 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCASEIN: Cascading Explicit and Implicit Control for Fine-grained Emotion Intensity Regulation
Jun 27, 2023



Existing fine-grained intensity regulation methods rely on explicit control through predicted emotion probabilities. However, these high-level semantic probabilities are often inaccurate and unsmooth at the phoneme level, leading to bias in learning. Especially when we attempt to mix multiple emotion intensities for specific phonemes, resulting in markedly reduced controllability and naturalness of the synthesis. To address this issue, we propose the CAScaded Explicit and Implicit coNtrol framework (CASEIN), which leverages accurate disentanglement of emotion manifolds from the reference speech to learn the implicit representation at a lower semantic level. This representation bridges the semantical gap between explicit probabilities and the synthesis model, reducing bias in learning. In experiments, our CASEIN surpasses existing methods in both controllability and naturalness. Notably, we are the first to achieve fine-grained control over the mixed intensity of multiple emotions.
ROSITA: Enhancing Vision-and-Language Semantic Alignments via Cross- and Intra-modal Knowledge Integration
Aug 16, 2021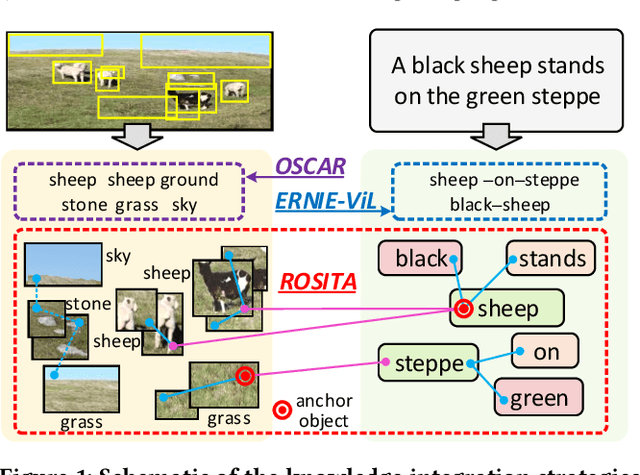
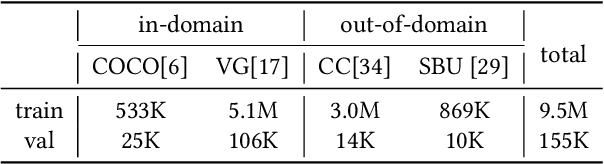
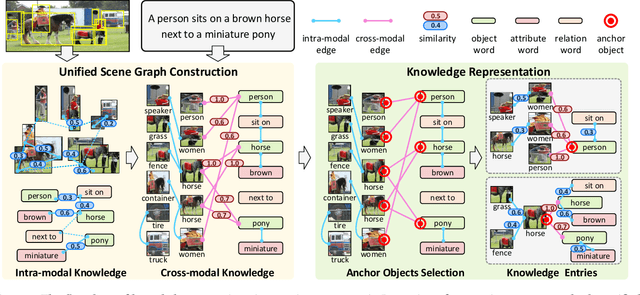
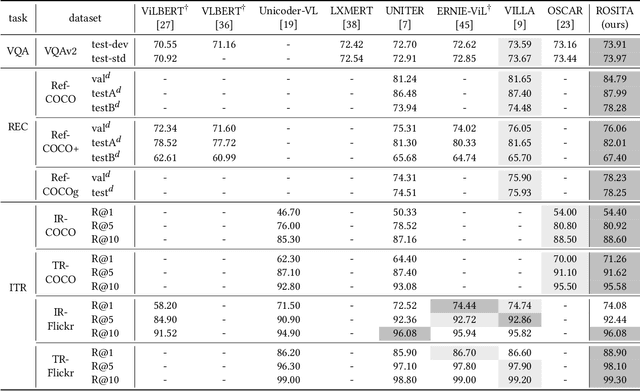
Vision-and-language pretraining (VLP) aims to learn generic multimodal representations from massive image-text pairs. While various successful attempts have been proposed, learning fine-grained semantic alignments between image-text pairs plays a key role in their approaches. Nevertheless, most existing VLP approaches have not fully utilized the intrinsic knowledge within the image-text pairs, which limits the effectiveness of the learned alignments and further restricts the performance of their models. To this end, we introduce a new VLP method called ROSITA, which integrates the cross- and intra-modal knowledge in a unified scene graph to enhance the semantic alignments. Specifically, we introduce a novel structural knowledge masking (SKM) strategy to use the scene graph structure as a priori to perform masked language (region) modeling, which enhances the semantic alignments by eliminating the interference information within and across modalities. Extensive ablation studies and comprehensive analysis verifies the effectiveness of ROSITA in semantic alignments. Pretrained with both in-domain and out-of-domain datasets, ROSITA significantly outperforms existing state-of-the-art VLP methods on three typical vision-and-language tasks over six benchmark datasets.
Deep Multimodal Neural Architecture Search
Apr 25, 2020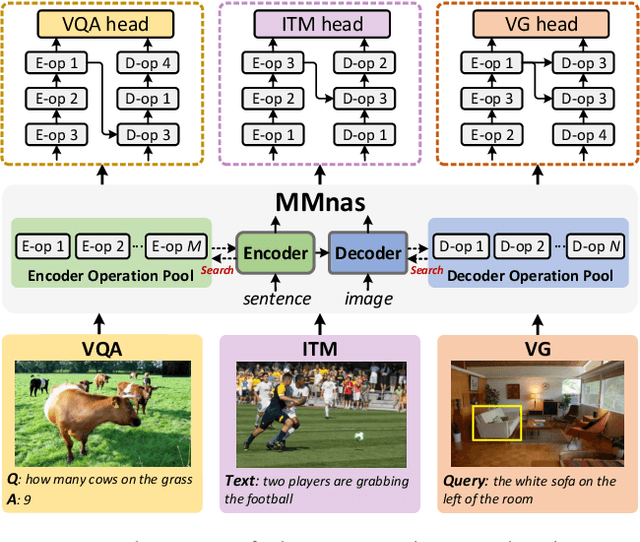
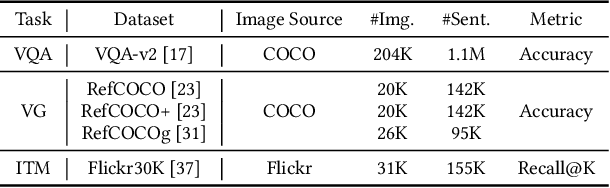
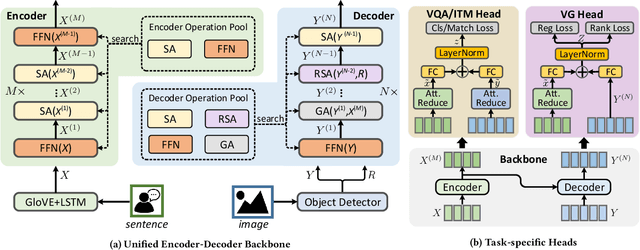
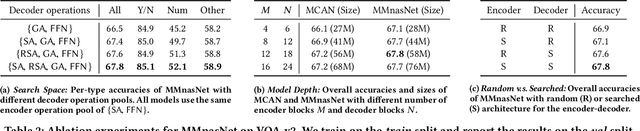
Designing effective neural networks is fundamentally important in deep multimodal learning. Most existing works focus on a single task and design neural architectures manually, which are highly task-specific and hard to generalize to different tasks. In this paper, we devise a generalized deep multimodal neural architecture search (MMnas) framework for various multimodal learning tasks. Given multimodal input, we first define a set of primitive operations, and then construct a deep encoder-decoder based unified backbone, where each encoder or decoder block corresponds to an operation searched from a predefined operation pool. On top of the unified backbone, we attach task-specific heads to tackle different multimodal learning tasks. By using a gradient-based NAS algorithm, the optimal architectures for different tasks are learned efficiently. Extensive ablation studies, comprehensive analysis, and superior experimental results show that MMnasNet significantly outperforms existing state-of-the-art approaches across three multimodal learning tasks (over five datasets), including visual question answering, image-text matching, and visual grounding. Code will be made available.
Multimodal Unified Attention Networks for Vision-and-Language Interactions
Aug 19, 2019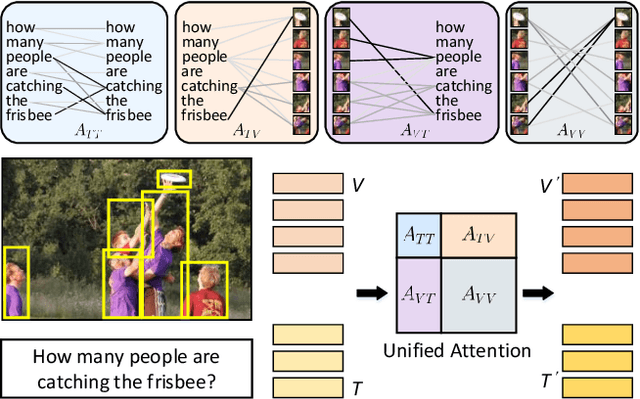
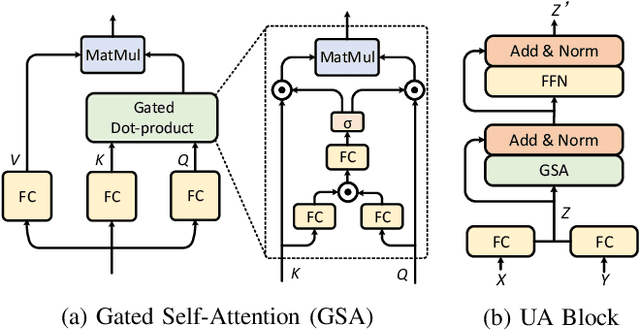
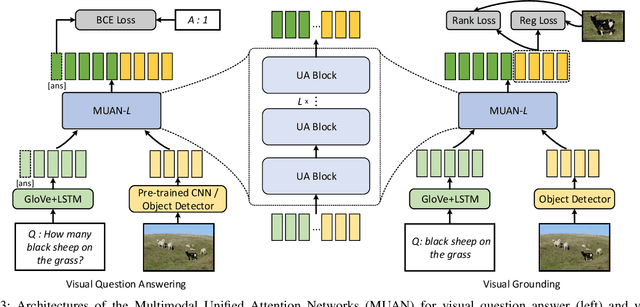

Learning an effective attention mechanism for multimodal data is important in many vision-and-language tasks that require a synergic understanding of both the visual and textual contents. Existing state-of-the-art approaches use co-attention models to associate each visual object (e.g., image region) with each textual object (e.g., query word). Despite the success of these co-attention models, they only model inter-modal interactions while neglecting intra-modal interactions. Here we propose a general `unified attention' model that simultaneously captures the intra- and inter-modal interactions of multimodal features and outputs their corresponding attended representations. By stacking such unified attention blocks in depth, we obtain the deep Multimodal Unified Attention Network (MUAN), which can seamlessly be applied to the visual question answering (VQA) and visual grounding tasks. We evaluate our MUAN models on two VQA datasets and three visual grounding datasets, and the results show that MUAN achieves top-level performance on both tasks without bells and whistles.
Deep Modular Co-Attention Networks for Visual Question Answering
Jun 25, 2019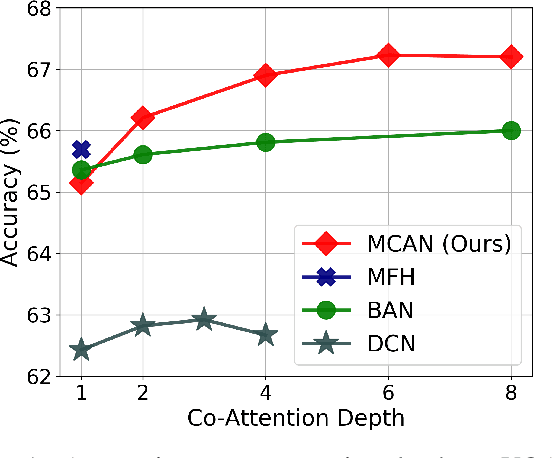

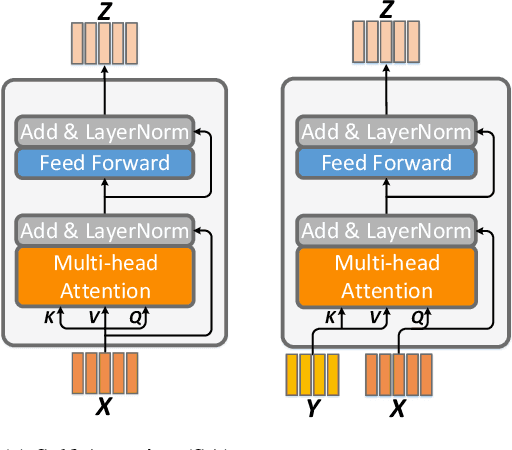
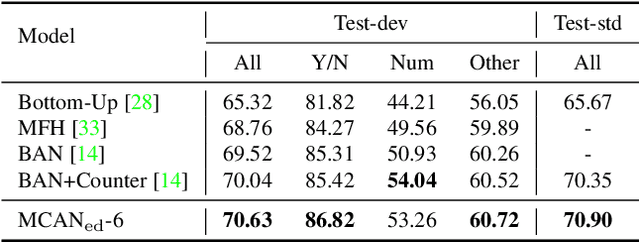
Visual Question Answering (VQA) requires a fine-grained and simultaneous understanding of both the visual content of images and the textual content of questions. Therefore, designing an effective `co-attention' model to associate key words in questions with key objects in images is central to VQA performance. So far, most successful attempts at co-attention learning have been achieved by using shallow models, and deep co-attention models show little improvement over their shallow counterparts. In this paper, we propose a deep Modular Co-Attention Network (MCAN) that consists of Modular Co-Attention (MCA) layers cascaded in depth. Each MCA layer models the self-attention of questions and images, as well as the guided-attention of images jointly using a modular composition of two basic attention units. We quantitatively and qualitatively evaluate MCAN on the benchmark VQA-v2 dataset and conduct extensive ablation studies to explore the reasons behind MCAN's effectiveness. Experimental results demonstrate that MCAN significantly outperforms the previous state-of-the-art. Our best single model delivers 70.63$\%$ overall accuracy on the test-dev set. Code is available at https://github.com/MILVLG/mcan-vqa.