 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBrowseComp-ZH: Benchmarking Web Browsing Ability of Large Language Models in Chinese
May 01, 2025



As large language models (LLMs) evolve into tool-using agents, the ability to browse the web in real-time has become a critical yardstick for measuring their reasoning and retrieval competence. Existing benchmarks such as BrowseComp concentrate on English and overlook the linguistic, infrastructural, and censorship-related complexities of other major information ecosystems -- most notably Chinese. To address this gap, we introduce BrowseComp-ZH, a high-difficulty benchmark purpose-built to comprehensively evaluate LLM agents on the Chinese web. BrowseComp-ZH consists of 289 multi-hop questions spanning 11 diverse domains. Each question is reverse-engineered from a short, objective, and easily verifiable answer (e.g., a date, number, or proper noun). A two-stage quality control protocol is applied to strive for high question difficulty and answer uniqueness. We benchmark over 20 state-of-the-art language models and agentic search systems on our proposed BrowseComp-ZH. Despite their strong conversational and retrieval capabilities, most models struggle severely: a large number achieve accuracy rates below 10%, and only a handful exceed 20%. Even the best-performing system, OpenAI's DeepResearch, reaches just 42.9%. These results demonstrate the considerable difficulty of BrowseComp-ZH, where success demands not only effective retrieval strategies, but also sophisticated reasoning and information reconciliation -- capabilities that current models still struggle to master. Our dataset, construction guidelines, and benchmark results have been publicly released at https://github.com/PALIN2018/BrowseComp-ZH.
Aligning Language Models Using Follow-up Likelihood as Reward Signal
Sep 20, 2024



In natural human-to-human conversations, participants often receive feedback signals from one another based on their follow-up reactions. These reactions can include verbal responses, facial expressions, changes in emotional state, and other non-verbal cues. Similarly, in human-machine interactions, the machine can leverage the user's follow-up utterances as feedback signals to assess whether it has appropriately addressed the user's request. Therefore, we propose using the likelihood of follow-up utterances as rewards to differentiate preferred responses from less favored ones, without relying on human or commercial LLM-based preference annotations. Our proposed reward mechanism, ``Follow-up Likelihood as Reward" (FLR), matches the performance of strong reward models trained on large-scale human or GPT-4 annotated data on 8 pairwise-preference and 4 rating-based benchmarks. Building upon the FLR mechanism, we propose to automatically mine preference data from the online generations of a base policy model. The preference data are subsequently used to boost the helpfulness of the base model through direct alignment from preference (DAP) methods, such as direct preference optimization (DPO). Lastly, we demonstrate that fine-tuning the language model that provides follow-up likelihood with natural language feedback significantly enhances FLR's performance on reward modeling benchmarks and effectiveness in aligning the base policy model's helpfulness.
Multi-modal Adversarial Training for Zero-Shot Voice Cloning
Aug 28, 2024A text-to-speech (TTS) model trained to reconstruct speech given text tends towards predictions that are close to the average characteristics of a dataset, failing to model the variations that make human speech sound natural. This problem is magnified for zero-shot voice cloning, a task that requires training data with high variance in speaking styles. We build off of recent works which have used Generative Advsarial Networks (GAN) by proposing a Transformer encoder-decoder architecture to conditionally discriminates between real and generated speech features. The discriminator is used in a training pipeline that improves both the acoustic and prosodic features of a TTS model. We introduce our novel adversarial training technique by applying it to a FastSpeech2 acoustic model and training on Libriheavy, a large multi-speaker dataset, for the task of zero-shot voice cloning. Our model achieves improvements over the baseline in terms of speech quality and speaker similarity. Audio examples from our system are available online.
Vision-Language Models Meet Meteorology: Developing Models for Extreme Weather Events Detection with Heatmaps
Jun 14, 2024



Real-time detection and prediction of extreme weather protect human lives and infrastructure. Traditional methods rely on numerical threshold setting and manual interpretation of weather heatmaps with Geographic Information Systems (GIS), which can be slow and error-prone. Our research redefines Extreme Weather Events Detection (EWED) by framing it as a Visual Question Answering (VQA) problem, thereby introducing a more precise and automated solution. Leveraging Vision-Language Models (VLM) to simultaneously process visual and textual data, we offer an effective aid to enhance the analysis process of weather heatmaps. Our initial assessment of general-purpose VLMs (e.g., GPT-4-Vision) on EWED revealed poor performance, characterized by low accuracy and frequent hallucinations due to inadequate color differentiation and insufficient meteorological knowledge. To address these challenges, we introduce ClimateIQA, the first meteorological VQA dataset, which includes 8,760 wind gust heatmaps and 254,040 question-answer pairs covering four question types, both generated from the latest climate reanalysis data. We also propose Sparse Position and Outline Tracking (SPOT), an innovative technique that leverages OpenCV and K-Means clustering to capture and depict color contours in heatmaps, providing ClimateIQA with more accurate color spatial location information. Finally, we present Climate-Zoo, the first meteorological VLM collection, which adapts VLMs to meteorological applications using the ClimateIQA dataset. Experiment results demonstrate that models from Climate-Zoo substantially outperform state-of-the-art general VLMs, achieving an accuracy increase from 0% to over 90% in EWED verification. The datasets and models in this study are publicly available for future climate science research: https://github.com/AlexJJJChen/Climate-Zoo.
TS-Align: A Teacher-Student Collaborative Framework for Scalable Iterative Finetuning of Large Language Models
May 30, 2024



Mainstream approaches to aligning large language models (LLMs) heavily rely on human preference data, particularly when models require periodic updates. The standard process for iterative alignment of LLMs involves collecting new human feedback for each update. However, the data collection process is costly and challenging to scale. To address this issue, we introduce the "TS-Align" framework, which fine-tunes a policy model using pairwise feedback data automatically mined from its outputs. This automatic mining process is efficiently accomplished through the collaboration between a large-scale teacher model and a small-scale student model. The policy fine-tuning process can be iteratively repeated using on-policy generations within our proposed teacher-student collaborative framework. Through extensive experiments, we demonstrate that our final aligned policy outperforms the base policy model with an average win rate of 69.7% across seven conversational or instruction-following datasets. Furthermore, we show that the ranking capability of the teacher is effectively distilled into the student through our pipeline, resulting in a small-scale yet effective reward model for policy model alignment.
Qilin-Med-VL: Towards Chinese Large Vision-Language Model for General Healthcare
Nov 01, 2023Large Language Models (LLMs) have introduced a new era of proficiency in comprehending complex healthcare and biomedical topics. However, there is a noticeable lack of models in languages other than English and models that can interpret multi-modal input, which is crucial for global healthcare accessibility. In response, this study introduces Qilin-Med-VL, the first Chinese large vision-language model designed to integrate the analysis of textual and visual data. Qilin-Med-VL combines a pre-trained Vision Transformer (ViT) with a foundational LLM. It undergoes a thorough two-stage curriculum training process that includes feature alignment and instruction tuning. This method enhances the model's ability to generate medical captions and answer complex medical queries. We also release ChiMed-VL, a dataset consisting of more than 1M image-text pairs. This dataset has been carefully curated to enable detailed and comprehensive interpretation of medical data using various types of images.
Qilin-Med: Multi-stage Knowledge Injection Advanced Medical Large Language Model
Oct 13, 2023



Integrating large language models (LLMs) into healthcare presents potential but faces challenges. Directly pre-training LLMs for domains like medicine is resource-heavy and sometimes unfeasible. Sole reliance on Supervised Fine-tuning (SFT) can result in overconfident predictions and may not tap into domain specific insights. Addressing these challenges, we present a multi-stage training method combining Domain-specific Continued Pre-training (DCPT), SFT, and Direct Preference Optimization (DPO). A notable contribution of our study is the introduction of a 3Gb Chinese Medicine (ChiMed) dataset, encompassing medical question answering, plain texts, knowledge graphs, and dialogues, segmented into three training stages. The medical LLM trained with our pipeline, Qilin-Med, exhibits significant performance boosts. In the CPT and SFT phases, it achieves 38.4% and 40.0% accuracy on the CMExam, surpassing Baichuan-7B's 33.5%. In the DPO phase, on the Huatuo-26M test set, it scores 16.66 in BLEU-1 and 27.44 in ROUGE1, outperforming the SFT's 12.69 and 24.21. This highlights the strength of our training approach in refining LLMs for medical applications.
LLMRec: Benchmarking Large Language Models on Recommendation Task
Aug 23, 2023
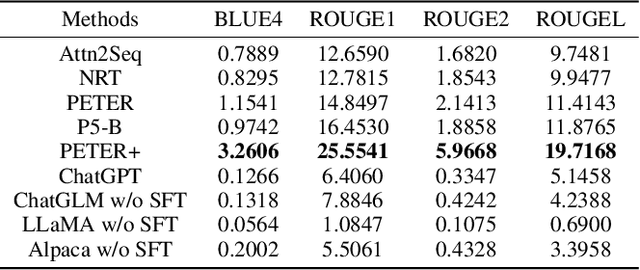


Recently, the fast development of Large Language Models (LLMs) such as ChatGPT has significantly advanced NLP tasks by enhancing the capabilities of conversational models. However, the application of LLMs in the recommendation domain has not been thoroughly investigated. To bridge this gap, we propose LLMRec, a LLM-based recommender system designed for benchmarking LLMs on various recommendation tasks. Specifically, we benchmark several popular off-the-shelf LLMs, such as ChatGPT, LLaMA, ChatGLM, on five recommendation tasks, including rating prediction, sequential recommendation, direct recommendation, explanation generation, and review summarization. Furthermore, we investigate the effectiveness of supervised finetuning to improve LLMs' instruction compliance ability. The benchmark results indicate that LLMs displayed only moderate proficiency in accuracy-based tasks such as sequential and direct recommendation. However, they demonstrated comparable performance to state-of-the-art methods in explainability-based tasks. We also conduct qualitative evaluations to further evaluate the quality of contents generated by different models, and the results show that LLMs can truly understand the provided information and generate clearer and more reasonable results. We aspire that this benchmark will serve as an inspiration for researchers to delve deeper into the potential of LLMs in enhancing recommendation performance. Our codes, processed data and benchmark results are available at https://github.com/williamliujl/LLMRec.
Benchmarking Large Language Models on CMExam -- A Comprehensive Chinese Medical Exam Dataset
Jun 08, 2023



Recent advancements in large language models (LLMs) have transformed the field of question answering (QA). However, evaluating LLMs in the medical field is challenging due to the lack of standardized and comprehensive datasets. To address this gap, we introduce CMExam, sourced from the Chinese National Medical Licensing Examination. CMExam consists of 60K+ multiple-choice questions for standardized and objective evaluations, as well as solution explanations for model reasoning evaluation in an open-ended manner. For in-depth analyses of LLMs, we invited medical professionals to label five additional question-wise annotations, including disease groups, clinical departments, medical disciplines, areas of competency, and question difficulty levels. Alongside the dataset, we further conducted thorough experiments with representative LLMs and QA algorithms on CMExam. The results show that GPT-4 had the best accuracy of 61.6% and a weighted F1 score of 0.617. These results highlight a great disparity when compared to human accuracy, which stood at 71.6%. For explanation tasks, while LLMs could generate relevant reasoning and demonstrate improved performance after finetuning, they fall short of a desired standard, indicating ample room for improvement. To the best of our knowledge, CMExam is the first Chinese medical exam dataset to provide comprehensive medical annotations. The experiments and findings of LLM evaluation also provide valuable insights into the challenges and potential solutions in developing Chinese medical QA systems and LLM evaluation pipelines. The dataset and relevant code are available at https://github.com/williamliujl/CMExam.
GreenPLM: Cross-lingual pre-trained language models conversion with (almost) no cost
Nov 13, 2022



While large pre-trained models have transformed the field of natural language processing (NLP), the high training cost and low cross-lingual availability of such models prevent the new advances from being equally shared by users across all languages, especially the less spoken ones. To promote equal opportunities for all language speakers in NLP research and to reduce energy consumption for sustainability, this study proposes an effective and energy-efficient framework GreenPLM that uses bilingual lexicons to directly translate language models of one language into other languages at (almost) no additional cost. We validate this approach in 18 languages and show that this framework is comparable to, if not better than, other heuristics trained with high cost. In addition, when given a low computational cost (2.5%), the framework outperforms the original monolingual language models in six out of seven tested languages. This approach can be easily implemented, and we will release language models in 50 languages translated from English soon.