 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeedream 2.0: A Native Chinese-English Bilingual Image Generation Foundation Model
Mar 10, 2025Rapid advancement of diffusion models has catalyzed remarkable progress in the field of image generation. However, prevalent models such as Flux, SD3.5 and Midjourney, still grapple with issues like model bias, limited text rendering capabilities, and insufficient understanding of Chinese cultural nuances. To address these limitations, we present Seedream 2.0, a native Chinese-English bilingual image generation foundation model that excels across diverse dimensions, which adeptly manages text prompt in both Chinese and English, supporting bilingual image generation and text rendering. We develop a powerful data system that facilitates knowledge integration, and a caption system that balances the accuracy and richness for image description. Particularly, Seedream is integrated with a self-developed bilingual large language model as a text encoder, allowing it to learn native knowledge directly from massive data. This enable it to generate high-fidelity images with accurate cultural nuances and aesthetic expressions described in either Chinese or English. Beside, Glyph-Aligned ByT5 is applied for flexible character-level text rendering, while a Scaled ROPE generalizes well to untrained resolutions. Multi-phase post-training optimizations, including SFT and RLHF iterations, further improve the overall capability. Through extensive experimentation, we demonstrate that Seedream 2.0 achieves state-of-the-art performance across multiple aspects, including prompt-following, aesthetics, text rendering, and structural correctness. Furthermore, Seedream 2.0 has been optimized through multiple RLHF iterations to closely align its output with human preferences, as revealed by its outstanding ELO score. In addition, it can be readily adapted to an instruction-based image editing model, such as SeedEdit, with strong editing capability that balances instruction-following and image consistency.
New Dataset and Methods for Fine-Grained Compositional Referring Expression Comprehension via Specialist-MLLM Collaboration
Feb 28, 2025



Referring Expression Comprehension (REC) is a foundational cross-modal task that evaluates the interplay of language understanding, image comprehension, and language-to-image grounding. To advance this field, we introduce a new REC dataset with two key features. First, it is designed with controllable difficulty levels, requiring fine-grained reasoning across object categories, attributes, and relationships. Second, it incorporates negative text and images generated through fine-grained editing, explicitly testing a model's ability to reject non-existent targets, an often-overlooked yet critical challenge in existing datasets. To address fine-grained compositional REC, we propose novel methods based on a Specialist-MLLM collaboration framework, leveraging the complementary strengths of them: Specialist Models handle simpler tasks efficiently, while MLLMs are better suited for complex reasoning. Based on this synergy, we introduce two collaborative strategies. The first, Slow-Fast Adaptation (SFA), employs a routing mechanism to adaptively delegate simple tasks to Specialist Models and complex tasks to MLLMs. Additionally, common error patterns in both models are mitigated through a target-refocus strategy. The second, Candidate Region Selection (CRS), generates multiple bounding box candidates based on Specialist Model and uses the advanced reasoning capabilities of MLLMs to identify the correct target. Extensive experiments on our dataset and other challenging compositional benchmarks validate the effectiveness of our approaches. The SFA strategy achieves a trade-off between localization accuracy and efficiency, and the CRS strategy greatly boosts the performance of both Specialist Models and MLLMs. We aim for this work to offer valuable insights into solving complex real-world tasks by strategically combining existing tools for maximum effectiveness, rather than reinventing them.
MIND: Towards Immersive Psychological Healing with Multi-agent Inner Dialogue
Feb 27, 2025Mental health issues are worsening in today's competitive society, such as depression and anxiety. Traditional healings like counseling and chatbots fail to engage effectively, they often provide generic responses lacking emotional depth. Although large language models (LLMs) have the potential to create more human-like interactions, they still struggle to capture subtle emotions. This requires LLMs to be equipped with human-like adaptability and warmth. To fill this gap, we propose the MIND (Multi-agent INner Dialogue), a novel paradigm that provides more immersive psychological healing environments. Considering the strong generative and role-playing ability of LLM agents, we predefine an interactive healing framework and assign LLM agents different roles within the framework to engage in interactive inner dialogues with users, thereby providing an immersive healing experience. We conduct extensive human experiments in various real-world healing dimensions, and find that MIND provides a more user-friendly experience than traditional paradigms. This demonstrates that MIND effectively leverages the significant potential of LLMs in psychological healing.
ColorDynamic: Generalizable, Scalable, Real-time, End-to-end Local Planner for Unstructured and Dynamic Environments
Feb 27, 2025Deep Reinforcement Learning (DRL) has demonstrated potential in addressing robotic local planning problems, yet its efficacy remains constrained in highly unstructured and dynamic environments. To address these challenges, this study proposes the ColorDynamic framework. First, an end-to-end DRL formulation is established, which maps raw sensor data directly to control commands, thereby ensuring compatibility with unstructured environments. Under this formulation, a novel network, Transqer, is introduced. The Transqer enables online DRL learning from temporal transitions, substantially enhancing decision-making in dynamic scenarios. To facilitate scalable training of Transqer with diverse data, an efficient simulation platform E-Sparrow, along with a data augmentation technique leveraging symmetric invariance, are developed. Comparative evaluations against state-of-the-art methods, alongside assessments of generalizability, scalability, and real-time performance, were conducted to validate the effectiveness of ColorDynamic. Results indicate that our approach achieves a success rate exceeding 90% while exhibiting real-time capacity (1.2-1.3 ms per planning). Additionally, ablation studies were performed to corroborate the contributions of individual components. Building on this, the OkayPlan-ColorDynamic (OPCD) navigation system is presented, with simulated and real-world experiments demonstrating its superiority and applicability in complex scenarios. The codebase and experimental demonstrations have been open-sourced on our website to facilitate reproducibility and further research.
Brain-inspired analogical mixture prototypes for few-shot class-incremental learning
Feb 26, 2025Few-shot class-incremental learning (FSCIL) poses significant challenges for artificial neural networks due to the need to efficiently learn from limited data while retaining knowledge of previously learned tasks. Inspired by the brain's mechanisms for categorization and analogical learning, we propose a novel approach called Brain-inspired Analogical Mixture Prototypes (BAMP). BAMP has three components: mixed prototypical feature learning, statistical analogy, and soft voting. Starting from a pre-trained Vision Transformer (ViT), mixed prototypical feature learning represents each class using a mixture of prototypes and fine-tunes these representations during the base session. The statistical analogy calibrates the mean and covariance matrix of prototypes for new classes according to similarity to the base classes, and computes classification score with Mahalanobis distance. Soft voting combines both merits of statistical analogy and an off-shelf FSCIL method. Our experiments on benchmark datasets demonstrate that BAMP outperforms state-of-the-art on both traditional big start FSCIL setting and challenging small start FSCIL setting. The study suggests that brain-inspired analogical mixture prototypes can alleviate catastrophic forgetting and over-fitting problems in FSCIL.
Constructing a Norm for Children's Scientific Drawing: Distribution Features Based on Semantic Similarity of Large Language Models
Feb 21, 2025The use of children's drawings to examining their conceptual understanding has been proven to be an effective method, but there are two major problems with previous research: 1. The content of the drawings heavily relies on the task, and the ecological validity of the conclusions is low; 2. The interpretation of drawings relies too much on the subjective feelings of the researchers. To address this issue, this study uses the Large Language Model (LLM) to identify 1420 children's scientific drawings (covering 9 scientific themes/concepts), and uses the word2vec algorithm to calculate their semantic similarity. The study explores whether there are consistent drawing representations for children on the same theme, and attempts to establish a norm for children's scientific drawings, providing a baseline reference for follow-up children's drawing research. The results show that the representation of most drawings has consistency, manifested as most semantic similarity greater than 0.8. At the same time, it was found that the consistency of the representation is independent of the accuracy (of LLM's recognition), indicating the existence of consistency bias. In the subsequent exploration of influencing factors, we used Kendall rank correlation coefficient to investigate the effects of Sample Size, Abstract Degree, and Focus Points on drawings, and used word frequency statistics to explore whether children represented abstract themes/concepts by reproducing what was taught in class.
Accuracy of Wearable ECG Parameter Calculation Method for Long QT and First-Degree A-V Block Detection: A Multi-Center Real-World Study with External Validations Compared to Standard ECG Machines and Cardiologist Assessments
Feb 21, 2025In recent years, wearable devices have revolutionized cardiac monitoring by enabling continuous, non-invasive ECG recording in real-world settings. Despite these advances, the accuracy of ECG parameter calculations (PR interval, QRS interval, QT interval, etc.) from wearables remains to be rigorously validated against conventional ECG machines and expert clinician assessments. In this large-scale, multicenter study, we evaluated FeatureDB, a novel algorithm for automated computation of ECG parameters from wearable single-lead signals Three diverse datasets were employed: the AHMU-FH dataset (n=88,874), the CSE dataset (n=106), and the HeartVoice-ECG-lite dataset (n=369) with annotations provided by two experienced cardiologists. FeatureDB demonstrates a statistically significant correlation with key parameters (PR interval, QRS duration, QT interval, and QTc) calculated by standard ECG machines and annotated by clinical doctors. Bland-Altman analysis confirms a high level of agreement.Moreover,FeatureDB exhibited robust diagnostic performance in detecting Long QT syndrome (LQT) and atrioventricular block interval abnormalities (AVBI),with excellent area under the ROC curve (LQT: 0.836, AVBI: 0.861),accuracy (LQT: 0.856, AVBI: 0.845),sensitivity (LQT: 0.815, AVBI: 0.877),and specificity (LQT: 0.856, AVBI: 0.845).This further validates its clinical reliability. These results validate the clinical applicability of FeatureDB for wearable ECG analysis and highlight its potential to bridge the gap between traditional diagnostic methods and emerging wearable technologies.Ultimately,this study supports integrating wearable ECG devices into large-scale cardiovascular disease management and early intervention strategies,and it highlights the potential of wearable ECG technologies to deliver accurate,clinically relevant cardiac monitoring while advancing broader applications in cardiovascular care.
Qwen2.5-VL Technical Report
Feb 19, 2025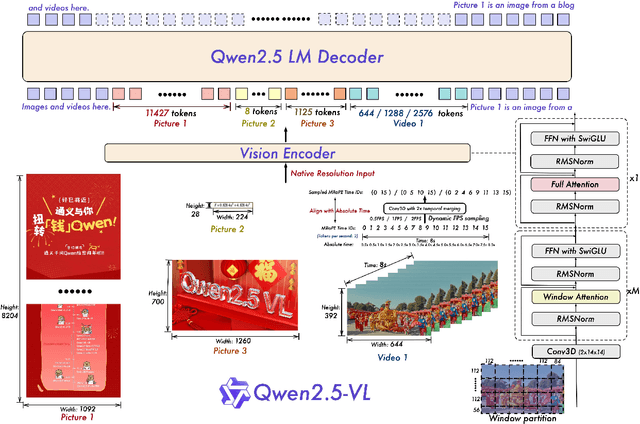
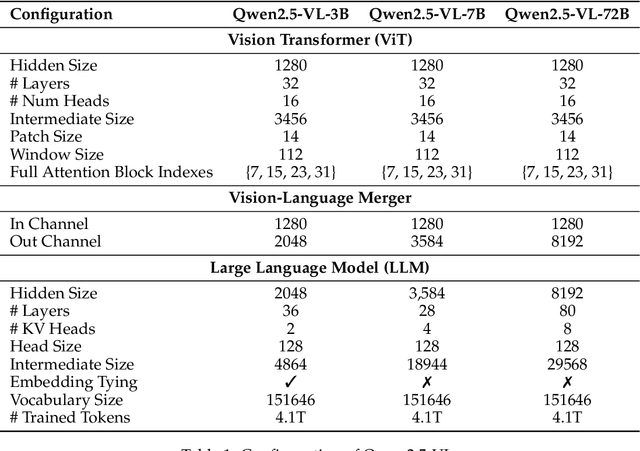
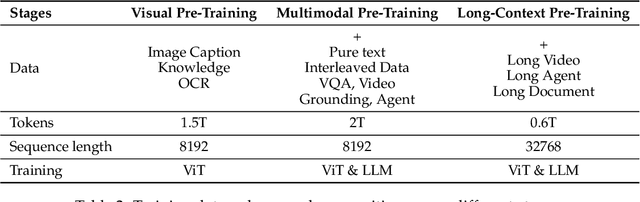
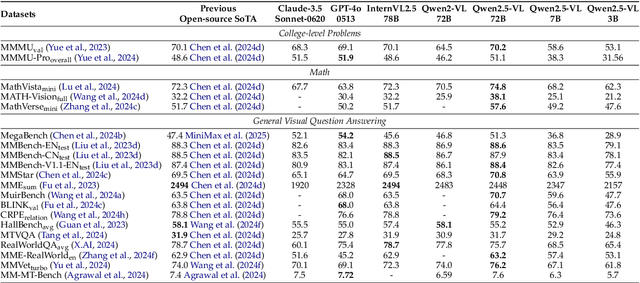
We introduce Qwen2.5-VL, the latest flagship model of Qwen vision-language series, which demonstrates significant advancements in both foundational capabilities and innovative functionalities. Qwen2.5-VL achieves a major leap forward in understanding and interacting with the world through enhanced visual recognition, precise object localization, robust document parsing, and long-video comprehension. A standout feature of Qwen2.5-VL is its ability to localize objects using bounding boxes or points accurately. It provides robust structured data extraction from invoices, forms, and tables, as well as detailed analysis of charts, diagrams, and layouts. To handle complex inputs, Qwen2.5-VL introduces dynamic resolution processing and absolute time encoding, enabling it to process images of varying sizes and videos of extended durations (up to hours) with second-level event localization. This allows the model to natively perceive spatial scales and temporal dynamics without relying on traditional normalization techniques. By training a native dynamic-resolution Vision Transformer (ViT) from scratch and incorporating Window Attention, we reduce computational overhead while maintaining native resolution. As a result, Qwen2.5-VL excels not only in static image and document understanding but also as an interactive visual agent capable of reasoning, tool usage, and task execution in real-world scenarios such as operating computers and mobile devices. Qwen2.5-VL is available in three sizes, addressing diverse use cases from edge AI to high-performance computing. The flagship Qwen2.5-VL-72B model matches state-of-the-art models like GPT-4o and Claude 3.5 Sonnet, particularly excelling in document and diagram understanding. Additionally, Qwen2.5-VL maintains robust linguistic performance, preserving the core language competencies of the Qwen2.5 LLM.
Understanding Representation Dynamics of Diffusion Models via Low-Dimensional Modeling
Feb 09, 2025



This work addresses the critical question of why and when diffusion models, despite being designed for generative tasks, can excel at learning high-quality representations in a self-supervised manner. To address this, we develop a mathematical framework based on a low-dimensional data model and posterior estimation, revealing a fundamental trade-off between generation and representation quality near the final stage of image generation. Our analysis explains the unimodal representation dynamics across noise scales, mainly driven by the interplay between data denoising and class specification. Building on these insights, we propose an ensemble method that aggregates features across noise levels, significantly improving both clean performance and robustness under label noise. Extensive experiments on both synthetic and real-world datasets validate our findings.
Demystifying Catastrophic Forgetting in Two-Stage Incremental Object Detector
Feb 08, 2025Catastrophic forgetting is a critical chanllenge for incremental object detection (IOD). Most existing methods treat the detector monolithically, relying on instance replay or knowledge distillation without analyzing component-specific forgetting. Through dissection of Faster R-CNN, we reveal a key insight: Catastrophic forgetting is predominantly localized to the RoI Head classifier, while regressors retain robustness across incremental stages. This finding challenges conventional assumptions, motivating us to develop a framework termed NSGP-RePRE. Regional Prototype Replay (RePRE) mitigates classifier forgetting via replay of two types of prototypes: coarse prototypes represent class-wise semantic centers of RoI features, while fine-grained prototypes model intra-class variations. Null Space Gradient Projection (NSGP) is further introduced to eliminate prototype-feature misalignment by updating the feature extractor in directions orthogonal to subspace of old inputs via gradient projection, aligning RePRE with incremental learning dynamics. Our simple yet effective design allows NSGP-RePRE to achieve state-of-the-art performance on the Pascal VOC and MS COCO datasets under various settings. Our work not only advances IOD methodology but also provide pivotal insights for catastrophic forgetting mitigation in IOD. Code will be available soon.