 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Generative Auto-bidding with Offline Reward Evaluation and Policy Search
Sep 19, 2025Auto-bidding is an essential tool for advertisers to enhance their advertising performance. Recent progress has shown that AI-Generated Bidding (AIGB), which formulates the auto-bidding as a trajectory generation task and trains a conditional diffusion-based planner on offline data, achieves superior and stable performance compared to typical offline reinforcement learning (RL)-based auto-bidding methods. However, existing AIGB methods still encounter a performance bottleneck due to their neglect of fine-grained generation quality evaluation and inability to explore beyond static datasets. To address this, we propose AIGB-Pearl (\emph{Planning with EvAluator via RL}), a novel method that integrates generative planning and policy optimization. The key to AIGB-Pearl is to construct a non-bootstrapped \emph{trajectory evaluator} to assign rewards and guide policy search, enabling the planner to optimize its generation quality iteratively through interaction. Furthermore, to enhance trajectory evaluator accuracy in offline settings, we incorporate three key techniques: (i) a Large Language Model (LLM)-based architecture for better representational capacity, (ii) hybrid point-wise and pair-wise losses for better score learning, and (iii) adaptive integration of expert feedback for better generalization ability. Extensive experiments on both simulated and real-world advertising systems demonstrate the state-of-the-art performance of our approach.
BrowseComp-ZH: Benchmarking Web Browsing Ability of Large Language Models in Chinese
May 01, 2025



As large language models (LLMs) evolve into tool-using agents, the ability to browse the web in real-time has become a critical yardstick for measuring their reasoning and retrieval competence. Existing benchmarks such as BrowseComp concentrate on English and overlook the linguistic, infrastructural, and censorship-related complexities of other major information ecosystems -- most notably Chinese. To address this gap, we introduce BrowseComp-ZH, a high-difficulty benchmark purpose-built to comprehensively evaluate LLM agents on the Chinese web. BrowseComp-ZH consists of 289 multi-hop questions spanning 11 diverse domains. Each question is reverse-engineered from a short, objective, and easily verifiable answer (e.g., a date, number, or proper noun). A two-stage quality control protocol is applied to strive for high question difficulty and answer uniqueness. We benchmark over 20 state-of-the-art language models and agentic search systems on our proposed BrowseComp-ZH. Despite their strong conversational and retrieval capabilities, most models struggle severely: a large number achieve accuracy rates below 10%, and only a handful exceed 20%. Even the best-performing system, OpenAI's DeepResearch, reaches just 42.9%. These results demonstrate the considerable difficulty of BrowseComp-ZH, where success demands not only effective retrieval strategies, but also sophisticated reasoning and information reconciliation -- capabilities that current models still struggle to master. Our dataset, construction guidelines, and benchmark results have been publicly released at https://github.com/PALIN2018/BrowseComp-ZH.
ML-LMCL: Mutual Learning and Large-Margin Contrastive Learning for Improving ASR Robustness in Spoken Language Understanding
Nov 19, 2023Spoken language understanding (SLU) is a fundamental task in the task-oriented dialogue systems. However, the inevitable errors from automatic speech recognition (ASR) usually impair the understanding performance and lead to error propagation. Although there are some attempts to address this problem through contrastive learning, they (1) treat clean manual transcripts and ASR transcripts equally without discrimination in fine-tuning; (2) neglect the fact that the semantically similar pairs are still pushed away when applying contrastive learning; (3) suffer from the problem of Kullback-Leibler (KL) vanishing. In this paper, we propose Mutual Learning and Large-Margin Contrastive Learning (ML-LMCL), a novel framework for improving ASR robustness in SLU. Specifically, in fine-tuning, we apply mutual learning and train two SLU models on the manual transcripts and the ASR transcripts, respectively, aiming to iteratively share knowledge between these two models. We also introduce a distance polarization regularizer to avoid pushing away the intra-cluster pairs as much as possible. Moreover, we use a cyclical annealing schedule to mitigate KL vanishing issue. Experiments on three datasets show that ML-LMCL outperforms existing models and achieves new state-of-the-art performance.
Exploring Recommendation Capabilities of GPT-4V(ision): A Preliminary Case Study
Nov 07, 2023



Large Multimodal Models (LMMs) have demonstrated impressive performance across various vision and language tasks, yet their potential applications in recommendation tasks with visual assistance remain unexplored. To bridge this gap, we present a preliminary case study investigating the recommendation capabilities of GPT-4V(ison), a recently released LMM by OpenAI. We construct a series of qualitative test samples spanning multiple domains and employ these samples to assess the quality of GPT-4V's responses within recommendation scenarios. Evaluation results on these test samples prove that GPT-4V has remarkable zero-shot recommendation abilities across diverse domains, thanks to its robust visual-text comprehension capabilities and extensive general knowledge. However, we have also identified some limitations in using GPT-4V for recommendations, including a tendency to provide similar responses when given similar inputs. This report concludes with an in-depth discussion of the challenges and research opportunities associated with utilizing GPT-4V in recommendation scenarios. Our objective is to explore the potential of extending LMMs from vision and language tasks to recommendation tasks. We hope to inspire further research into next-generation multimodal generative recommendation models, which can enhance user experiences by offering greater diversity and interactivity. All images and prompts used in this report will be accessible at https://github.com/PALIN2018/Evaluate_GPT-4V_Rec.
Qilin-Med-VL: Towards Chinese Large Vision-Language Model for General Healthcare
Nov 01, 2023Large Language Models (LLMs) have introduced a new era of proficiency in comprehending complex healthcare and biomedical topics. However, there is a noticeable lack of models in languages other than English and models that can interpret multi-modal input, which is crucial for global healthcare accessibility. In response, this study introduces Qilin-Med-VL, the first Chinese large vision-language model designed to integrate the analysis of textual and visual data. Qilin-Med-VL combines a pre-trained Vision Transformer (ViT) with a foundational LLM. It undergoes a thorough two-stage curriculum training process that includes feature alignment and instruction tuning. This method enhances the model's ability to generate medical captions and answer complex medical queries. We also release ChiMed-VL, a dataset consisting of more than 1M image-text pairs. This dataset has been carefully curated to enable detailed and comprehensive interpretation of medical data using various types of images.
Qilin-Med: Multi-stage Knowledge Injection Advanced Medical Large Language Model
Oct 13, 2023



Integrating large language models (LLMs) into healthcare presents potential but faces challenges. Directly pre-training LLMs for domains like medicine is resource-heavy and sometimes unfeasible. Sole reliance on Supervised Fine-tuning (SFT) can result in overconfident predictions and may not tap into domain specific insights. Addressing these challenges, we present a multi-stage training method combining Domain-specific Continued Pre-training (DCPT), SFT, and Direct Preference Optimization (DPO). A notable contribution of our study is the introduction of a 3Gb Chinese Medicine (ChiMed) dataset, encompassing medical question answering, plain texts, knowledge graphs, and dialogues, segmented into three training stages. The medical LLM trained with our pipeline, Qilin-Med, exhibits significant performance boosts. In the CPT and SFT phases, it achieves 38.4% and 40.0% accuracy on the CMExam, surpassing Baichuan-7B's 33.5%. In the DPO phase, on the Huatuo-26M test set, it scores 16.66 in BLEU-1 and 27.44 in ROUGE1, outperforming the SFT's 12.69 and 24.21. This highlights the strength of our training approach in refining LLMs for medical applications.
NADiffuSE: Noise-aware Diffusion-based Model for Speech Enhancement
Sep 03, 2023The goal of speech enhancement (SE) is to eliminate the background interference from the noisy speech signal. Generative models such as diffusion models (DM) have been applied to the task of SE because of better generalization in unseen noisy scenes. Technical routes for the DM-based SE methods can be summarized into three types: task-adapted diffusion process formulation, generator-plus-conditioner (GPC) structures and the multi-stage frameworks. We focus on the first two approaches, which are constructed under the GPC architecture and use the task-adapted diffusion process to better deal with the real noise. However, the performance of these SE models is limited by the following issues: (a) Non-Gaussian noise estimation in the task-adapted diffusion process. (b) Conditional domain bias caused by the weak conditioner design in the GPC structure. (c) Large amount of residual noise caused by unreasonable interpolation operations during inference. To solve the above problems, we propose a noise-aware diffusion-based SE model (NADiffuSE) to boost the SE performance, where the noise representation is extracted from the noisy speech signal and introduced as a global conditional information for estimating the non-Gaussian components. Furthermore, the anchor-based inference algorithm is employed to achieve a compromise between the speech distortion and noise residual. In order to mitigate the performance degradation caused by the conditional domain bias in the GPC framework, we investigate three model variants, all of which can be viewed as multi-stage SE based on the preprocessing networks for Mel spectrograms. Experimental results show that NADiffuSE outperforms other DM-based SE models under the GPC infrastructure. Audio samples are available at: https://square-of-w.github.io/NADiffuSE-demo/.
LLMRec: Benchmarking Large Language Models on Recommendation Task
Aug 23, 2023
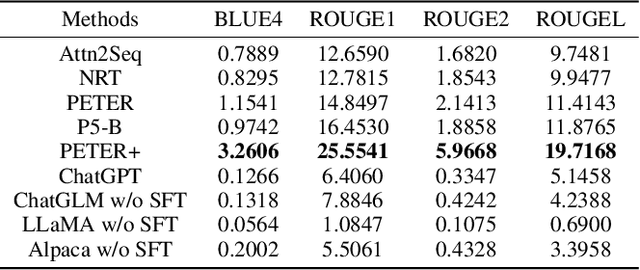


Recently, the fast development of Large Language Models (LLMs) such as ChatGPT has significantly advanced NLP tasks by enhancing the capabilities of conversational models. However, the application of LLMs in the recommendation domain has not been thoroughly investigated. To bridge this gap, we propose LLMRec, a LLM-based recommender system designed for benchmarking LLMs on various recommendation tasks. Specifically, we benchmark several popular off-the-shelf LLMs, such as ChatGPT, LLaMA, ChatGLM, on five recommendation tasks, including rating prediction, sequential recommendation, direct recommendation, explanation generation, and review summarization. Furthermore, we investigate the effectiveness of supervised finetuning to improve LLMs' instruction compliance ability. The benchmark results indicate that LLMs displayed only moderate proficiency in accuracy-based tasks such as sequential and direct recommendation. However, they demonstrated comparable performance to state-of-the-art methods in explainability-based tasks. We also conduct qualitative evaluations to further evaluate the quality of contents generated by different models, and the results show that LLMs can truly understand the provided information and generate clearer and more reasonable results. We aspire that this benchmark will serve as an inspiration for researchers to delve deeper into the potential of LLMs in enhancing recommendation performance. Our codes, processed data and benchmark results are available at https://github.com/williamliujl/LLMRec.
Attention Calibration for Transformer-based Sequential Recommendation
Aug 18, 2023



Transformer-based sequential recommendation (SR) has been booming in recent years, with the self-attention mechanism as its key component. Self-attention has been widely believed to be able to effectively select those informative and relevant items from a sequence of interacted items for next-item prediction via learning larger attention weights for these items. However, this may not always be true in reality. Our empirical analysis of some representative Transformer-based SR models reveals that it is not uncommon for large attention weights to be assigned to less relevant items, which can result in inaccurate recommendations. Through further in-depth analysis, we find two factors that may contribute to such inaccurate assignment of attention weights: sub-optimal position encoding and noisy input. To this end, in this paper, we aim to address this significant yet challenging gap in existing works. To be specific, we propose a simple yet effective framework called Attention Calibration for Transformer-based Sequential Recommendation (AC-TSR). In AC-TSR, a novel spatial calibrator and adversarial calibrator are designed respectively to directly calibrates those incorrectly assigned attention weights. The former is devised to explicitly capture the spatial relationships (i.e., order and distance) among items for more precise calculation of attention weights. The latter aims to redistribute the attention weights based on each item's contribution to the next-item prediction. AC-TSR is readily adaptable and can be seamlessly integrated into various existing transformer-based SR models. Extensive experimental results on four benchmark real-world datasets demonstrate the superiority of our proposed ACTSR via significant recommendation performance enhancements. The source code is available at https://github.com/AIM-SE/AC-TSR.
FTM: A Frame-level Timeline Modeling Method for Temporal Graph Representation Learning
Mar 15, 2023



Learning representations for graph-structured data is essential for graph analytical tasks. While remarkable progress has been made on static graphs, researches on temporal graphs are still in its beginning stage. The bottleneck of the temporal graph representation learning approach is the neighborhood aggregation strategy, based on which graph attributes share and gather information explicitly. Existing neighborhood aggregation strategies fail to capture either the short-term features or the long-term features of temporal graph attributes, leading to unsatisfactory model performance and even poor robustness and domain generality of the representation learning method. To address this problem, we propose a Frame-level Timeline Modeling (FTM) method that helps to capture both short-term and long-term features and thus learns more informative representations on temporal graphs. In particular, we present a novel link-based framing technique to preserve the short-term features and then incorporate a timeline aggregator module to capture the intrinsic dynamics of graph evolution as long-term features. Our method can be easily assembled with most temporal GNNs. Extensive experiments on common datasets show that our method brings great improvements to the capability, robustness, and domain generality of backbone methods in downstream tasks. Our code can be found at https://github.com/yeeeqichen/FTM.