 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining Report of TeleChat3-MoE
Dec 30, 2025TeleChat3-MoE is the latest series of TeleChat large language models, featuring a Mixture-of-Experts (MoE) architecture with parameter counts ranging from 105 billion to over one trillion,trained end-to-end on Ascend NPU cluster. This technical report mainly presents the underlying training infrastructure that enables reliable and efficient scaling to frontier model sizes. We detail systematic methodologies for operator-level and end-to-end numerical accuracy verification, ensuring consistency across hardware platforms and distributed parallelism strategies. Furthermore, we introduce a suite of performance optimizations, including interleaved pipeline scheduling, attention-aware data scheduling for long-sequence training,hierarchical and overlapped communication for expert parallelism, and DVM-based operator fusion. A systematic parallelization framework, leveraging analytical estimation and integer linear programming, is also proposed to optimize multi-dimensional parallelism configurations. Additionally, we present methodological approaches to cluster-level optimizations, addressing host- and device-bound bottlenecks during large-scale training tasks. These infrastructure advancements yield significant throughput improvements and near-linear scaling on clusters comprising thousands of devices, providing a robust foundation for large-scale language model development on hardware ecosystems.
PCMind-2.1-Kaiyuan-2B Technical Report
Dec 08, 2025The rapid advancement of Large Language Models (LLMs) has resulted in a significant knowledge gap between the open-source community and industry, primarily because the latter relies on closed-source, high-quality data and training recipes. To address this, we introduce PCMind-2.1-Kaiyuan-2B, a fully open-source 2-billion-parameter model focused on improving training efficiency and effectiveness under resource constraints. Our methodology includes three key innovations: a Quantile Data Benchmarking method for systematically comparing heterogeneous open-source datasets and providing insights on data mixing strategies; a Strategic Selective Repetition scheme within a multi-phase paradigm to effectively leverage sparse, high-quality data; and a Multi-Domain Curriculum Training policy that orders samples by quality. Supported by a highly optimized data preprocessing pipeline and architectural modifications for FP16 stability, Kaiyuan-2B achieves performance competitive with state-of-the-art fully open-source models, demonstrating practical and scalable solutions for resource-limited pretraining. We release all assets (including model weights, data, and code) under Apache 2.0 license at https://huggingface.co/thu-pacman/PCMind-2.1-Kaiyuan-2B.
Towards High-performance Spiking Transformers from ANN to SNN Conversion
Feb 28, 2025



Spiking neural networks (SNNs) show great potential due to their energy efficiency, fast processing capabilities, and robustness. There are two main approaches to constructing SNNs. Direct training methods require much memory, while conversion methods offer a simpler and more efficient option. However, current conversion methods mainly focus on converting convolutional neural networks (CNNs) to SNNs. Converting Transformers to SNN is challenging because of the presence of non-linear modules. In this paper, we propose an Expectation Compensation Module to preserve the accuracy of the conversion. The core idea is to use information from the previous T time-steps to calculate the expected output at time-step T. We also propose a Multi-Threshold Neuron and the corresponding Parallel Parameter normalization to address the challenge of large time steps needed for high accuracy, aiming to reduce network latency and power consumption. Our experimental results demonstrate that our approach achieves state-of-the-art performance. For example, we achieve a top-1 accuracy of 88.60\% with only a 1\% loss in accuracy using 4 time steps while consuming only 35\% of the original power of the Transformer. To our knowledge, this is the first successful Artificial Neural Network (ANN) to SNN conversion for Spiking Transformers that achieves high accuracy, low latency, and low power consumption on complex datasets. The source codes of the proposed method are available at https://github.com/h-z-h-cell/Transformer-to-SNN-ECMT.
Deep Neural Network-Based Prediction of B-Cell Epitopes for SARS-CoV and SARS-CoV-2: Enhancing Vaccine Design through Machine Learning
Nov 28, 2024



The accurate prediction of B-cell epitopes is critical for guiding vaccine development against infectious diseases, including SARS and COVID-19. This study explores the use of a deep neural network (DNN) model to predict B-cell epitopes for SARS-CoVandSARS-CoV-2,leveraging a dataset that incorporates essential protein and peptide features. Traditional sequence-based methods often struggle with large, complex datasets, but deep learning offers promising improvements in predictive accuracy. Our model employs regularization techniques, such as dropout and early stopping, to enhance generalization, while also analyzing key features, including isoelectric point and aromaticity, that influence epitope recognition. Results indicate an overall accuracy of 82% in predicting COVID-19 negative and positive cases, with room for improvement in detecting positive samples. This research demonstrates the applicability of deep learning in epitope mapping, suggesting that such approaches can enhance the speed and precision of vaccine design for emerging pathogens. Future work could incorporate structural data and diverse viral strains to further refine prediction capabilities.
Unleashing Reasoning Capability of LLMs via Scalable Question Synthesis from Scratch
Oct 24, 2024



The availability of high-quality data is one of the most important factors in improving the reasoning capability of LLMs. Existing works have demonstrated the effectiveness of creating more instruction data from seed questions or knowledge bases. Recent research indicates that continually scaling up data synthesis from strong models (e.g., GPT-4) can further elicit reasoning performance. Though promising, the open-sourced community still lacks high-quality data at scale and scalable data synthesis methods with affordable costs. To address this, we introduce ScaleQuest, a scalable and novel data synthesis method that utilizes "small-size" (e.g., 7B) open-source models to generate questions from scratch without the need for seed data with complex augmentation constraints. With the efficient ScaleQuest, we automatically constructed a mathematical reasoning dataset consisting of 1 million problem-solution pairs, which are more effective than existing open-sourced datasets. It can universally increase the performance of mainstream open-source models (i.e., Mistral, Llama3, DeepSeekMath, and Qwen2-Math) by achieving 29.2% to 46.4% gains on MATH. Notably, simply fine-tuning the Qwen2-Math-7B-Base model with our dataset can even surpass Qwen2-Math-7B-Instruct, a strong and well-aligned model on closed-source data, and proprietary models such as GPT-4-Turbo and Claude-3.5 Sonnet.
FinTruthQA: A Benchmark Dataset for Evaluating the Quality of Financial Information Disclosure
Jun 17, 2024Accurate and transparent financial information disclosure is crucial in the fields of accounting and finance, ensuring market efficiency and investor confidence. Among many information disclosure platforms, the Chinese stock exchanges' investor interactive platform provides a novel and interactive way for listed firms to disclose information of interest to investors through an online question-and-answer (Q&A) format. However, it is common for listed firms to respond to questions with limited or no substantive information, and automatically evaluating the quality of financial information disclosure on large amounts of Q&A pairs is challenging. This paper builds a benchmark FinTruthQA, that can evaluate advanced natural language processing (NLP) techniques for the automatic quality assessment of information disclosure in financial Q&A data. FinTruthQA comprises 6,000 real-world financial Q&A entries and each Q&A was manually annotated based on four conceptual dimensions of accounting. We benchmarked various NLP techniques on FinTruthQA, including statistical machine learning models, pre-trained language model and their fine-tuned versions, as well as the large language model GPT-4. Experiments showed that existing NLP models have strong predictive ability for real question identification and question relevance tasks, but are suboptimal for answer relevance and answer readability tasks. By establishing this benchmark, we provide a robust foundation for the automatic evaluation of information disclosure, significantly enhancing the transparency and quality of financial reporting. FinTruthQA can be used by auditors, regulators, and financial analysts for real-time monitoring and data-driven decision-making, as well as by researchers for advanced studies in accounting and finance, ultimately fostering greater trust and efficiency in the financial markets.
SpikingResformer: Bridging ResNet and Vision Transformer in Spiking Neural Networks
Mar 28, 2024The remarkable success of Vision Transformers in Artificial Neural Networks (ANNs) has led to a growing interest in incorporating the self-attention mechanism and transformer-based architecture into Spiking Neural Networks (SNNs). While existing methods propose spiking self-attention mechanisms that are compatible with SNNs, they lack reasonable scaling methods, and the overall architectures proposed by these methods suffer from a bottleneck in effectively extracting local features. To address these challenges, we propose a novel spiking self-attention mechanism named Dual Spike Self-Attention (DSSA) with a reasonable scaling method. Based on DSSA, we propose a novel spiking Vision Transformer architecture called SpikingResformer, which combines the ResNet-based multi-stage architecture with our proposed DSSA to improve both performance and energy efficiency while reducing parameters. Experimental results show that SpikingResformer achieves higher accuracy with fewer parameters and lower energy consumption than other spiking Vision Transformer counterparts. Notably, our SpikingResformer-L achieves 79.40% top-1 accuracy on ImageNet with 4 time-steps, which is the state-of-the-art result in the SNN field.
LM-HT SNN: Enhancing the Performance of SNN to ANN Counterpart through Learnable Multi-hierarchical Threshold Model
Feb 01, 2024



Compared to traditional Artificial Neural Network (ANN), Spiking Neural Network (SNN) has garnered widespread academic interest for its intrinsic ability to transmit information in a more biological-inspired and energy-efficient manner. However, despite previous efforts to optimize the learning gradients and model structure of SNNs through various methods, SNNs still lag behind ANNs in terms of performance to some extent. The recently proposed multi-threshold model provides more possibilities for further enhancing the learning capability of SNNs. In this paper, we rigorously analyze the relationship among the multi-threshold model, vanilla spiking model and quantized ANNs from a mathematical perspective, then propose a novel LM-HT model, which is an equidistant multi-hierarchical model that can dynamically regulate the global input current and membrane potential leakage on the time dimension. In addition, we note that the direct training algorithm based on the LM-HT model can seamlessly integrate with the traditional ANN-SNN Conversion framework. This novel hybrid learning framework can effectively improve the relatively poor performance of converted SNNs under low time latency. Extensive experimental results have demonstrated that our LM-HT model can significantly outperform previous state-of-the-art works on various types of datasets, which promote SNNs to achieve a brand-new level of performance comparable to quantized ANNs.
Dense Cross-Query-and-Support Attention Weighted Mask Aggregation for Few-Shot Segmentation
Jul 18, 2022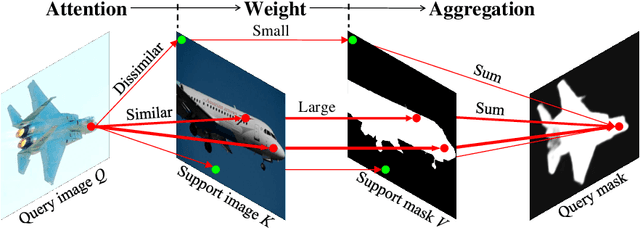
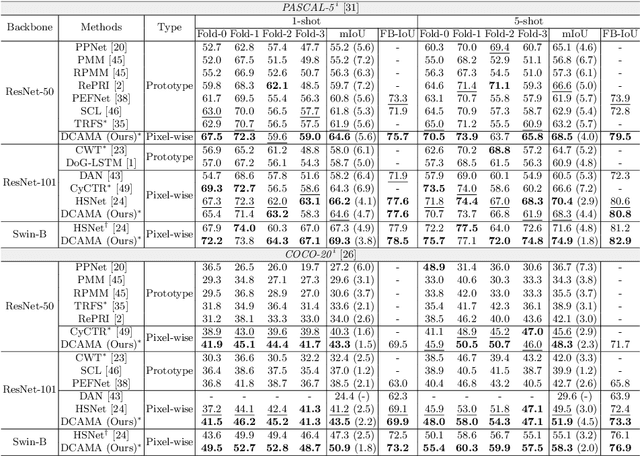
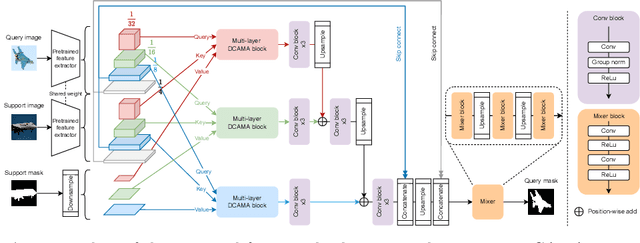
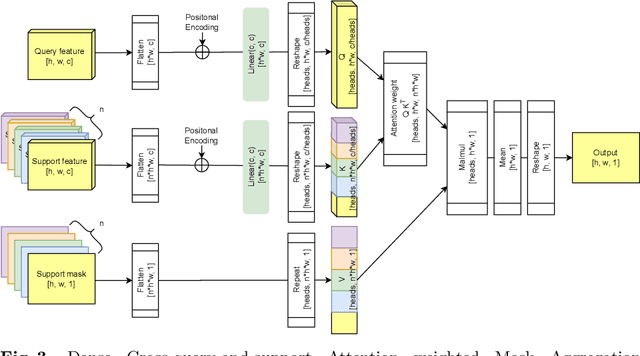
Research into Few-shot Semantic Segmentation (FSS) has attracted great attention, with the goal to segment target objects in a query image given only a few annotated support images of the target class. A key to this challenging task is to fully utilize the information in the support images by exploiting fine-grained correlations between the query and support images. However, most existing approaches either compressed the support information into a few class-wise prototypes, or used partial support information (e.g., only foreground) at the pixel level, causing non-negligible information loss. In this paper, we propose Dense pixel-wise Cross-query-and-support Attention weighted Mask Aggregation (DCAMA), where both foreground and background support information are fully exploited via multi-level pixel-wise correlations between paired query and support features. Implemented with the scaled dot-product attention in the Transformer architecture, DCAMA treats every query pixel as a token, computes its similarities with all support pixels, and predicts its segmentation label as an additive aggregation of all the support pixels' labels -- weighted by the similarities. Based on the unique formulation of DCAMA, we further propose efficient and effective one-pass inference for n-shot segmentation, where pixels of all support images are collected for the mask aggregation at once. Experiments show that our DCAMA significantly advances the state of the art on standard FSS benchmarks of PASCAL-5i, COCO-20i, and FSS-1000, e.g., with 3.1%, 9.7%, and 3.6% absolute improvements in 1-shot mIoU over previous best records. Ablative studies also verify the design DCAMA.
Deformer: Towards Displacement Field Learning for Unsupervised Medical Image Registration
Jul 07, 2022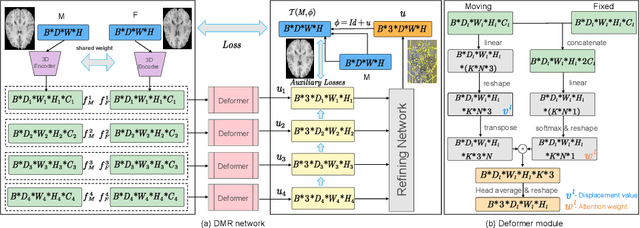
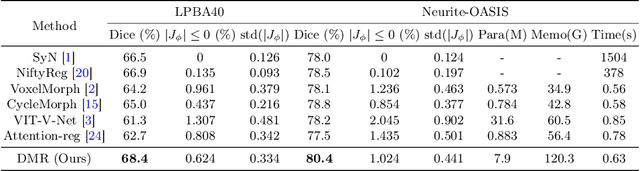
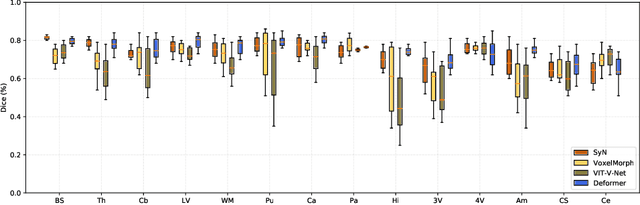
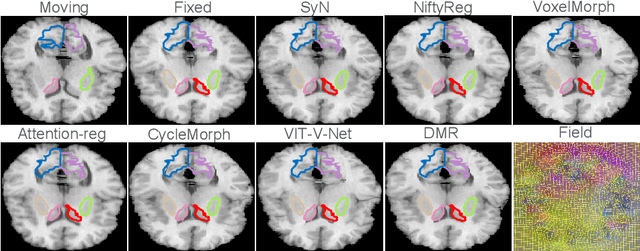
Recently, deep-learning-based approaches have been widely studied for deformable image registration task. However, most efforts directly map the composite image representation to spatial transformation through the convolutional neural network, ignoring its limited ability to capture spatial correspondence. On the other hand, Transformer can better characterize the spatial relationship with attention mechanism, its long-range dependency may be harmful to the registration task, where voxels with too large distances are unlikely to be corresponding pairs. In this study, we propose a novel Deformer module along with a multi-scale framework for the deformable image registration task. The Deformer module is designed to facilitate the mapping from image representation to spatial transformation by formulating the displacement vector prediction as the weighted summation of several bases. With the multi-scale framework to predict the displacement fields in a coarse-to-fine manner, superior performance can be achieved compared with traditional and learning-based approaches. Comprehensive experiments on two public datasets are conducted to demonstrate the effectiveness of the proposed Deformer module as well as the multi-scale framework.