 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClinDEF: A Dynamic Evaluation Framework for Large Language Models in Clinical Reasoning
Dec 29, 2025Clinical diagnosis begins with doctor-patient interaction, during which physicians iteratively gather information, determine examination and refine differential diagnosis through patients' response. This dynamic clinical-reasoning process is poorly represented by existing LLM benchmarks that focus on static question-answering. To mitigate these gaps, recent methods explore dynamic medical frameworks involving interactive clinical dialogues. Although effective, they often rely on limited, contamination-prone datasets and lack granular, multi-level evaluation. In this work, we propose ClinDEF, a dynamic framework for assessing clinical reasoning in LLMs through simulated diagnostic dialogues. Grounded in a disease knowledge graph, our method dynamically generates patient cases and facilitates multi-turn interactions between an LLM-based doctor and an automated patient agent. Our evaluation protocol goes beyond diagnostic accuracy by incorporating fine-grained efficiency analysis and rubric-based assessment of diagnostic quality. Experiments show that ClinDEF effectively exposes critical clinical reasoning gaps in state-of-the-art LLMs, offering a more nuanced and clinically meaningful evaluation paradigm.
3SGen: Unified Subject, Style, and Structure-Driven Image Generation with Adaptive Task-specific Memory
Dec 22, 2025



Recent image generation approaches often address subject, style, and structure-driven conditioning in isolation, leading to feature entanglement and limited task transferability. In this paper, we introduce 3SGen, a task-aware unified framework that performs all three conditioning modes within a single model. 3SGen employs an MLLM equipped with learnable semantic queries to align text-image semantics, complemented by a VAE branch that preserves fine-grained visual details. At its core, an Adaptive Task-specific Memory (ATM) module dynamically disentangles, stores, and retrieves condition-specific priors, such as identity for subjects, textures for styles, and spatial layouts for structures, via a lightweight gating mechanism along with several scalable memory items. This design mitigates inter-task interference and naturally scales to compositional inputs. In addition, we propose 3SGen-Bench, a unified image-driven generation benchmark with standardized metrics for evaluating cross-task fidelity and controllability. Extensive experiments on our proposed 3SGen-Bench and other public benchmarks demonstrate our superior performance across diverse image-driven generation tasks.
Ming-Omni: A Unified Multimodal Model for Perception and Generation
Jun 11, 2025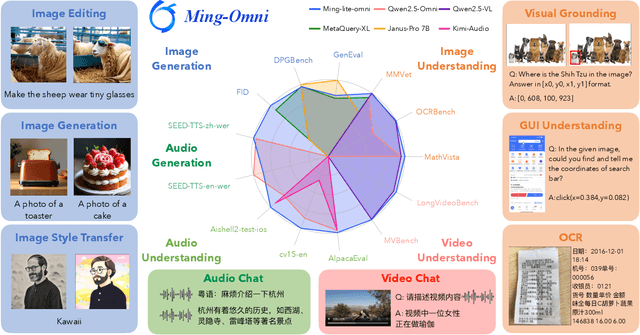
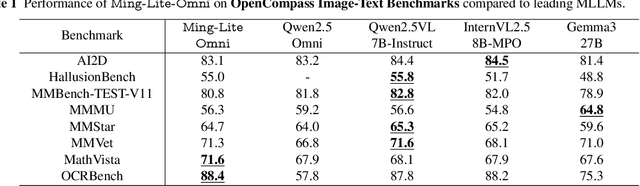
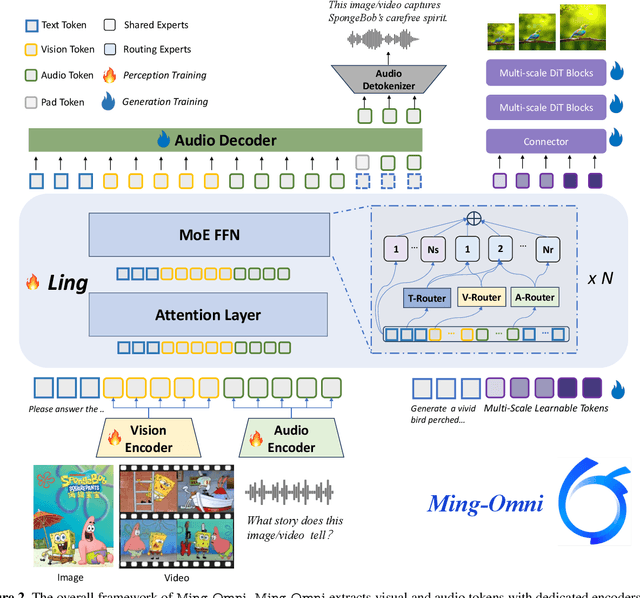
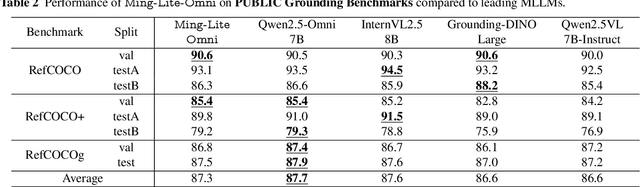
We propose Ming-Omni, a unified multimodal model capable of processing images, text, audio, and video, while demonstrating strong proficiency in both speech and image generation. Ming-Omni employs dedicated encoders to extract tokens from different modalities, which are then processed by Ling, an MoE architecture equipped with newly proposed modality-specific routers. This design enables a single model to efficiently process and fuse multimodal inputs within a unified framework, thereby facilitating diverse tasks without requiring separate models, task-specific fine-tuning, or structural redesign. Importantly, Ming-Omni extends beyond conventional multimodal models by supporting audio and image generation. This is achieved through the integration of an advanced audio decoder for natural-sounding speech and Ming-Lite-Uni for high-quality image generation, which also allow the model to engage in context-aware chatting, perform text-to-speech conversion, and conduct versatile image editing. Our experimental results showcase Ming-Omni offers a powerful solution for unified perception and generation across all modalities. Notably, our proposed Ming-Omni is the first open-source model we are aware of to match GPT-4o in modality support, and we release all code and model weights to encourage further research and development in the community.
Ming-Lite-Uni: Advancements in Unified Architecture for Natural Multimodal Interaction
May 05, 2025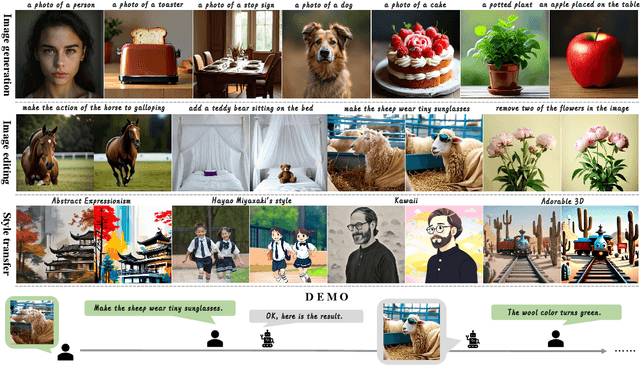

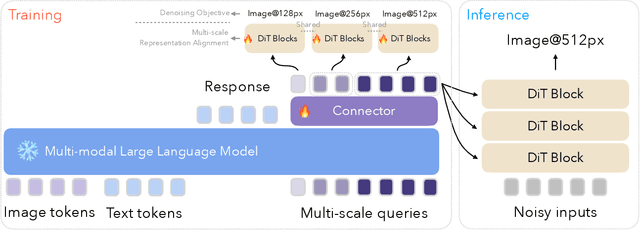
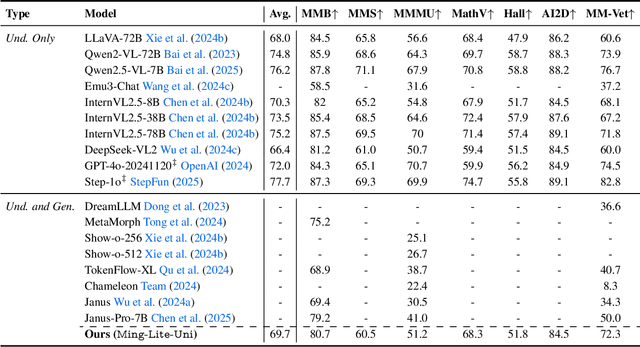
We introduce Ming-Lite-Uni, an open-source multimodal framework featuring a newly designed unified visual generator and a native multimodal autoregressive model tailored for unifying vision and language. Specifically, this project provides an open-source implementation of the integrated MetaQueries and M2-omni framework, while introducing the novel multi-scale learnable tokens and multi-scale representation alignment strategy. By leveraging a fixed MLLM and a learnable diffusion model, Ming-Lite-Uni enables native multimodal AR models to perform both text-to-image generation and instruction based image editing tasks, expanding their capabilities beyond pure visual understanding. Our experimental results demonstrate the strong performance of Ming-Lite-Uni and illustrate the impressive fluid nature of its interactive process. All code and model weights are open-sourced to foster further exploration within the community. Notably, this work aligns with concurrent multimodal AI milestones - such as ChatGPT-4o with native image generation updated in March 25, 2025 - underscoring the broader significance of unified models like Ming-Lite-Uni on the path toward AGI. Ming-Lite-Uni is in alpha stage and will soon be further refined.
StructuredMesh: 3D Structured Optimization of Façade Components on Photogrammetric Mesh Models using Binary Integer Programming
Jun 07, 2023



The lack of fa\c{c}ade structures in photogrammetric mesh models renders them inadequate for meeting the demands of intricate applications. Moreover, these mesh models exhibit irregular surfaces with considerable geometric noise and texture quality imperfections, making the restoration of structures challenging. To address these shortcomings, we present StructuredMesh, a novel approach for reconstructing fa\c{c}ade structures conforming to the regularity of buildings within photogrammetric mesh models. Our method involves capturing multi-view color and depth images of the building model using a virtual camera and employing a deep learning object detection pipeline to semi-automatically extract the bounding boxes of fa\c{c}ade components such as windows, doors, and balconies from the color image. We then utilize the depth image to remap these boxes into 3D space, generating an initial fa\c{c}ade layout. Leveraging architectural knowledge, we apply binary integer programming (BIP) to optimize the 3D layout's structure, encompassing the positions, orientations, and sizes of all components. The refined layout subsequently informs fa\c{c}ade modeling through instance replacement. We conducted experiments utilizing building mesh models from three distinct datasets, demonstrating the adaptability, robustness, and noise resistance of our proposed methodology. Furthermore, our 3D layout evaluation metrics reveal that the optimized layout enhances precision, recall, and F-score by 6.5%, 4.5%, and 5.5%, respectively, in comparison to the initial layout.
Semantic Image Translation for Repairing the Texture Defects of Building Models
Apr 01, 2023The accurate representation of 3D building models in urban environments is significantly hindered by challenges such as texture occlusion, blurring, and missing details, which are difficult to mitigate through standard photogrammetric texture mapping pipelines. Current image completion methods often struggle to produce structured results and effectively handle the intricate nature of highly-structured fa\c{c}ade textures with diverse architectural styles. Furthermore, existing image synthesis methods encounter difficulties in preserving high-frequency details and artificial regular structures, which are essential for achieving realistic fa\c{c}ade texture synthesis. To address these challenges, we introduce a novel approach for synthesizing fa\c{c}ade texture images that authentically reflect the architectural style from a structured label map, guided by a ground-truth fa\c{c}ade image. In order to preserve fine details and regular structures, we propose a regularity-aware multi-domain method that capitalizes on frequency information and corner maps. We also incorporate SEAN blocks into our generator to enable versatile style transfer. To generate plausible structured images without undesirable regions, we employ image completion techniques to remove occlusions according to semantics prior to image inference. Our proposed method is also capable of synthesizing texture images with specific styles for fa\c{c}ades that lack pre-existing textures, using manually annotated labels. Experimental results on publicly available fa\c{c}ade image and 3D model datasets demonstrate that our method yields superior results and effectively addresses issues associated with flawed textures. The code and datasets will be made publicly available for further research and development.
Double Graphs Regularized Multi-view Subspace Clustering
Sep 30, 2022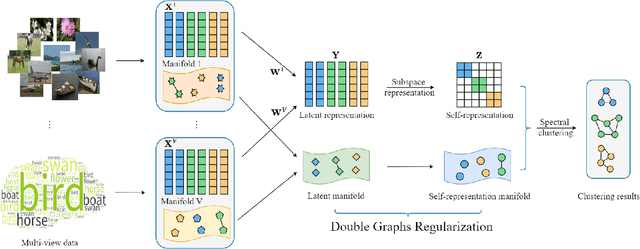

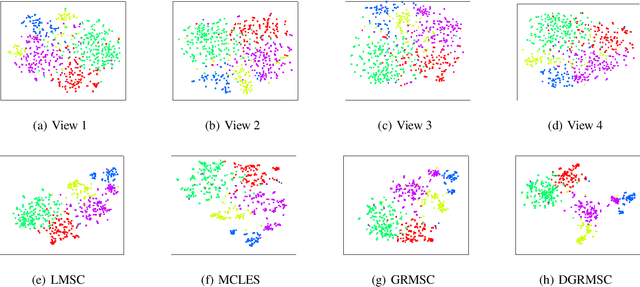
Recent years have witnessed a growing academic interest in multi-view subspace clustering. In this paper, we propose a novel Double Graphs Regularized Multi-view Subspace Clustering (DGRMSC) method, which aims to harness both global and local structural information of multi-view data in a unified framework. Specifically, DGRMSC firstly learns a latent representation to exploit the global complementary information of multiple views. Based on the learned latent representation, we learn a self-representation to explore its global cluster structure. Further, Double Graphs Regularization (DGR) is performed on both latent representation and self-representation to take advantage of their local manifold structures simultaneously. Then, we design an iterative algorithm to solve the optimization problem effectively. Extensive experimental results on real-world datasets demonstrate the effectiveness of the proposed method.
Global Weighted Tensor Nuclear Norm for Tensor Robust Principal Component Analysis
Sep 28, 2022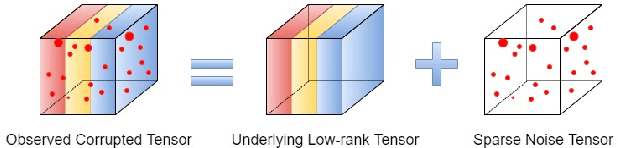
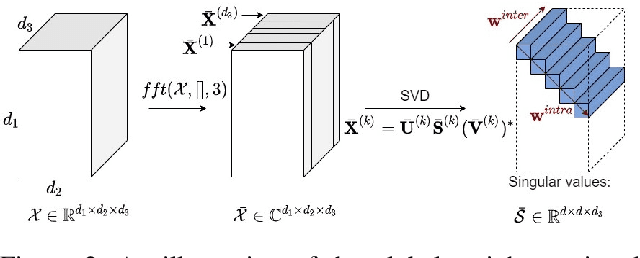
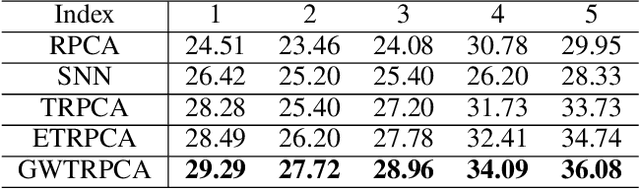
Tensor Robust Principal Component Analysis (TRPCA), which aims to recover a low-rank tensor corrupted by sparse noise, has attracted much attention in many real applications. This paper develops a new Global Weighted TRPCA method (GWTRPCA), which is the first approach simultaneously considers the significance of intra-frontal slice and inter-frontal slice singular values in the Fourier domain. Exploiting this global information, GWTRPCA penalizes the larger singular values less and assigns smaller weights to them. Hence, our method can recover the low-tubal-rank components more exactly. Moreover, we propose an effective adaptive weight learning strategy by a Modified Cauchy Estimator (MCE) since the weight setting plays a crucial role in the success of GWTRPCA. To implement the GWTRPCA method, we devise an optimization algorithm using an Alternating Direction Method of Multipliers (ADMM) method. Experiments on real-world datasets validate the effectiveness of our proposed method.
Asymmetrical Vertical Federated Learning
Apr 30, 2020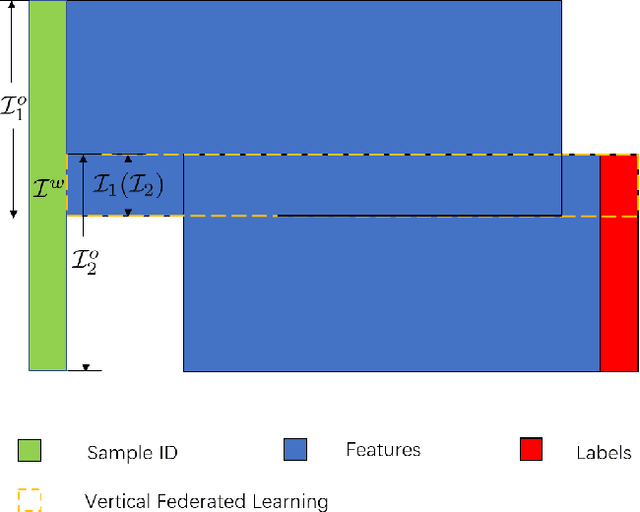


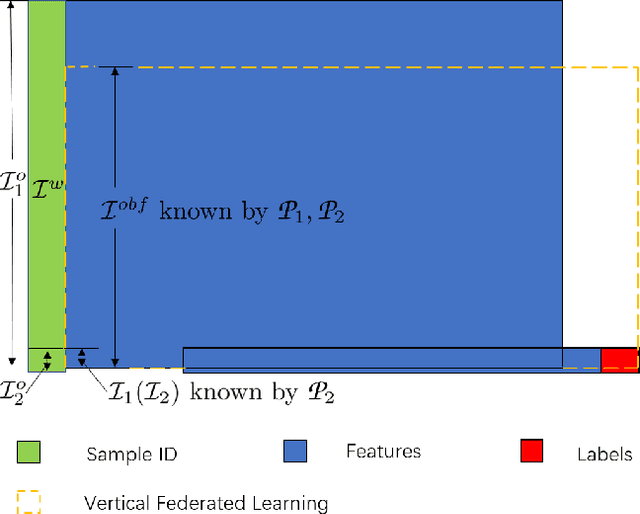
Federated learning is a distributed machine learning method that aims to preserve the privacy of sample features and labels. In a federated learning system, ID-based sample alignment approaches are usually applied with few efforts made on the protection of ID privacy. In real-life applications, however, the confidentiality of sample IDs, which are the strongest row identifiers, is also drawing much attention from many participants. To relax their privacy concerns about ID privacy, this paper formally proposes the notion of asymmetrical vertical federated learning and illustrates the way to protect sample IDs. The standard private set intersection protocol is adapted to achieve the asymmetrical ID alignment phase in an asymmetrical vertical federated learning system. Correspondingly, a Pohlig-Hellman realization of the adapted protocol is provided. This paper also presents a genuine with dummy approach to achieving asymmetrical federated model training. To illustrate its application, a federated logistic regression algorithm is provided as an example. Experiments are also made for validating the feasibility of this approach.
Fast and Regularized Reconstruction of Building Façades from Street-View Images using Binary Integer Programming
Feb 20, 2020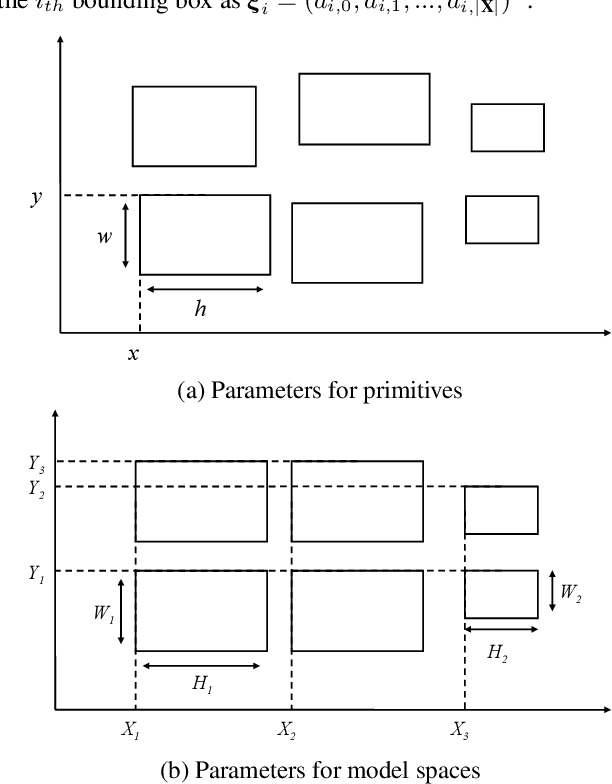
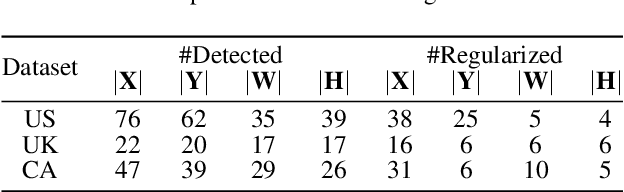
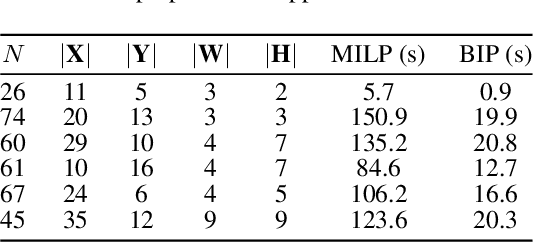

Regularized arrangement of primitives on building fa\c{c}ades to aligned locations and consistent sizes is important towards structured reconstruction of urban environment. Mixed integer linear programing was used to solve the problem, however, it is extreamly time consuming even for state-of-the-art commercial solvers. Aiming to alleviate this issue, we cast the problem into binary integer programming, which omits the requirements for real value parameters and is more efficient to be solved . Firstly, the bounding boxes of the primitives are detected using the YOLOv3 architecture in real-time. Secondly, the coordinates of the upper left corners and the sizes of the bounding boxes are automatically clustered in a binary integer programming optimization, which jointly considers the geometric fitness, regularity and additional constraints; this step does not require \emph{a priori} knowledge, such as the number of clusters or pre-defined grammars. Finally, the regularized bounding boxes can be directly used to guide the fa\c{c}ade reconstruction in an interactive envinronment. Experimental evaluations have revealed that the accuracies for the extraction of primitives are above 0.85, which is sufficient for the following 3D reconstruction. The proposed approach only takes about $ 10\% $ to $ 20\% $ of the runtime than previous approach and reduces the diversity of the bounding boxes to about $20\%$ to $50\%$