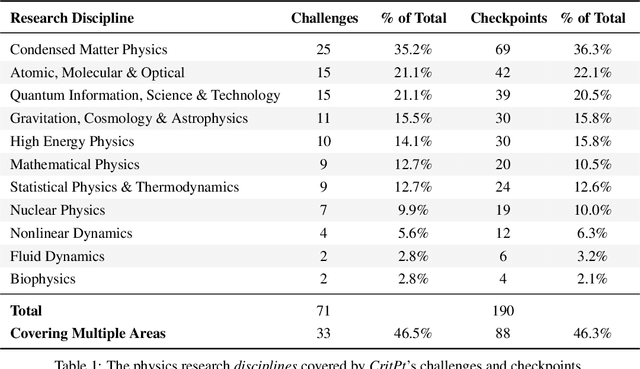



While large language models (LLMs) with reasoning capabilities are progressing rapidly on high-school math competitions and coding, can they reason effectively through complex, open-ended challenges found in frontier physics research? And crucially, what kinds of reasoning tasks do physicists want LLMs to assist with? To address these questions, we present the CritPt (Complex Research using Integrated Thinking - Physics Test, pronounced "critical point"), the first benchmark designed to test LLMs on unpublished, research-level reasoning tasks that broadly covers modern physics research areas, including condensed matter, quantum physics, atomic, molecular & optical physics, astrophysics, high energy physics, mathematical physics, statistical physics, nuclear physics, nonlinear dynamics, fluid dynamics and biophysics. CritPt consists of 71 composite research challenges designed to simulate full-scale research projects at the entry level, which are also decomposed to 190 simpler checkpoint tasks for more fine-grained insights. All problems are newly created by 50+ active physics researchers based on their own research. Every problem is hand-curated to admit a guess-resistant and machine-verifiable answer and is evaluated by an automated grading pipeline heavily customized for advanced physics-specific output formats. We find that while current state-of-the-art LLMs show early promise on isolated checkpoints, they remain far from being able to reliably solve full research-scale challenges: the best average accuracy among base models is only 4.0% , achieved by GPT-5 (high), moderately rising to around 10% when equipped with coding tools. Through the realistic yet standardized evaluation offered by CritPt, we highlight a large disconnect between current model capabilities and realistic physics research demands, offering a foundation to guide the development of scientifically grounded AI tools.