 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistilling Object Detectors with Task Adaptive Regularization
Jun 23, 2020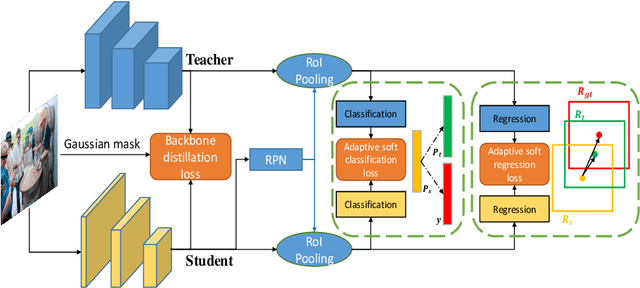
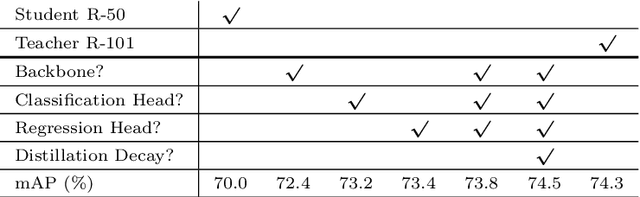


Current state-of-the-art object detectors are at the expense of high computational costs and are hard to deploy to low-end devices. Knowledge distillation, which aims at training a smaller student network by transferring knowledge from a larger teacher model, is one of the promising solutions for model miniaturization. In this paper, we investigate each module of a typical detector in depth, and propose a general distillation framework that adaptively transfers knowledge from teacher to student according to the task specific priors. The intuition is that simply distilling all information from teacher to student is not advisable, instead we should only borrow priors from the teacher model where the student cannot perform well. Towards this goal, we propose a region proposal sharing mechanism to interflow region responses between the teacher and student models. Based on this, we adaptively transfer knowledge at three levels, \emph{i.e.}, feature backbone, classification head, and bounding box regression head, according to which model performs more reasonably. Furthermore, considering that it would introduce optimization dilemma when minimizing distillation loss and detection loss simultaneously, we propose a distillation decay strategy to help improve model generalization via gradually reducing the distillation penalty. Experiments on widely used detection benchmarks demonstrate the effectiveness of our method. In particular, using Faster R-CNN with FPN as an instantiation, we achieve an accuracy of $39.0\%$ with Resnet-50 on COCO dataset, which surpasses the baseline $36.3\%$ by $2.7\%$ points, and even better than the teacher model with $38.5\%$ mAP.
Cascaded Regression Tracking: Towards Online Hard Distractor Discrimination
Jun 18, 2020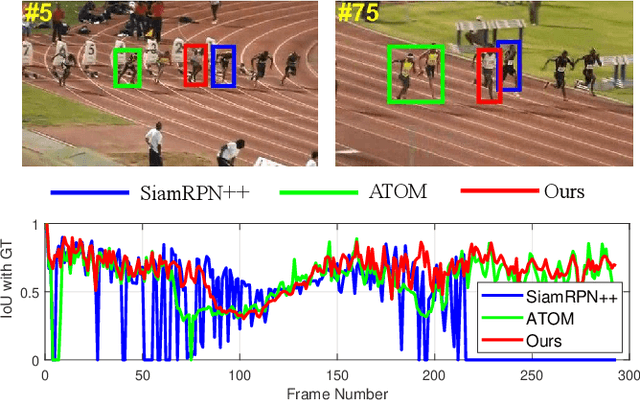
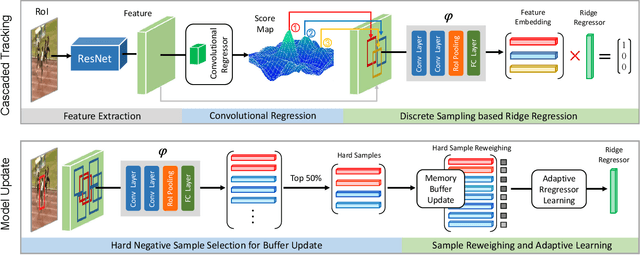
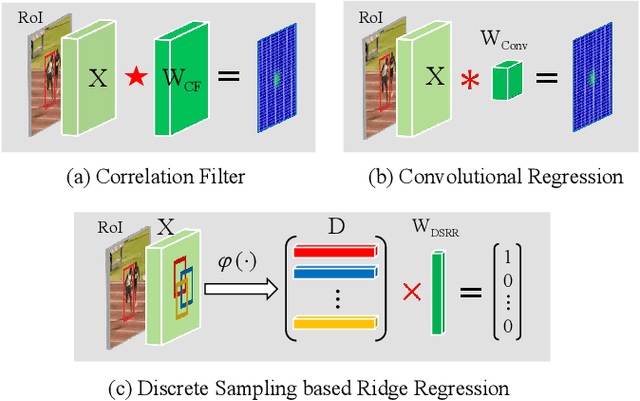
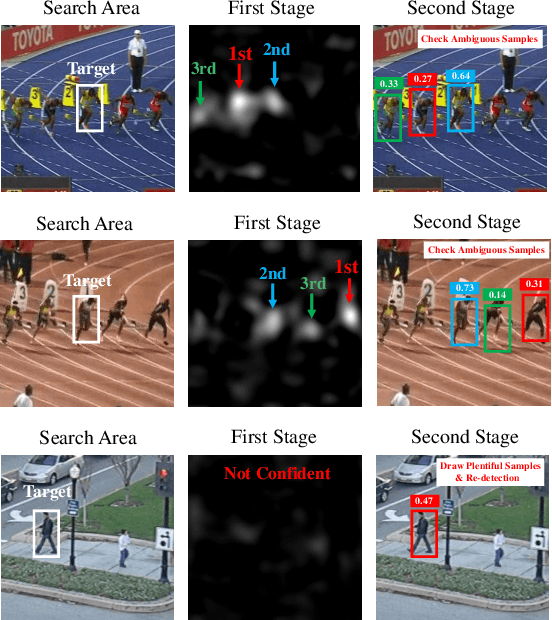
Visual tracking can be easily disturbed by similar surrounding objects. Such objects as hard distractors, even though being the minority among negative samples, increase the risk of target drift and model corruption, which deserve additional attention in online tracking and model update. To enhance the tracking robustness, in this paper, we propose a cascaded regression tracker with two sequential stages. In the first stage, we filter out abundant easily-identified negative candidates via an efficient convolutional regression. In the second stage, a discrete sampling based ridge regression is designed to double-check the remaining ambiguous hard samples, which serves as an alternative of fully-connected layers and benefits from the closed-form solver for efficient learning. Extensive experiments are conducted on 11 challenging tracking benchmarks including OTB-2013, OTB-2015, VOT2018, VOT2019, UAV123, Temple-Color, NfS, TrackingNet, LaSOT, UAV20L, and OxUvA. The proposed method achieves state-of-the-art performance on prevalent benchmarks, while running in a real-time speed.
Rethinking Performance Estimation in Neural Architecture Search
May 20, 2020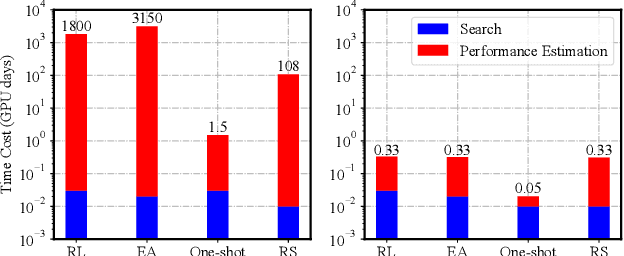
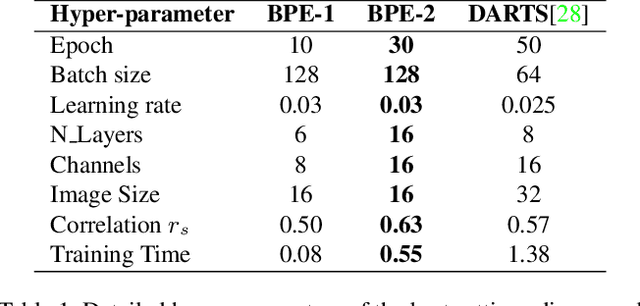
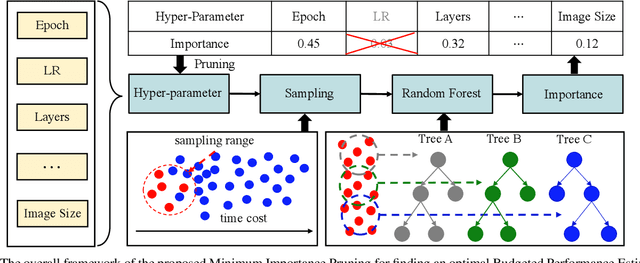
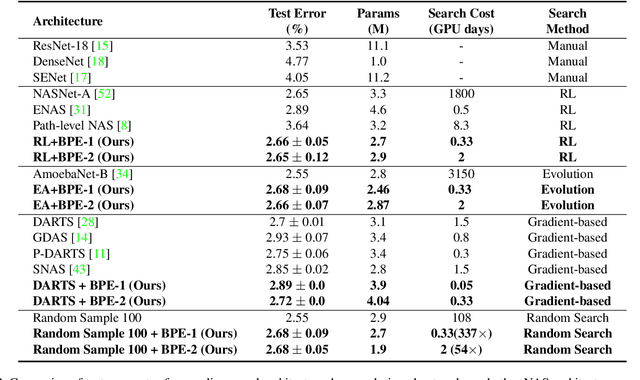
Neural architecture search (NAS) remains a challenging problem, which is attributed to the indispensable and time-consuming component of performance estimation (PE). In this paper, we provide a novel yet systematic rethinking of PE in a resource constrained regime, termed budgeted PE (BPE), which precisely and effectively estimates the performance of an architecture sampled from an architecture space. Since searching an optimal BPE is extremely time-consuming as it requires to train a large number of networks for evaluation, we propose a Minimum Importance Pruning (MIP) approach. Given a dataset and a BPE search space, MIP estimates the importance of hyper-parameters using random forest and subsequently prunes the minimum one from the next iteration. In this way, MIP effectively prunes less important hyper-parameters to allocate more computational resource on more important ones, thus achieving an effective exploration. By combining BPE with various search algorithms including reinforcement learning, evolution algorithm, random search, and differentiable architecture search, we achieve 1, 000x of NAS speed up with a negligible performance drop comparing to the SOTA
A Semi-Supervised Assessor of Neural Architectures
May 14, 2020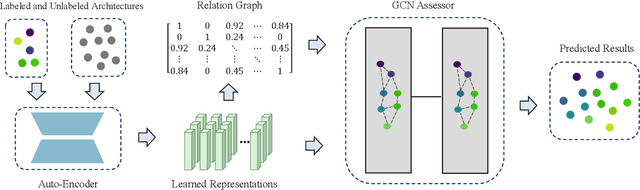
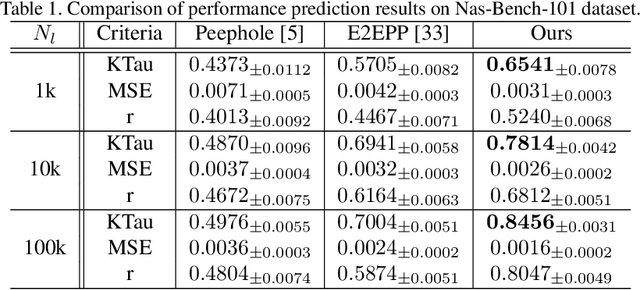
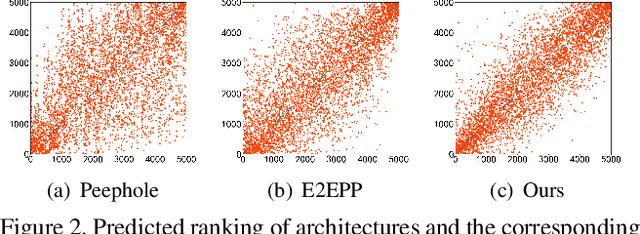
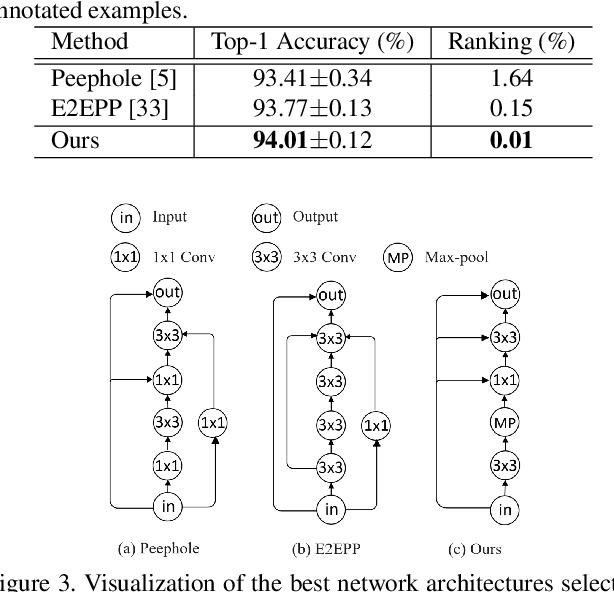
Neural architecture search (NAS) aims to automatically design deep neural networks of satisfactory performance. Wherein, architecture performance predictor is critical to efficiently value an intermediate neural architecture. But for the training of this predictor, a number of neural architectures and their corresponding real performance often have to be collected. In contrast with classical performance predictor optimized in a fully supervised way, this paper suggests a semi-supervised assessor of neural architectures. We employ an auto-encoder to discover meaningful representations of neural architectures. Taking each neural architecture as an individual instance in the search space, we construct a graph to capture their intrinsic similarities, where both labeled and unlabeled architectures are involved. A graph convolutional neural network is introduced to predict the performance of architectures based on the learned representations and their relation modeled by the graph. Extensive experimental results on the NAS-Benchmark-101 dataset demonstrated that our method is able to make a significant reduction on the required fully trained architectures for finding efficient architectures.
Projection & Probability-Driven Black-Box Attack
May 08, 2020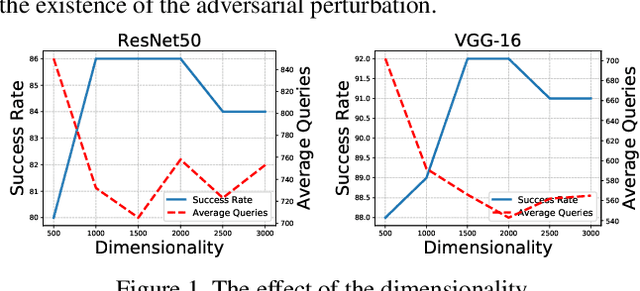

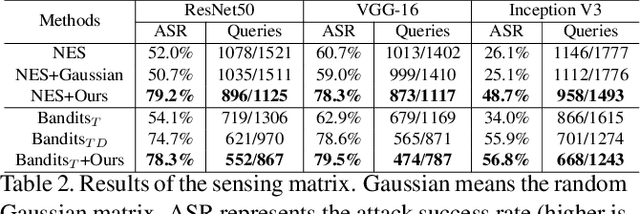
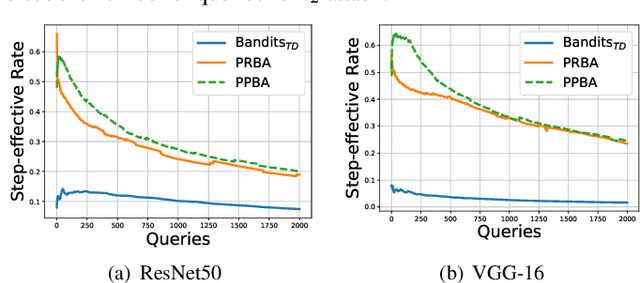
Generating adversarial examples in a black-box setting retains a significant challenge with vast practical application prospects. In particular, existing black-box attacks suffer from the need for excessive queries, as it is non-trivial to find an appropriate direction to optimize in the high-dimensional space. In this paper, we propose Projection & Probability-driven Black-box Attack (PPBA) to tackle this problem by reducing the solution space and providing better optimization. For reducing the solution space, we first model the adversarial perturbation optimization problem as a process of recovering frequency-sparse perturbations with compressed sensing, under the setting that random noise in the low-frequency space is more likely to be adversarial. We then propose a simple method to construct a low-frequency constrained sensing matrix, which works as a plug-and-play projection matrix to reduce the dimensionality. Such a sensing matrix is shown to be flexible enough to be integrated into existing methods like NES and Bandits$_{TD}$. For better optimization, we perform a random walk with a probability-driven strategy, which utilizes all queries over the whole progress to make full use of the sensing matrix for a less query budget. Extensive experiments show that our method requires at most 24% fewer queries with a higher attack success rate compared with state-of-the-art approaches. Finally, the attack method is evaluated on the real-world online service, i.e., Google Cloud Vision API, which further demonstrates our practical potentials.
Deep Multimodal Neural Architecture Search
Apr 25, 2020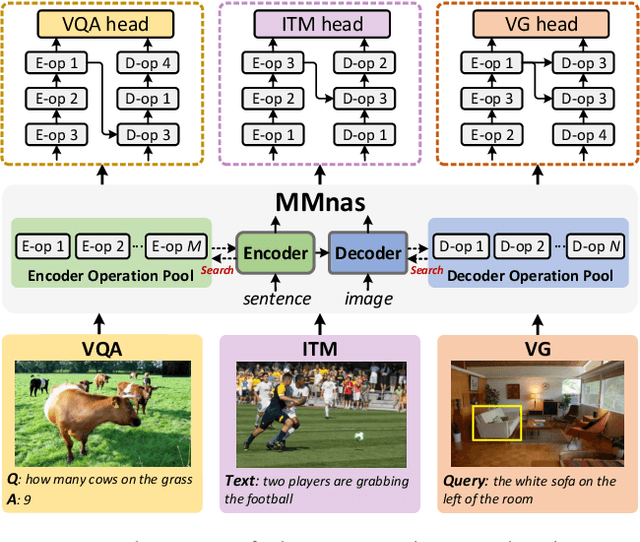
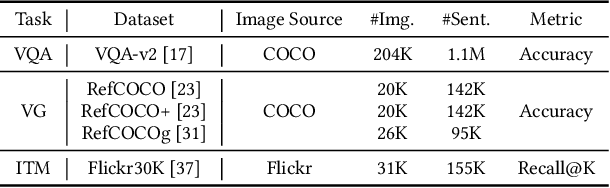
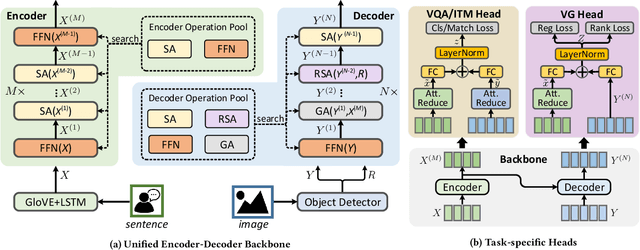
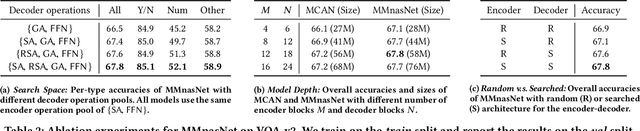
Designing effective neural networks is fundamentally important in deep multimodal learning. Most existing works focus on a single task and design neural architectures manually, which are highly task-specific and hard to generalize to different tasks. In this paper, we devise a generalized deep multimodal neural architecture search (MMnas) framework for various multimodal learning tasks. Given multimodal input, we first define a set of primitive operations, and then construct a deep encoder-decoder based unified backbone, where each encoder or decoder block corresponds to an operation searched from a predefined operation pool. On top of the unified backbone, we attach task-specific heads to tackle different multimodal learning tasks. By using a gradient-based NAS algorithm, the optimal architectures for different tasks are learned efficiently. Extensive ablation studies, comprehensive analysis, and superior experimental results show that MMnasNet significantly outperforms existing state-of-the-art approaches across three multimodal learning tasks (over five datasets), including visual question answering, image-text matching, and visual grounding. Code will be made available.
Fitting the Search Space of Weight-sharing NAS with Graph Convolutional Networks
Apr 17, 2020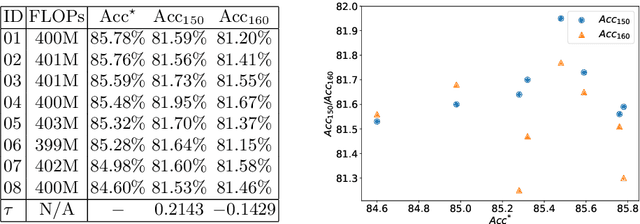
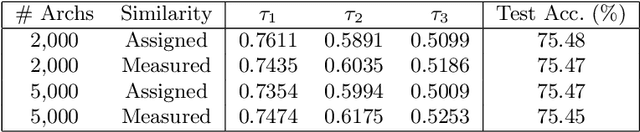
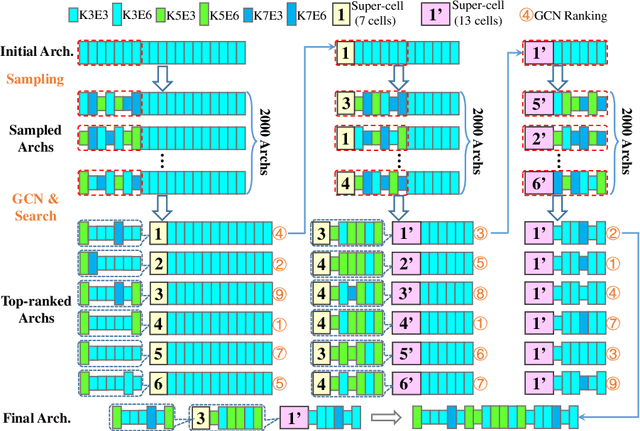
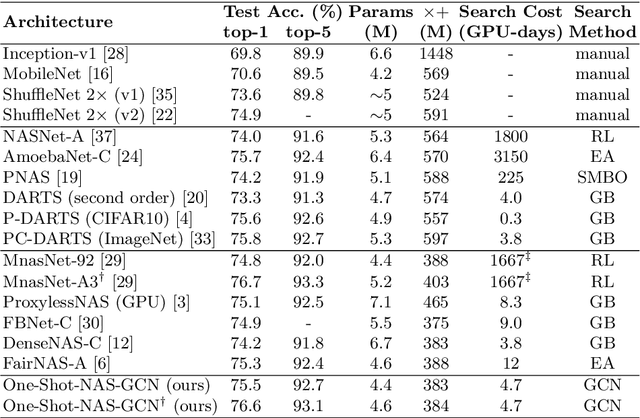
Neural architecture search has attracted wide attentions in both academia and industry. To accelerate it, researchers proposed weight-sharing methods which first train a super-network to reuse computation among different operators, from which exponentially many sub-networks can be sampled and efficiently evaluated. These methods enjoy great advantages in terms of computational costs, but the sampled sub-networks are not guaranteed to be estimated precisely unless an individual training process is taken. This paper owes such inaccuracy to the inevitable mismatch between assembled network layers, so that there is a random error term added to each estimation. We alleviate this issue by training a graph convolutional network to fit the performance of sampled sub-networks so that the impact of random errors becomes minimal. With this strategy, we achieve a higher rank correlation coefficient in the selected set of candidates, which consequently leads to better performance of the final architecture. In addition, our approach also enjoys the flexibility of being used under different hardware constraints, since the graph convolutional network has provided an efficient lookup table of the performance of architectures in the entire search space.
Unsupervised Person Re-identification via Softened Similarity Learning
Apr 07, 2020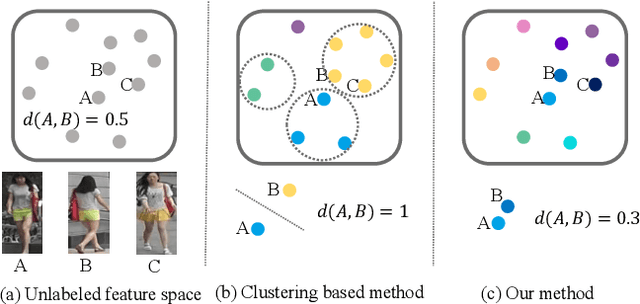
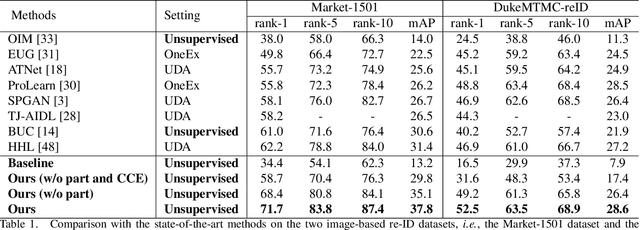
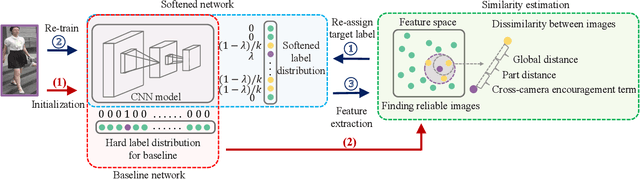
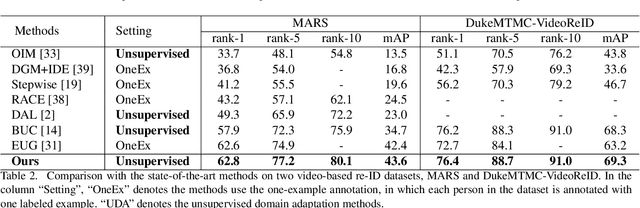
Person re-identification (re-ID) is an important topic in computer vision. This paper studies the unsupervised setting of re-ID, which does not require any labeled information and thus is freely deployed to new scenarios. There are very few studies under this setting, and one of the best approach till now used iterative clustering and classification, so that unlabeled images are clustered into pseudo classes for a classifier to get trained, and the updated features are used for clustering and so on. This approach suffers two problems, namely, the difficulty of determining the number of clusters, and the hard quantization loss in clustering. In this paper, we follow the iterative training mechanism but discard clustering, since it incurs loss from hard quantization, yet its only product, image-level similarity, can be easily replaced by pairwise computation and a softened classification task. With these improvements, our approach becomes more elegant and is more robust to hyper-parameter changes. Experiments on two image-based and video-based datasets demonstrate state-of-the-art performance under the unsupervised re-ID setting.
Network Adjustment: Channel Search Guided by FLOPs Utilization Ratio
Apr 06, 2020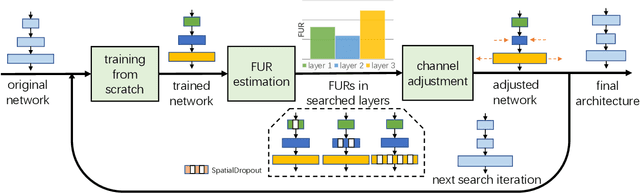
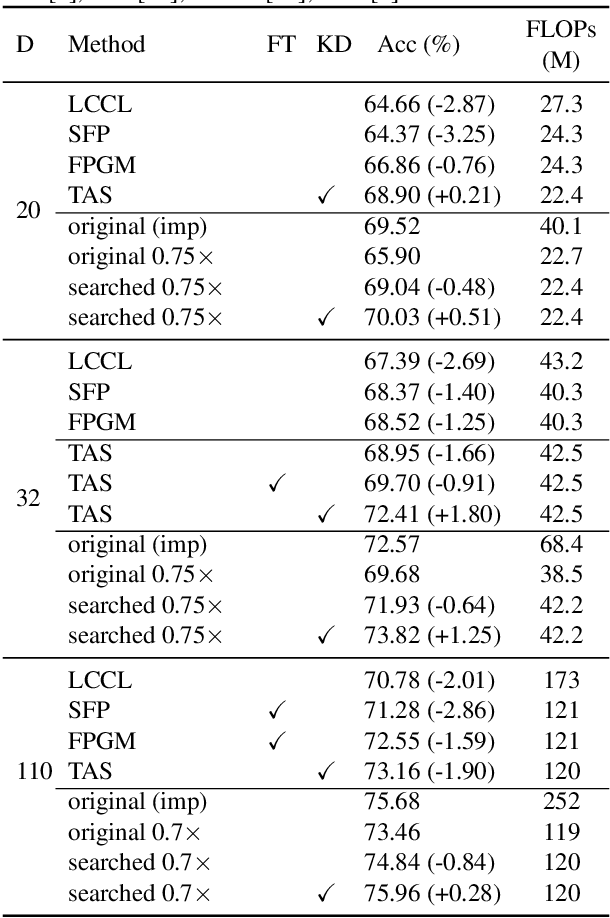
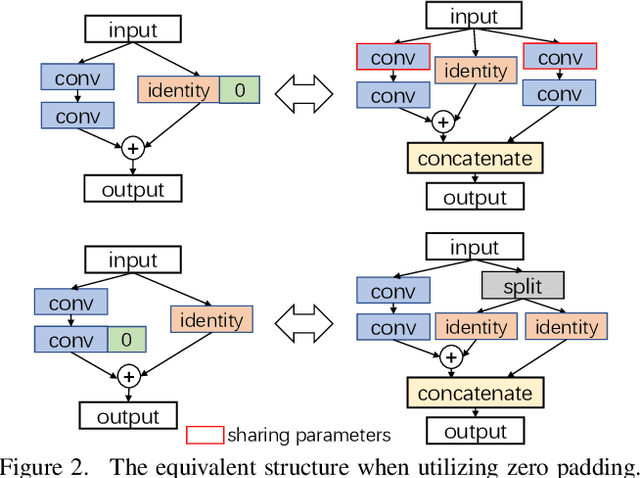
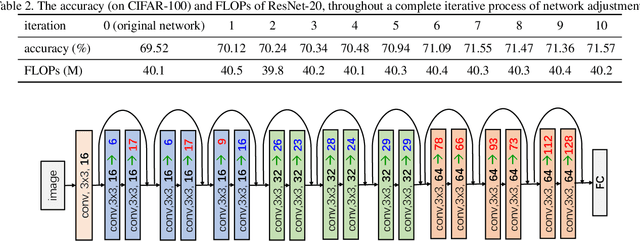
Automatic designing computationally efficient neural networks has received much attention in recent years. Existing approaches either utilize network pruning or leverage the network architecture search methods. This paper presents a new framework named network adjustment, which considers network accuracy as a function of FLOPs, so that under each network configuration, one can estimate the FLOPs utilization ratio (FUR) for each layer and use it to determine whether to increase or decrease the number of channels on the layer. Note that FUR, like the gradient of a non-linear function, is accurate only in a small neighborhood of the current network. Hence, we design an iterative mechanism so that the initial network undergoes a number of steps, each of which has a small `adjusting rate' to control the changes to the network. The computational overhead of the entire search process is reasonable, i.e., comparable to that of re-training the final model from scratch. Experiments on standard image classification datasets and a wide range of base networks demonstrate the effectiveness of our approach, which consistently outperforms the pruning counterpart. The code is available at https://github.com/danczs/NetworkAdjustment.
Attribute Mix: Semantic Data Augmentation for Fine Grained Recognition
Apr 06, 2020

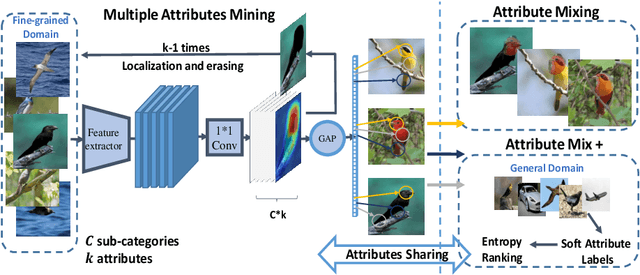

Collecting fine-grained labels usually requires expert-level domain knowledge and is prohibitive to scale up. In this paper, we propose Attribute Mix, a data augmentation strategy at attribute level to expand the fine-grained samples. The principle lies in that attribute features are shared among fine-grained sub-categories, and can be seamlessly transferred among images. Toward this goal, we propose an automatic attribute mining approach to discover attributes that belong to the same super-category, and Attribute Mix is operated by mixing semantically meaningful attribute features from two images. Attribute Mix is a simple but effective data augmentation strategy that can significantly improve the recognition performance without increasing the inference budgets. Furthermore, since attributes can be shared among images from the same super-category, we further enrich the training samples with attribute level labels using images from the generic domain. Experiments on widely used fine-grained benchmarks demonstrate the effectiveness of our proposed method. Specifically, without any bells and whistles, we achieve accuracies of $90.2\%$, $93.1\%$ and $94.9\%$ on CUB-200-2011, FGVC-Aircraft and Standford Cars, respectively.