 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearn from Your Mistakes: Tree-like Self-Play for Secure Code LLMs
Jun 02, 2026While Large Language Models (LLMs) excel in code generation, they remain prone to replicating subtle yet critical vulnerabilities endemic to their training data. Current alignment techniques, such as Supervised Fine-Tuning (SFT) and Reinforcement Learning (RL), typically apply coarse-grained optimization at the sequence level. This approach often fails to address the localized nature of security flaws, where a single incorrect token choice can compromise an entire program. To bridge this gap, we introduce Tree-like Self-Play (TSP), a framework that reframes secure code generation as a fine-grained sequential decision process. Unlike standard methods that blindly maximize likelihood, TSP constructs a decision tree where the model explores branching trajectories--generating both secure "golden paths" and vulnerable variants. By treating code generation as a self-play game, the model learns to strictly discriminate against its own localized errors. This provides a dense, on-policy learning signal that forces self-correction precisely at the critical decision nodes where vulnerabilities typically emerge. Our experiments demonstrate that TSP fundamentally enhances model reliability. In Python security benchmarks, TSP boosts CodeLlama-7B's pass rate (SPR@1) to 75.8%, significantly outperforming SFT (57.0%) and unstructured self-play baselines. Crucially, TSP induces robust out-of-distribution generalization: the model not only reduces vulnerabilities in unseen categories (CWEs) by 24.5% but also successfully transfers security principles learned from C/C++ to diverse languages, including Python, Go, and JavaScript. This suggests that TSP does not merely memorize patches, but internalizes abstract, language-agnostic security logic.
Punctuation-aware Hybrid Trainable Sparse Attention for Large Language Models
Jan 06, 2026Attention serves as the fundamental mechanism for long-context modeling in large language models (LLMs), yet dense attention becomes structurally prohibitive for long sequences due to its quadratic complexity. Consequently, sparse attention has received increasing attention as a scalable alternative. However, existing sparse attention methods rely on coarse-grained semantic representations during block selection, which blur intra-block semantic boundaries and lead to the loss of critical information. To address this issue, we propose \textbf{P}unctuation-aware \textbf{H}ybrid \textbf{S}parse \textbf{A}ttention \textbf{(PHSA)}, a natively trainable sparse attention framework that leverages punctuation tokens as semantic boundary anchors. Specifically, (1) we design a dual-branch aggregation mechanism that fuses global semantic representations with punctuation-enhanced boundary features, preserving the core semantic structure while introducing almost no additional computational overhead; (2) we introduce an extreme-sparsity-adaptive training and inference strategy that stabilizes model behavior under very low token activation ratios; Extensive experiments on general benchmarks and long-context evaluations demonstrate that PHSA consistently outperforms dense attention and state-of-the-art sparse attention baselines, including InfLLM v2. Specifically, for the 0.6B-parameter model with 32k-token input sequences, PHSA can reduce the information loss by 10.8\% at a sparsity ratio of 97.3\%.
Visformer: The Vision-friendly Transformer
Apr 27, 2021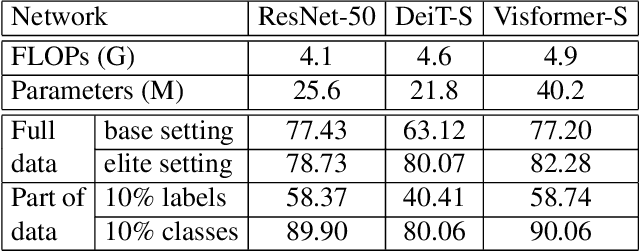
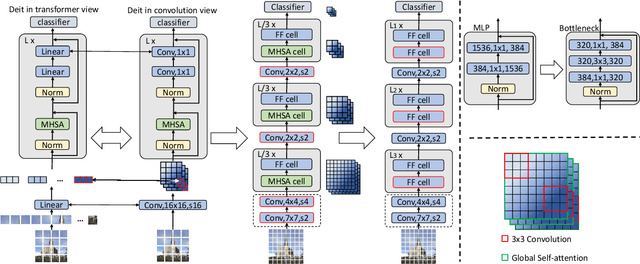
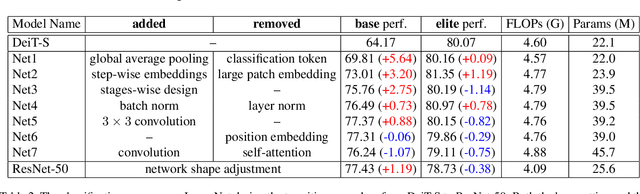
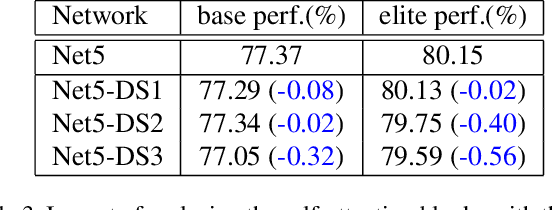
The past year has witnessed the rapid development of applying the Transformer module to vision problems. While some researchers have demonstrated that Transformer-based models enjoy a favorable ability of fitting data, there are still growing number of evidences showing that these models suffer over-fitting especially when the training data is limited. This paper offers an empirical study by performing step-by-step operations to gradually transit a Transformer-based model to a convolution-based model. The results we obtain during the transition process deliver useful messages for improving visual recognition. Based on these observations, we propose a new architecture named Visformer, which is abbreviated from the `Vision-friendly Transformer'. With the same computational complexity, Visformer outperforms both the Transformer-based and convolution-based models in terms of ImageNet classification accuracy, and the advantage becomes more significant when the model complexity is lower or the training set is smaller. The code is available at https://github.com/danczs/Visformer.
SelectScale: Mining More Patterns from Images via Selective and Soft Dropout
Nov 30, 2020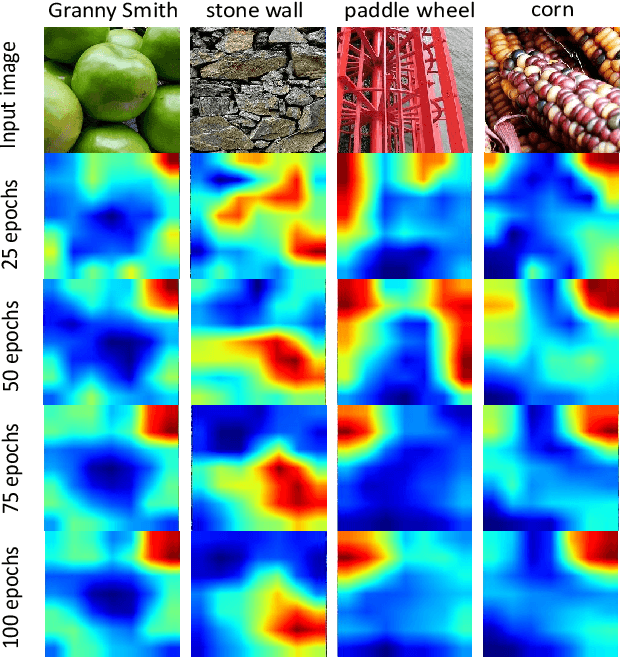


Convolutional neural networks (CNNs) have achieved remarkable success in image recognition. Although the internal patterns of the input images are effectively learned by the CNNs, these patterns only constitute a small proportion of useful patterns contained in the input images. This can be attributed to the fact that the CNNs will stop learning if the learned patterns are enough to make a correct classification. Network regularization methods like dropout and SpatialDropout can ease this problem. During training, they randomly drop the features. These dropout methods, in essence, change the patterns learned by the networks, and in turn, forces the networks to learn other patterns to make the correct classification. However, the above methods have an important drawback. Randomly dropping features is generally inefficient and can introduce unnecessary noise. To tackle this problem, we propose SelectScale. Instead of randomly dropping units, SelectScale selects the important features in networks and adjusts them during training. Using SelectScale, we improve the performance of CNNs on CIFAR and ImageNet.
Weight-Sharing Neural Architecture Search: A Battle to Shrink the Optimization Gap
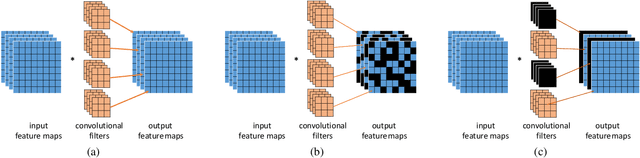
Aug 05, 2020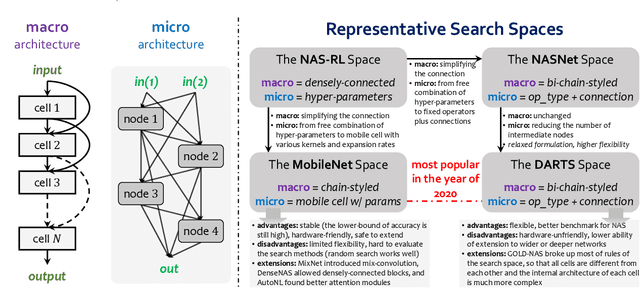
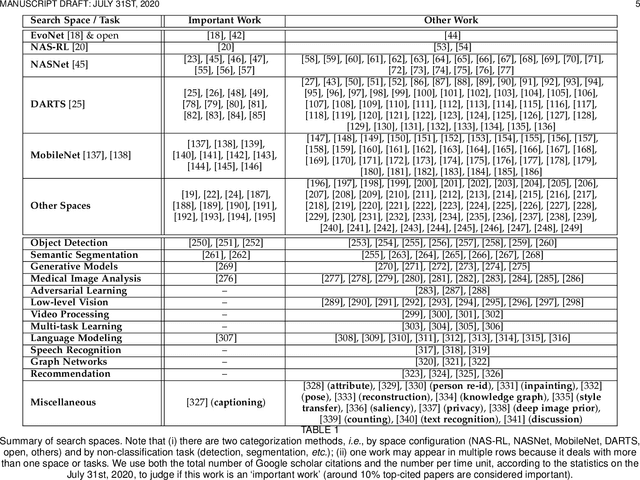
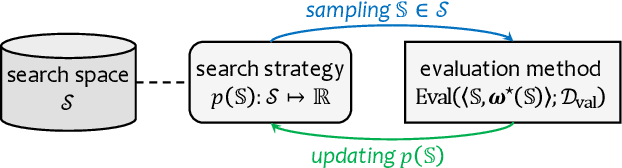
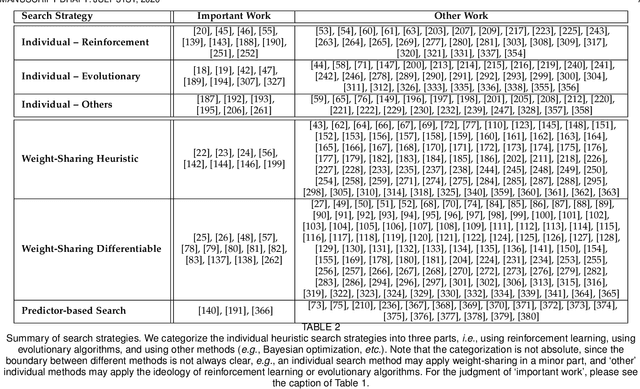
Neural architecture search (NAS) has attracted increasing attentions in both academia and industry. In the early age, researchers mostly applied individual search methods which sample and evaluate the candidate architectures separately and thus incur heavy computational overheads. To alleviate the burden, weight-sharing methods were proposed in which exponentially many architectures share weights in the same super-network, and the costly training procedure is performed only once. These methods, though being much faster, often suffer the issue of instability. This paper provides a literature review on NAS, in particular the weight-sharing methods, and points out that the major challenge comes from the optimization gap between the super-network and the sub-architectures. From this perspective, we summarize existing approaches into several categories according to their efforts in bridging the gap, and analyze both advantages and disadvantages of these methodologies. Finally, we share our opinions on the future directions of NAS and AutoML. Due to the expertise of the authors, this paper mainly focuses on the application of NAS to computer vision problems and may bias towards the work in our group.
A Survey on Domain Knowledge Powered Deep Learning for Medical Image Analysis
Apr 28, 2020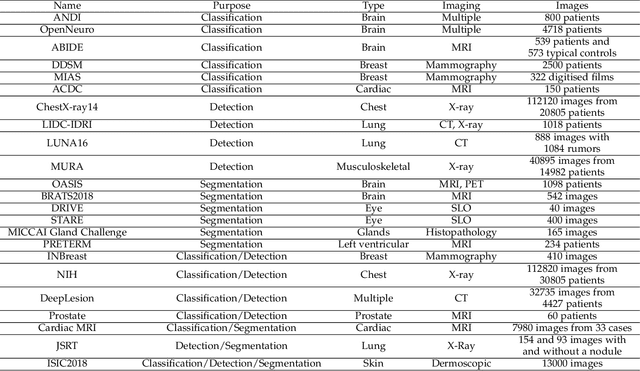
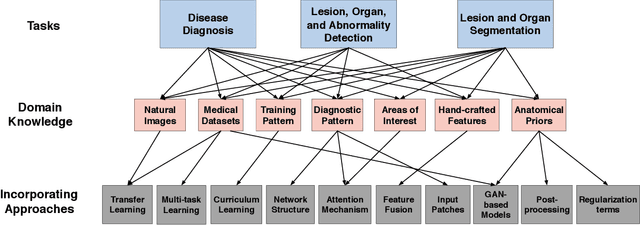
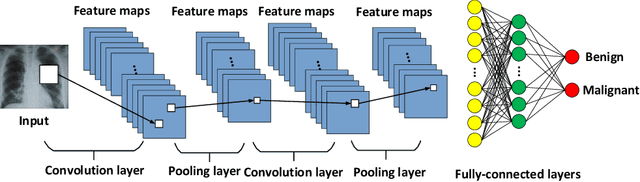
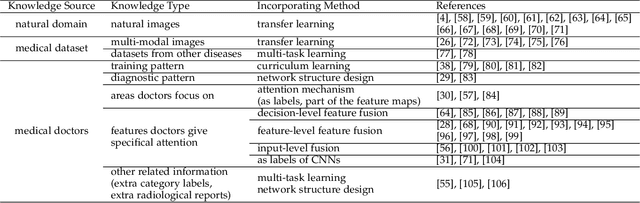
Although deep learning models like CNNs have achieved a great success in medical image analysis, small-sized medical datasets remain to be the major bottleneck in this area. To address this problem, researchers start looking for external information beyond the current available medical datasets. Traditional approaches generally leverage the information from natural images. More recent works utilize the domain knowledge from medical doctors, by letting networks either resemble how they are trained, mimic their diagnostic patterns, or focus on the features or areas they particular pay attention to. In this survey, we summarize the current progress on introducing medical domain knowledge in deep learning models for various tasks like disease diagnosis, lesion, organ and abnormality detection, lesion and organ segmentation. For each type of task, we systematically categorize different kinds of medical domain knowledge that have been utilized and the corresponding integrating methods. We end with a summary of challenges, open problems, and directions for future research.
Network Adjustment: Channel Search Guided by FLOPs Utilization Ratio
Apr 06, 2020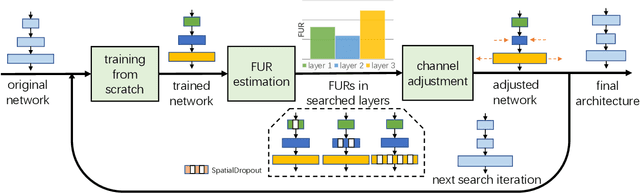
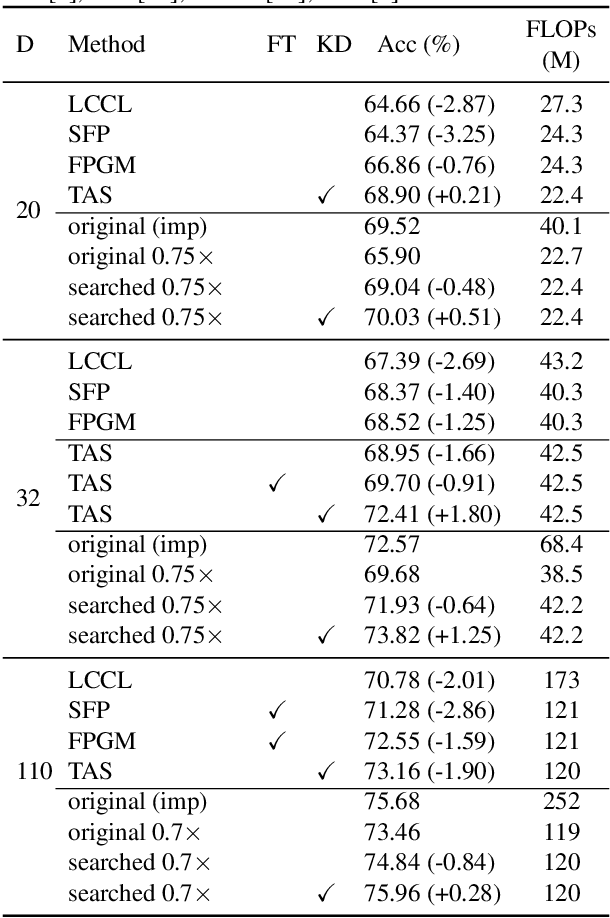
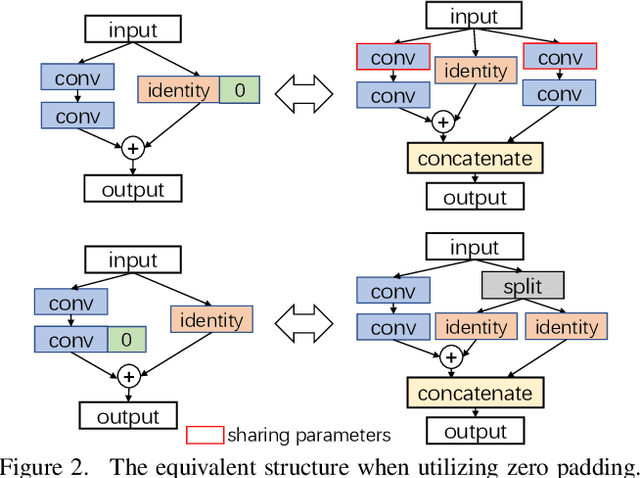
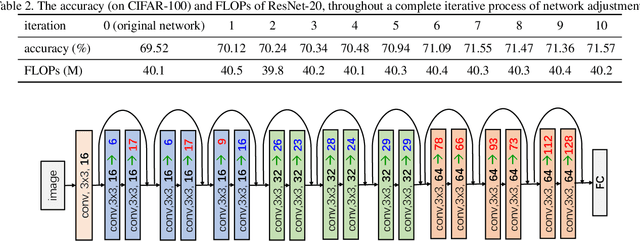
Automatic designing computationally efficient neural networks has received much attention in recent years. Existing approaches either utilize network pruning or leverage the network architecture search methods. This paper presents a new framework named network adjustment, which considers network accuracy as a function of FLOPs, so that under each network configuration, one can estimate the FLOPs utilization ratio (FUR) for each layer and use it to determine whether to increase or decrease the number of channels on the layer. Note that FUR, like the gradient of a non-linear function, is accurate only in a small neighborhood of the current network. Hence, we design an iterative mechanism so that the initial network undergoes a number of steps, each of which has a small `adjusting rate' to control the changes to the network. The computational overhead of the entire search process is reasonable, i.e., comparable to that of re-training the final model from scratch. Experiments on standard image classification datasets and a wide range of base networks demonstrate the effectiveness of our approach, which consistently outperforms the pruning counterpart. The code is available at https://github.com/danczs/NetworkAdjustment.