 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNanning Zheng
Input-Tuning: Adapting Unfamiliar Inputs to Frozen Pretrained Models
Mar 07, 2022
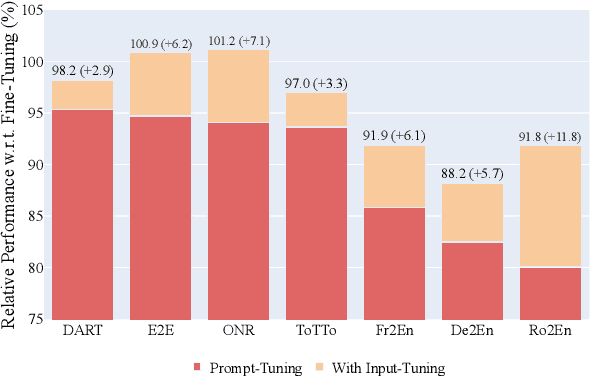

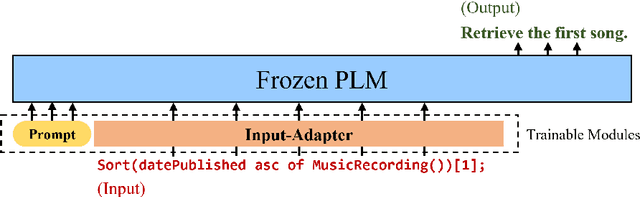
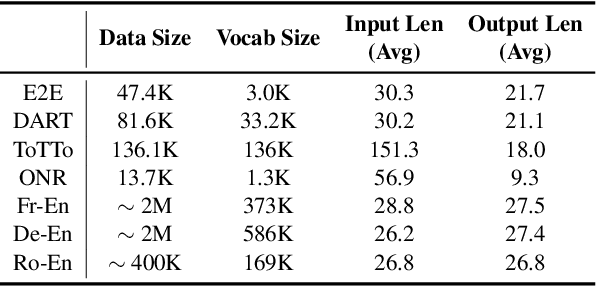
Recently the prompt-tuning paradigm has attracted significant attention. By only tuning continuous prompts with a frozen pre-trained language model (PLM), prompt-tuning takes a step towards deploying a shared frozen PLM to serve numerous downstream tasks. Although prompt-tuning shows good performance on certain natural language understanding (NLU) tasks, its effectiveness on natural language generation (NLG) tasks is still under-explored. In this paper, we argue that one of the factors hindering the development of prompt-tuning on NLG tasks is the unfamiliar inputs (i.e., inputs are linguistically different from the pretraining corpus). For example, our preliminary exploration reveals a large performance gap between prompt-tuning and fine-tuning when unfamiliar inputs occur frequently in NLG tasks. This motivates us to propose input-tuning, which fine-tunes both the continuous prompts and the input representations, leading to a more effective way to adapt unfamiliar inputs to frozen PLMs. Our proposed input-tuning is conceptually simple and empirically powerful. Experimental results on seven NLG tasks demonstrate that input-tuning is significantly and consistently better than prompt-tuning. Furthermore, on three of these tasks, input-tuning can achieve a comparable or even better performance than fine-tuning.
Trajectory Forecasting from Detection with Uncertainty-Aware Motion Encoding
Feb 10, 2022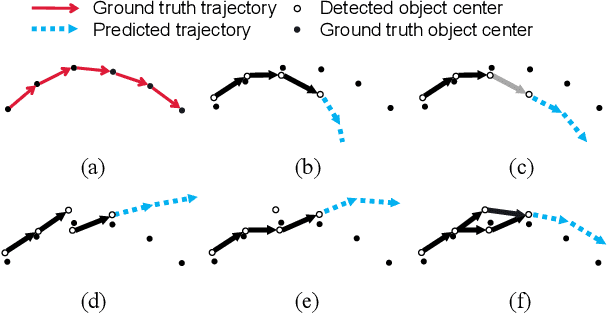

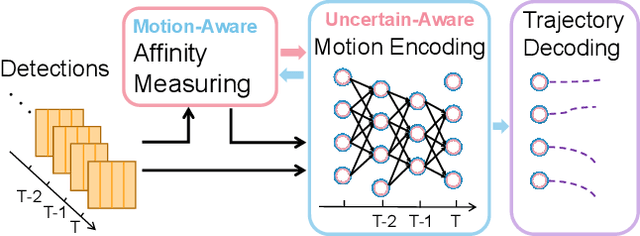

Trajectory forecasting is critical for autonomous platforms to make safe planning and actions. Currently, most trajectory forecasting methods assume that object trajectories have been extracted and directly develop trajectory predictors based on the ground truth trajectories. However, this assumption does not hold in practical situations. Trajectories obtained from object detection and tracking are inevitably noisy, which could cause serious forecasting errors to predictors built on ground truth trajectories. In this paper, we propose a trajectory predictor directly based on detection results without relying on explicitly formed trajectories. Different from the traditional methods which encode the motion cue of an agent based on its clearly defined trajectory, we extract the motion information only based on the affinity cues among detection results, in which an affinity-aware state update mechanism is designed to take the uncertainty of association into account. In addition, considering that there could be multiple plausible matching candidates, we aggregate the states of them. This design relaxes the undesirable effect of noisy trajectory obtained from data association. Extensive ablation experiments validate the effectiveness of our method and its generalization ability on different detectors. Cross-comparison to other forecasting schemes further proves the superiority of our method. Code will be released upon acceptance.
LiVLR: A Lightweight Visual-Linguistic Reasoning Framework for Video Question Answering
Nov 30, 2021
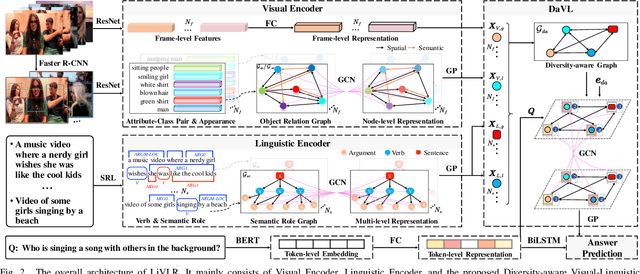
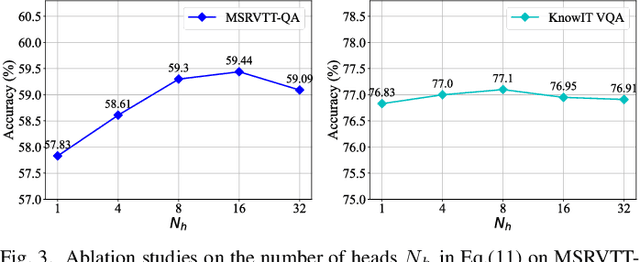
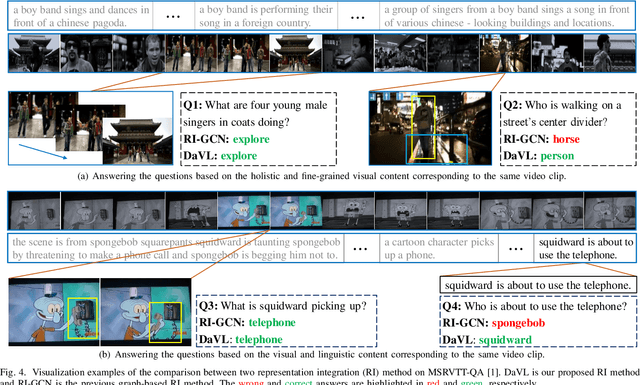
Video Question Answering (VideoQA), aiming to correctly answer the given question based on understanding multi-modal video content, is challenging due to the rich video content. From the perspective of video understanding, a good VideoQA framework needs to understand the video content at different semantic levels and flexibly integrate the diverse video content to distill question-related content. To this end, we propose a Lightweight Visual-Linguistic Reasoning framework named LiVLR. Specifically, LiVLR first utilizes the graph-based Visual and Linguistic Encoders to obtain multi-grained visual and linguistic representations. Subsequently, the obtained representations are integrated with the devised Diversity-aware Visual-Linguistic Reasoning module (DaVL). The DaVL considers the difference between the different types of representations and can flexibly adjust the importance of different types of representations when generating the question-related joint representation, which is an effective and general representation integration method. The proposed LiVLR is lightweight and shows its performance advantage on two VideoQA benchmarks, MRSVTT-QA and KnowIT VQA. Extensive ablation studies demonstrate the effectiveness of LiVLR key components.
Multi-Scale Semantics-Guided Neural Networks for Efficient Skeleton-Based Human Action Recognition
Nov 07, 2021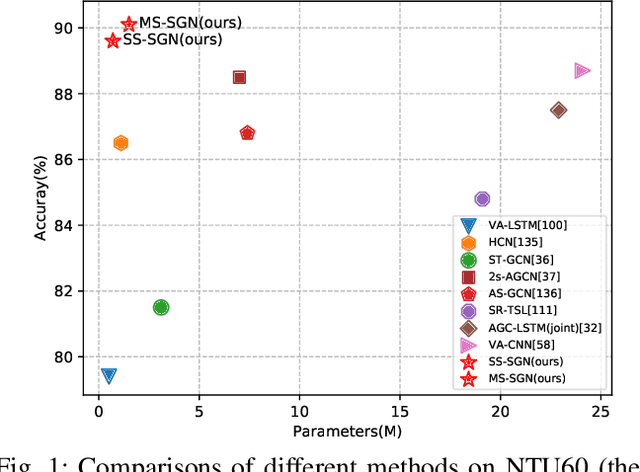

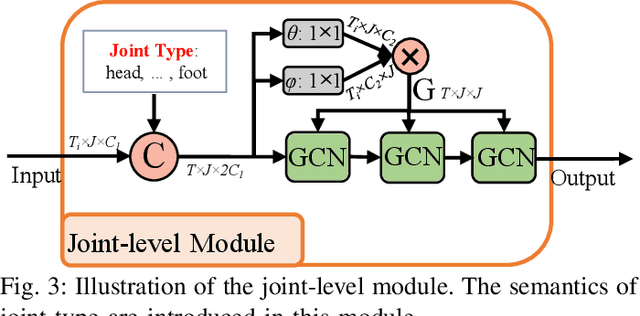
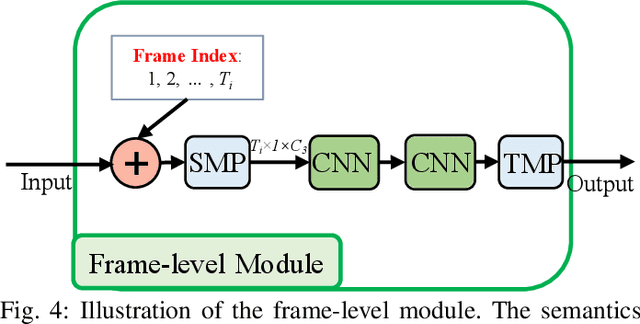
Skeleton data is of low dimension. However, there is a trend of using very deep and complicated feedforward neural networks to model the skeleton sequence without considering the complexity in recent year. In this paper, a simple yet effective multi-scale semantics-guided neural network (MS-SGN) is proposed for skeleton-based action recognition. We explicitly introduce the high level semantics of joints (joint type and frame index) into the network to enhance the feature representation capability of joints. Moreover, a multi-scale strategy is proposed to be robust to the temporal scale variations. In addition, we exploit the relationship of joints hierarchically through two modules, i.e., a joint-level module for modeling the correlations of joints in the same frame and a frame-level module for modeling the temporal dependencies of frames. With an order of magnitude smaller model size than most previous methods, MSSGN achieves the state-of-the-art performance on the NTU60, NTU120, and SYSU datasets.
Instance-Conditional Knowledge Distillation for Object Detection
Oct 25, 2021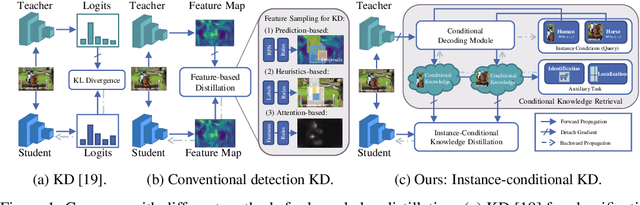
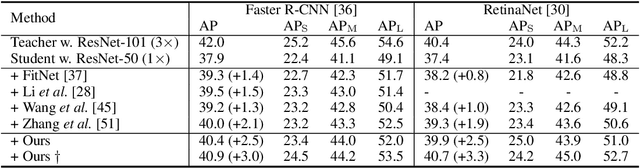
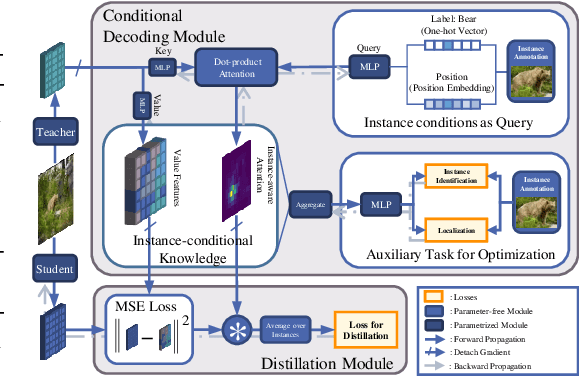
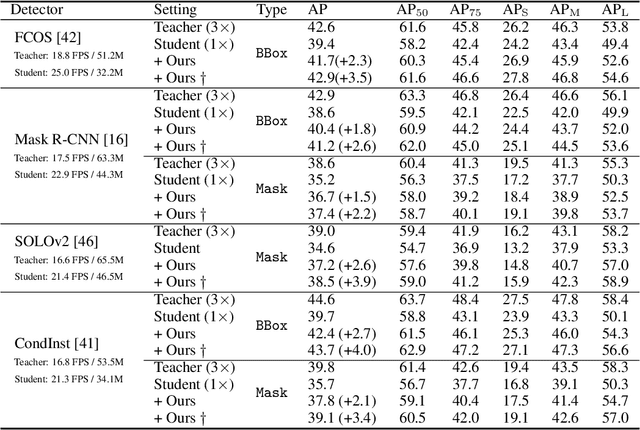
Despite the success of Knowledge Distillation (KD) on image classification, it is still challenging to apply KD on object detection due to the difficulty in locating knowledge. In this paper, we propose an instance-conditional distillation framework to find desired knowledge. To locate knowledge of each instance, we use observed instances as condition information and formulate the retrieval process as an instance-conditional decoding process. Specifically, information of each instance that specifies a condition is encoded as query, and teacher's information is presented as key, we use the attention between query and key to measure the correlation, formulated by the transformer decoder. To guide this module, we further introduce an auxiliary task that directs to instance localization and identification, which are fundamental for detection. Extensive experiments demonstrate the efficacy of our method: we observe impressive improvements under various settings. Notably, we boost RetinaNet with ResNet-50 backbone from 37.4 to 40.7 mAP (+3.3) under 1x schedule, that even surpasses the teacher (40.4 mAP) with ResNet-101 backbone under 3x schedule. Code will be released soon.
Improved Drug-target Interaction Prediction with Intermolecular Graph Transformer
Oct 15, 2021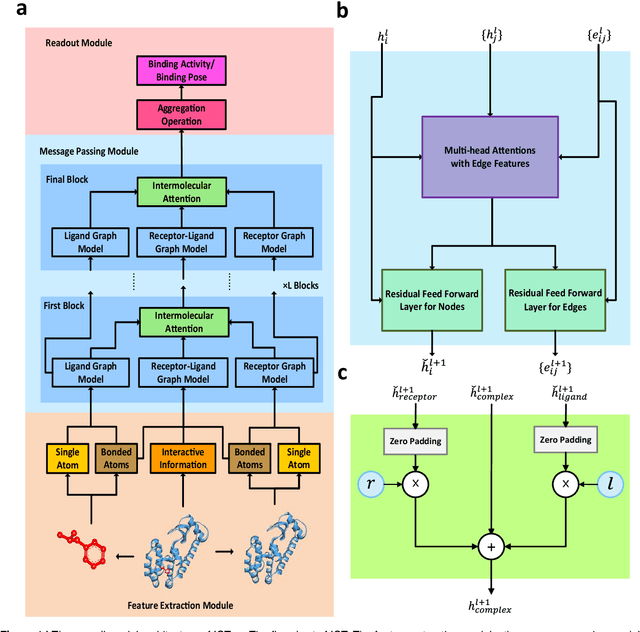
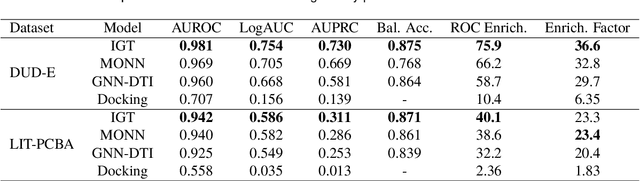
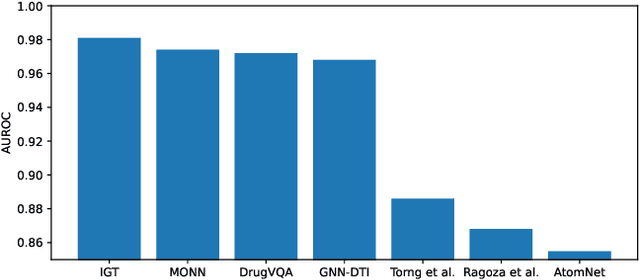

The identification of active binding drugs for target proteins (termed as drug-target interaction prediction) is the key challenge in virtual screening, which plays an essential role in drug discovery. Although recent deep learning-based approaches achieved better performance than molecular docking, existing models often neglect certain aspects of the intermolecular information, hindering the performance of prediction. We recognize this problem and propose a novel approach named Intermolecular Graph Transformer (IGT) that employs a dedicated attention mechanism to model intermolecular information with a three-way Transformer-based architecture. IGT outperforms state-of-the-art approaches by 9.1% and 20.5% over the second best for binding activity and binding pose prediction respectively, and shows superior generalization ability to unseen receptor proteins. Furthermore, IGT exhibits promising drug screening ability against SARS-CoV-2 by identifying 83.1% active drugs that have been validated by wet-lab experiments with near-native predicted binding poses.
LGD: Label-guided Self-distillation for Object Detection
Sep 23, 2021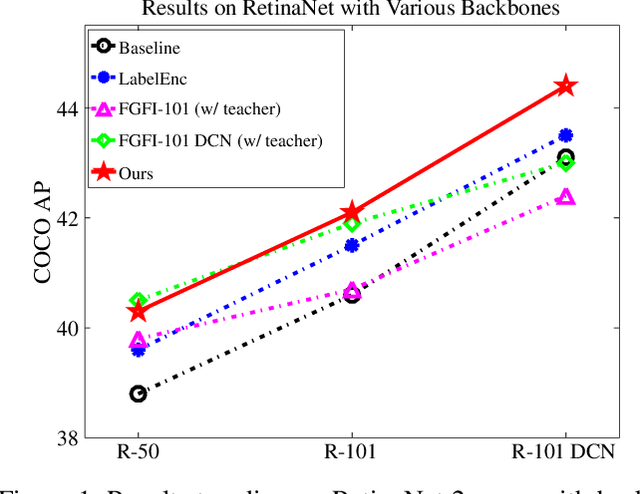
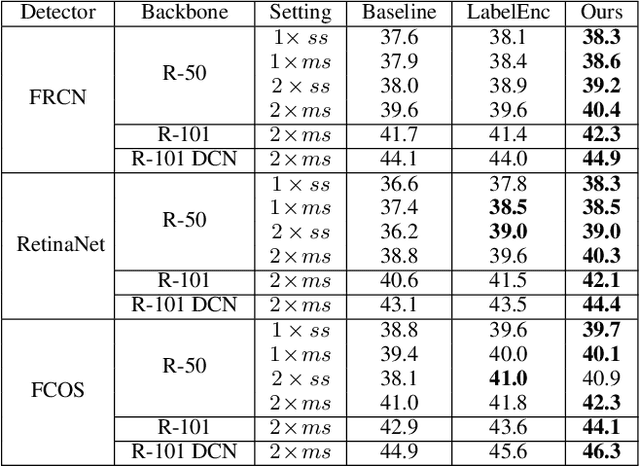
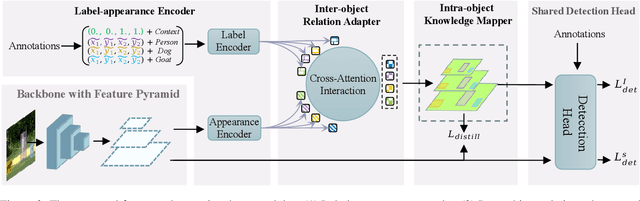
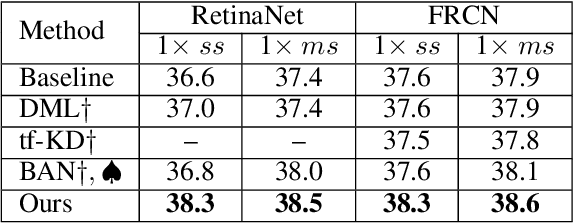
In this paper, we propose the first self-distillation framework for general object detection, termed LGD (Label-Guided self-Distillation). Previous studies rely on a strong pretrained teacher to provide instructive knowledge for distillation. However, this could be unavailable in real-world scenarios. Instead, we generate an instructive knowledge by inter-and-intra relation modeling among objects, requiring only student representations and regular labels. In detail, our framework involves sparse label-appearance encoding, inter-object relation adaptation and intra-object knowledge mapping to obtain the instructive knowledge. Modules in LGD are trained end-to-end with student detector and are discarded in inference. Empirically, LGD obtains decent results on various detectors, datasets, and extensive task like instance segmentation. For example in MS-COCO dataset, LGD improves RetinaNet with ResNet-50 under 2x single-scale training from 36.2% to 39.0% mAP (+ 2.8%). For much stronger detectors like FCOS with ResNeXt-101 DCN v2 under 2x multi-scale training (46.1%), LGD achieves 47.9% (+ 1.8%). For pedestrian detection in CrowdHuman dataset, LGD boosts mMR by 2.3% for Faster R-CNN with ResNet-50. Compared with a classical teacher-based method FGFI, LGD not only performs better without requiring pretrained teacher but also with 51% lower training cost beyond inherent student learning.
Model-based Decision Making with Imagination for Autonomous Parking
Aug 25, 2021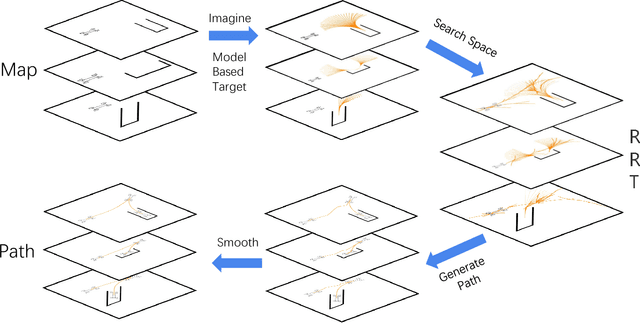
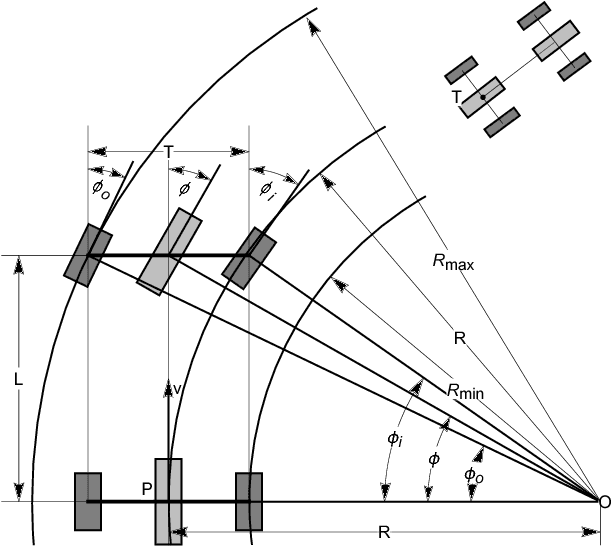
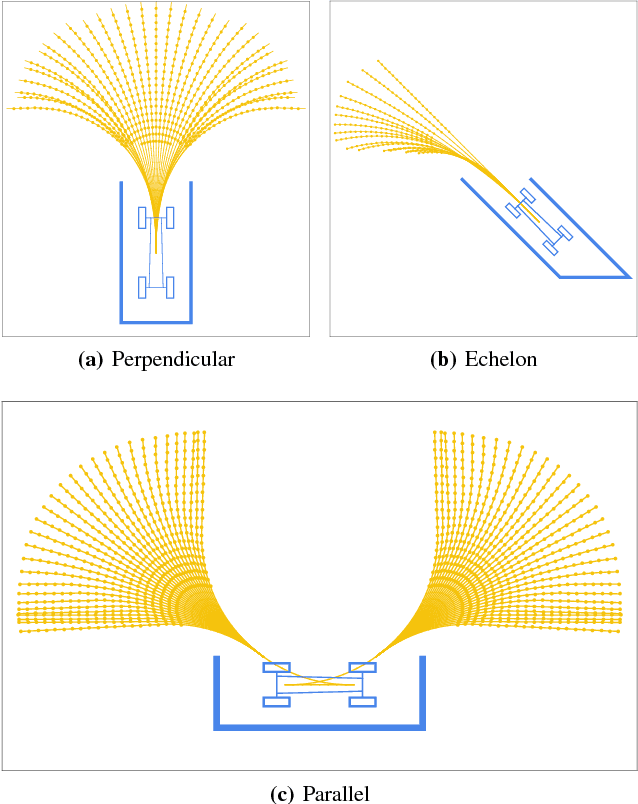
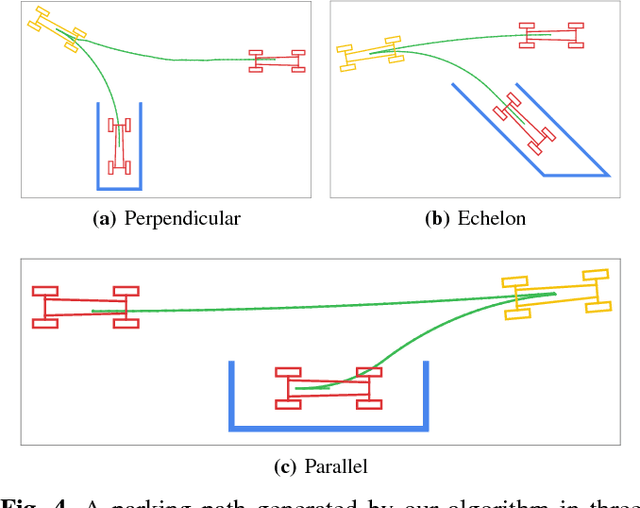
Autonomous parking technology is a key concept within autonomous driving research. This paper will propose an imaginative autonomous parking algorithm to solve issues concerned with parking. The proposed algorithm consists of three parts: an imaginative model for anticipating results before parking, an improved rapid-exploring random tree (RRT) for planning a feasible trajectory from a given start point to a parking lot, and a path smoothing module for optimizing the efficiency of parking tasks. Our algorithm is based on a real kinematic vehicle model; which makes it more suitable for algorithm application on real autonomous cars. Furthermore, due to the introduction of the imagination mechanism, the processing speed of our algorithm is ten times faster than that of traditional methods, permitting the realization of real-time planning simultaneously. In order to evaluate the algorithm's effectiveness, we have compared our algorithm with traditional RRT, within three different parking scenarios. Ultimately, results show that our algorithm is more stable than traditional RRT and performs better in terms of efficiency and quality.
* Published by IEEE IV 2018
INVIGORATE: Interactive Visual Grounding and Grasping in Clutter
Aug 25, 2021
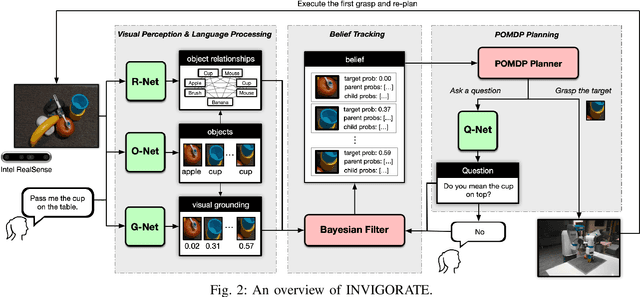

This paper presents INVIGORATE, a robot system that interacts with human through natural language and grasps a specified object in clutter. The objects may occlude, obstruct, or even stack on top of one another. INVIGORATE embodies several challenges: (i) infer the target object among other occluding objects, from input language expressions and RGB images, (ii) infer object blocking relationships (OBRs) from the images, and (iii) synthesize a multi-step plan to ask questions that disambiguate the target object and to grasp it successfully. We train separate neural networks for object detection, for visual grounding, for question generation, and for OBR detection and grasping. They allow for unrestricted object categories and language expressions, subject to the training datasets. However, errors in visual perception and ambiguity in human languages are inevitable and negatively impact the robot's performance. To overcome these uncertainties, we build a partially observable Markov decision process (POMDP) that integrates the learned neural network modules. Through approximate POMDP planning, the robot tracks the history of observations and asks disambiguation questions in order to achieve a near-optimal sequence of actions that identify and grasp the target object. INVIGORATE combines the benefits of model-based POMDP planning and data-driven deep learning. Preliminary experiments with INVIGORATE on a Fetch robot show significant benefits of this integrated approach to object grasping in clutter with natural language interactions. A demonstration video is available at https://youtu.be/zYakh80SGcU.
Unlimited Neighborhood Interaction for Heterogeneous Trajectory Prediction
Aug 16, 2021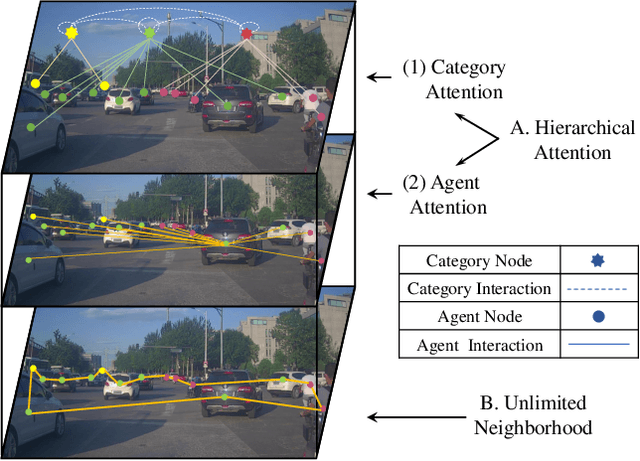
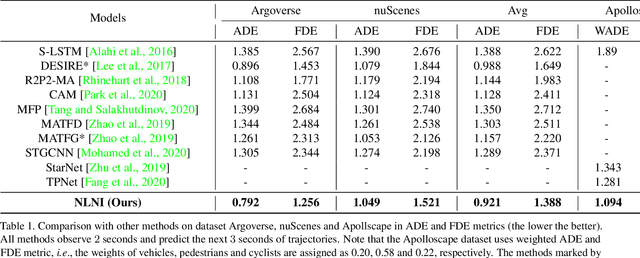
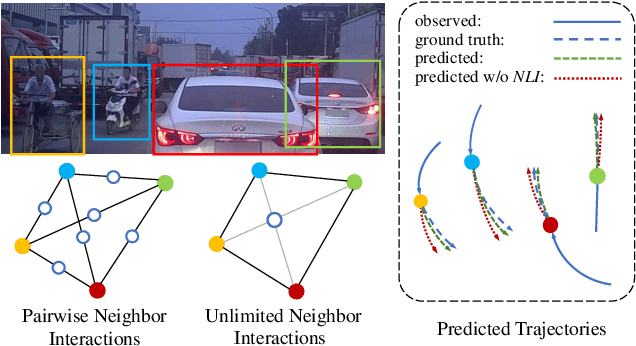
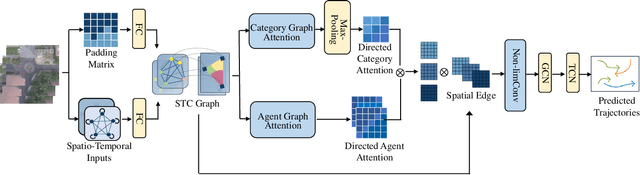
Understanding complex social interactions among agents is a key challenge for trajectory prediction. Most existing methods consider the interactions between pairwise traffic agents or in a local area, while the nature of interactions is unlimited, involving an uncertain number of agents and non-local areas simultaneously. Besides, they treat heterogeneous traffic agents the same, namely those among agents of different categories, while neglecting people's diverse reaction patterns toward traffic agents in ifferent categories. To address these problems, we propose a simple yet effective Unlimited Neighborhood Interaction Network (UNIN), which predicts trajectories of heterogeneous agents in multiple categories. Specifically, the proposed unlimited neighborhood interaction module generates the fused-features of all agents involved in an interaction simultaneously, which is adaptive to any number of agents and any range of interaction area. Meanwhile, a hierarchical graph attention module is proposed to obtain category-to-category interaction and agent-to-agent interaction. Finally, parameters of a Gaussian Mixture Model are estimated for generating the future trajectories. Extensive experimental results on benchmark datasets demonstrate a significant performance improvement of our method over the state-of-the-art methods.