 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLongAV-Compass: Towards Unified Evaluation of Minute-Scale Audio-Visual Generation Across T2AV, I2AV, and V2AV
May 25, 2026Audio-visual generation is rapidly advancing from short clips to minute-long content, while existing evaluation protocols remain largely confined to short-form settings. Existing benchmarks primarily focus on 5--10 second text-conditioned generation and rarely support unified evaluation across text, image, and video conditioning modalities. Moreover, they provide limited insight into how identity consistency, narrative coherence, and audio-visual alignment degrade over extended temporal horizons. To bridge this gap, we introduce LongAV-Compass, a systematic benchmark for minute-long audio-visual generation. LongAV-Compass contains 284 curated test cases spanning text-to-audio-video (T2AV), image-to-audio-video (I2AV), and video-to-audio-video (V2AV), organized by application scenario and generation complexity. The benchmark combines taxonomy-guided benchmark construction with a unified evaluation framework that integrates MLLM-assisted assessment with complementary perceptual and multimodal metrics, including DINO-v2, ArcFace, CLIP, and ImageBind. The framework evaluates more than 20 fine-grained dimensions covering within-segment quality, cross-segment consistency, global narrative coherence, semantic alignment, and audio-visual synchronization. Through experiments on 11 representative models together with human-alignment validation, LongAV-Compass provides a diagnostic testbed for analyzing the limitations of current systems in sustaining coherent, semantically aligned, and temporally consistent minute-scale audio-visual generation across diverse input modalities.
Artifact-Bench: Evaluating MLLMs on Detecting and Assessing the Artifacts of AI-Generated Videos
May 18, 2026Recent video generative models have greatly improved the realism of AI-generated videos, yet their outputs still exhibit artifacts such as temporal inconsistencies, structural distortions, and semantic incoherence. While Multimodal Large Language Models (MLLMs) show strong visual understanding capabilities, their ability to perceive and reason about such artifacts remains unclear. Existing benchmarks often lack systematic evaluation of artifact-aware perception and fine-grained diagnostic reasoning, especially across diverse AI-generated video domains beyond photorealistic content. To address this gap, we introduce Artifact-Bench, a comprehensive benchmark for evaluating MLLMs on AI-generated video artifact detection and analysis. We first establish a three-level hierarchical taxonomy of realism artifacts, covering photorealistic, animated, and CG-style videos. Based on this taxonomy, Artifact-Bench defines three complementary tasks: real vs. AI-generated video classification, pairwise realism comparison, and fine-grained artifact identification. Experiments on 19 leading MLLMs reveal substantial limitations in artifact perception and reasoning, with many models approaching random or even below-random performance in challenging settings. We further observe significant misalignment between MLLM judgments and human perceptual preferences, highlighting their limited reliability as general evaluators for AI-generated video realism.
Agentic-MME: What Agentic Capability Really Brings to Multimodal Intelligence?
Apr 03, 2026Multimodal Large Language Models (MLLMs) are evolving from passive observers into active agents, solving problems through Visual Expansion (invoking visual tools) and Knowledge Expansion (open-web search). However, existing evaluations fall short: they lack flexible tool integration, test visual and search tools separately, and evaluate primarily by final answers. Consequently, they cannot verify if tools were actually invoked, applied correctly, or used efficiently. To address this, we introduce Agentic-MME, a process-verified benchmark for Multimodal Agentic Capabilities. It contains 418 real-world tasks across 6 domains and 3 difficulty levels to evaluate capability synergy, featuring over 2,000 stepwise checkpoints that average 10+ person-hours of manual annotation per task. Each task includes a unified evaluation framework supporting sandboxed code and APIs, alongside a human reference trajectory annotated with stepwise checkpoints along dual-axis: S-axis and V-axis. To enable true process-level verification, we audit fine-grained intermediate states rather than just final answers, and quantify efficiency via an overthinking metric relative to human trajectories. Experimental results show the best model, Gemini3-pro, achieves 56.3% overall accuracy, which falls significantly to 23.0% on Level-3 tasks, underscoring the difficulty of real-world multimodal agentic problem solving.
Graph-Structured Deep Learning Framework for Multi-task Contention Identification with High-dimensional Metrics
Jan 28, 2026This study addresses the challenge of accurately identifying multi-task contention types in high-dimensional system environments and proposes a unified contention classification framework that integrates representation transformation, structural modeling, and a task decoupling mechanism. The method first constructs system state representations from high-dimensional metric sequences, applies nonlinear transformations to extract cross-dimensional dynamic features, and integrates multiple source information such as resource utilization, scheduling behavior, and task load variations within a shared representation space. It then introduces a graph-based modeling mechanism to capture latent dependencies among metrics, allowing the model to learn competitive propagation patterns and structural interference across resource links. On this basis, task-specific mapping structures are designed to model the differences among contention types and enhance the classifier's ability to distinguish multiple contention patterns. To achieve stable performance, the method employs an adaptive multi-task loss weighting strategy that balances shared feature learning with task-specific feature extraction and generates final contention predictions through a standardized inference process. Experiments conducted on a public system trace dataset demonstrate advantages in accuracy, recall, precision, and F1, and sensitivity analyses on batch size, training sample scale, and metric dimensionality further confirm the model's stability and applicability. The study shows that structured representations and multi-task classification based on high-dimensional metrics can significantly improve contention pattern recognition and offer a reliable technical approach for performance management in complex computing environments.
Vision-Language Introspection: Mitigating Overconfident Hallucinations in MLLMs via Interpretable Bi-Causal Steering
Jan 08, 2026Object hallucination critically undermines the reliability of Multimodal Large Language Models, often stemming from a fundamental failure in cognitive introspection, where models blindly trust linguistic priors over specific visual evidence. Existing mitigations remain limited: contrastive decoding approaches operate superficially without rectifying internal semantic misalignments, while current latent steering methods rely on static vectors that lack instance-specific precision. We introduce Vision-Language Introspection (VLI), a training-free inference framework that simulates a metacognitive self-correction process. VLI first performs Attributive Introspection to diagnose hallucination risks via probabilistic conflict detection and localize the causal visual anchors. It then employs Interpretable Bi-Causal Steering to actively modulate the inference process, dynamically isolating visual evidence from background noise while neutralizing blind confidence through adaptive calibration. VLI achieves state-of-the-art performance on advanced models, reducing object hallucination rates by 12.67% on MMHal-Bench and improving accuracy by 5.8% on POPE.
ClinDEF: A Dynamic Evaluation Framework for Large Language Models in Clinical Reasoning
Dec 29, 2025Clinical diagnosis begins with doctor-patient interaction, during which physicians iteratively gather information, determine examination and refine differential diagnosis through patients' response. This dynamic clinical-reasoning process is poorly represented by existing LLM benchmarks that focus on static question-answering. To mitigate these gaps, recent methods explore dynamic medical frameworks involving interactive clinical dialogues. Although effective, they often rely on limited, contamination-prone datasets and lack granular, multi-level evaluation. In this work, we propose ClinDEF, a dynamic framework for assessing clinical reasoning in LLMs through simulated diagnostic dialogues. Grounded in a disease knowledge graph, our method dynamically generates patient cases and facilitates multi-turn interactions between an LLM-based doctor and an automated patient agent. Our evaluation protocol goes beyond diagnostic accuracy by incorporating fine-grained efficiency analysis and rubric-based assessment of diagnostic quality. Experiments show that ClinDEF effectively exposes critical clinical reasoning gaps in state-of-the-art LLMs, offering a more nuanced and clinically meaningful evaluation paradigm.
LightMem: Lightweight and Efficient Memory-Augmented Generation
Oct 21, 2025



Despite their remarkable capabilities, Large Language Models (LLMs) struggle to effectively leverage historical interaction information in dynamic and complex environments. Memory systems enable LLMs to move beyond stateless interactions by introducing persistent information storage, retrieval, and utilization mechanisms. However, existing memory systems often introduce substantial time and computational overhead. To this end, we introduce a new memory system called LightMem, which strikes a balance between the performance and efficiency of memory systems. Inspired by the Atkinson-Shiffrin model of human memory, LightMem organizes memory into three complementary stages. First, cognition-inspired sensory memory rapidly filters irrelevant information through lightweight compression and groups information according to their topics. Next, topic-aware short-term memory consolidates these topic-based groups, organizing and summarizing content for more structured access. Finally, long-term memory with sleep-time update employs an offline procedure that decouples consolidation from online inference. Experiments on LongMemEval with GPT and Qwen backbones show that LightMem outperforms strong baselines in accuracy (up to 10.9% gains) while reducing token usage by up to 117x, API calls by up to 159x, and runtime by over 12x. The code is available at https://github.com/zjunlp/LightMem.
SciCUEval: A Comprehensive Dataset for Evaluating Scientific Context Understanding in Large Language Models
May 21, 2025


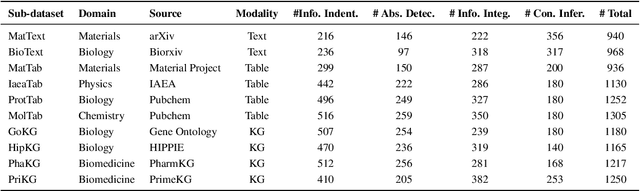
Large Language Models (LLMs) have shown impressive capabilities in contextual understanding and reasoning. However, evaluating their performance across diverse scientific domains remains underexplored, as existing benchmarks primarily focus on general domains and fail to capture the intricate complexity of scientific data. To bridge this gap, we construct SciCUEval, a comprehensive benchmark dataset tailored to assess the scientific context understanding capability of LLMs. It comprises ten domain-specific sub-datasets spanning biology, chemistry, physics, biomedicine, and materials science, integrating diverse data modalities including structured tables, knowledge graphs, and unstructured texts. SciCUEval systematically evaluates four core competencies: Relevant information identification, Information-absence detection, Multi-source information integration, and Context-aware inference, through a variety of question formats. We conduct extensive evaluations of state-of-the-art LLMs on SciCUEval, providing a fine-grained analysis of their strengths and limitations in scientific context understanding, and offering valuable insights for the future development of scientific-domain LLMs.