 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntent-Guided Reasoning for Sequential Recommendation
Dec 16, 2025Sequential recommendation systems aim to capture users' evolving preferences from their interaction histories. Recent reasoningenhanced methods have shown promise by introducing deliberate, chain-of-thought-like processes with intermediate reasoning steps. However, these methods rely solely on the next target item as supervision, leading to two critical issues: (1) reasoning instability--the process becomes overly sensitive to recent behaviors and spurious interactions like accidental clicks, and (2) surface-level reasoning--the model memorizes item-to-item transitions rather than understanding intrinsic behavior patterns. To address these challenges, we propose IGR-SR, an Intent-Guided Reasoning framework for Sequential Recommendation that anchors the reasoning process to explicitly extracted high-level intents. Our framework comprises three key components: (1) a Latent Intent Distiller (LID) that efficiently extracts multi-faceted intents using a frozen encoder with learnable tokens, (2) an Intent-aware Deliberative Reasoner (IDR) that decouples reasoning into intent deliberation and decision-making via a dual-attention architecture, and (3) an Intent Consistency Regularization (ICR) that ensures robustness by enforcing consistent representations across different intent views. Extensive experiments on three public datasets demonstrate that IGR-SR achieves an average 7.13% improvement over state-of-the-art baselines. Critically, under 20% behavioral noise, IGR-SR degrades only 10.4% compared to 16.2% and 18.6% for competing methods, validating the effectiveness and robustness of intent-guided reasoning.
DTRec: Learning Dynamic Reasoning Trajectories for Sequential Recommendation
Dec 16, 2025



Inspired by advances in LLMs, reasoning-enhanced sequential recommendation performs multi-step deliberation before making final predictions, unlocking greater potential for capturing user preferences. However, current methods are constrained by static reasoning trajectories that are ill-suited for the diverse complexity of user behaviors. They suffer from two key limitations: (1) a static reasoning direction, which uses flat supervision signals misaligned with human-like hierarchical reasoning, and (2) a fixed reasoning depth, which inefficiently applies the same computational effort to all users, regardless of pattern complexity. These rigidity lead to suboptimal performance and significant computational waste. To overcome these challenges, we propose DTRec, a novel and effective framework that explores the Dynamic reasoning Trajectory for Sequential Recommendation along both direction and depth. To guide the direction, we develop Hierarchical Process Supervision (HPS), which provides coarse-to-fine supervisory signals to emulate the natural, progressive refinement of human cognitive processes. To optimize the depth, we introduce the Adaptive Reasoning Halting (ARH) mechanism that dynamically adjusts the number of reasoning steps by jointly monitoring three indicators. Extensive experiments on three real-world datasets demonstrate the superiority of our approach, achieving up to a 24.5% performance improvement over strong baselines while simultaneously reducing computational cost by up to 41.6%.
BrowseComp-ZH: Benchmarking Web Browsing Ability of Large Language Models in Chinese
May 01, 2025



As large language models (LLMs) evolve into tool-using agents, the ability to browse the web in real-time has become a critical yardstick for measuring their reasoning and retrieval competence. Existing benchmarks such as BrowseComp concentrate on English and overlook the linguistic, infrastructural, and censorship-related complexities of other major information ecosystems -- most notably Chinese. To address this gap, we introduce BrowseComp-ZH, a high-difficulty benchmark purpose-built to comprehensively evaluate LLM agents on the Chinese web. BrowseComp-ZH consists of 289 multi-hop questions spanning 11 diverse domains. Each question is reverse-engineered from a short, objective, and easily verifiable answer (e.g., a date, number, or proper noun). A two-stage quality control protocol is applied to strive for high question difficulty and answer uniqueness. We benchmark over 20 state-of-the-art language models and agentic search systems on our proposed BrowseComp-ZH. Despite their strong conversational and retrieval capabilities, most models struggle severely: a large number achieve accuracy rates below 10%, and only a handful exceed 20%. Even the best-performing system, OpenAI's DeepResearch, reaches just 42.9%. These results demonstrate the considerable difficulty of BrowseComp-ZH, where success demands not only effective retrieval strategies, but also sophisticated reasoning and information reconciliation -- capabilities that current models still struggle to master. Our dataset, construction guidelines, and benchmark results have been publicly released at https://github.com/PALIN2018/BrowseComp-ZH.
Local-Global Attention: An Adaptive Mechanism for Multi-Scale Feature Integration
Nov 14, 2024



In recent years, attention mechanisms have significantly enhanced the performance of object detection by focusing on key feature information. However, prevalent methods still encounter difficulties in effectively balancing local and global features. This imbalance hampers their ability to capture both fine-grained details and broader contextual information-two critical elements for achieving accurate object detection.To address these challenges, we propose a novel attention mechanism, termed Local-Global Attention, which is designed to better integrate both local and global contextual features. Specifically, our approach combines multi-scale convolutions with positional encoding, enabling the model to focus on local details while concurrently considering the broader global context. Additionally, we introduce a learnable parameters, which allow the model to dynamically adjust the relative importance of local and global attention, depending on the specific requirements of the task, thereby optimizing feature representations across multiple scales.We have thoroughly evaluated the Local-Global Attention mechanism on several widely used object detection and classification datasets. Our experimental results demonstrate that this approach significantly enhances the detection of objects at various scales, with particularly strong performance on multi-class and small object detection tasks. In comparison to existing attention mechanisms, Local-Global Attention consistently outperforms them across several key metrics, all while maintaining computational efficiency.
Spatial Moment Pooling Improves Neural Image Assessment
Sep 29, 2022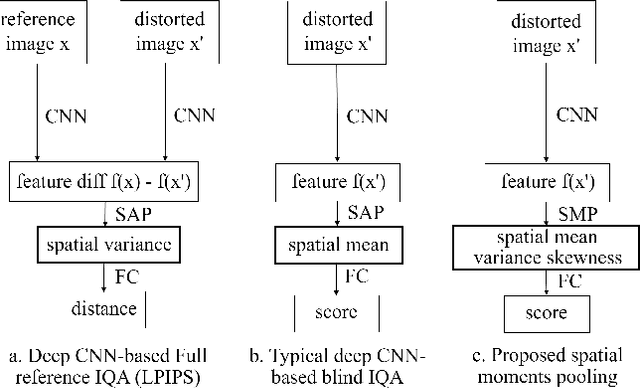
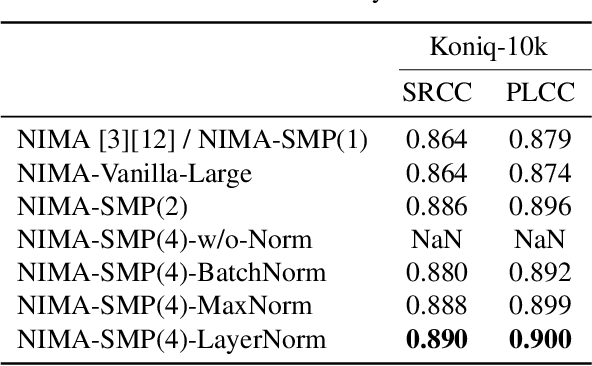
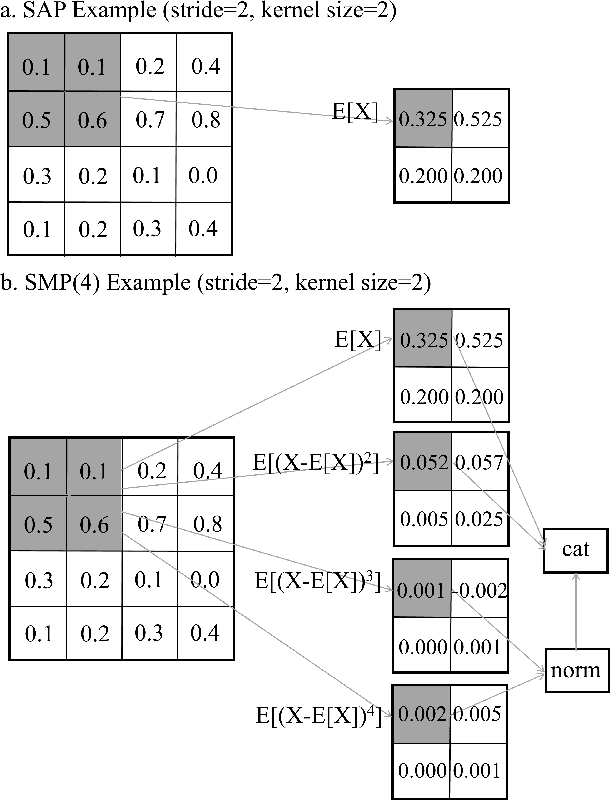
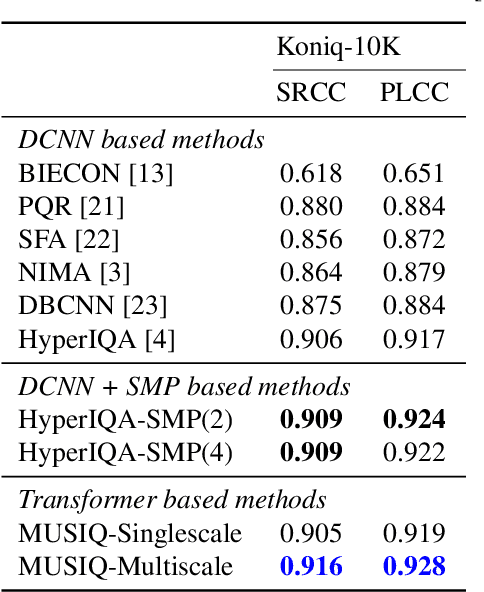
In recent years, there has been widespread attention drawn to convolutional neural network (CNN) based blind image quality assessment (IQA). A large number of works start by extracting deep features from CNN. Then, those features are processed through spatial average pooling (SAP) and fully connected layers to predict quality. Inspired by full reference IQA and texture features, in this paper, we extend SAP ($1^{st}$ moment) into spatial moment pooling (SMP) by incorporating higher order moments (such as variance, skewness). Moreover, we provide learning friendly normalization to circumvent numerical issue when computing gradients of higher moments. Experimental results suggest that simply upgrading SAP to SMP significantly enhances CNN-based blind IQA methods and achieves state of the art performance.