 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Events to Clarity: The Event-Guided Diffusion Framework for Dehazing
Nov 14, 2025Clear imaging under hazy conditions is a critical task. Prior-based and neural methods have improved results. However, they operate on RGB frames, which suffer from limited dynamic range. Therefore, dehazing remains ill-posed and can erase structure and illumination details. To address this, we use event cameras for dehazing for the \textbf{first time}. Event cameras offer much higher HDR ($120 dBvs.60 dB$) and microsecond latency, therefore they suit hazy scenes. In practice, transferring HDR cues from events to frames is hard because real paired data are scarce. To tackle this, we propose an event-guided diffusion model that utilizes the strong generative priors of diffusion models to reconstruct clear images from hazy inputs by effectively transferring HDR information from events. Specifically, we design an event-guided module that maps sparse HDR event features, \textit{e.g.,} edges, corners, into the diffusion latent space. This clear conditioning provides precise structural guidance during generation, improves visual realism, and reduces semantic drift. For real-world evaluation, we collect a drone dataset in heavy haze (AQI = 341) with synchronized RGB and event sensors. Experiments on two benchmarks and our dataset achieve state-of-the-art results.
Beyond Boundaries: Leveraging Vision Foundation Models for Source-Free Object Detection
Nov 10, 2025Source-Free Object Detection (SFOD) aims to adapt a source-pretrained object detector to a target domain without access to source data. However, existing SFOD methods predominantly rely on internal knowledge from the source model, which limits their capacity to generalize across domains and often results in biased pseudo-labels, thereby hindering both transferability and discriminability. In contrast, Vision Foundation Models (VFMs), pretrained on massive and diverse data, exhibit strong perception capabilities and broad generalization, yet their potential remains largely untapped in the SFOD setting. In this paper, we propose a novel SFOD framework that leverages VFMs as external knowledge sources to jointly enhance feature alignment and label quality. Specifically, we design three VFM-based modules: (1) Patch-weighted Global Feature Alignment (PGFA) distills global features from VFMs using patch-similarity-based weighting to enhance global feature transferability; (2) Prototype-based Instance Feature Alignment (PIFA) performs instance-level contrastive learning guided by momentum-updated VFM prototypes; and (3) Dual-source Enhanced Pseudo-label Fusion (DEPF) fuses predictions from detection VFMs and teacher models via an entropy-aware strategy to yield more reliable supervision. Extensive experiments on six benchmarks demonstrate that our method achieves state-of-the-art SFOD performance, validating the effectiveness of integrating VFMs to simultaneously improve transferability and discriminability.
Binarized Mamba-Transformer for Lightweight Quad Bayer HybridEVS Demosaicing
Mar 20, 2025
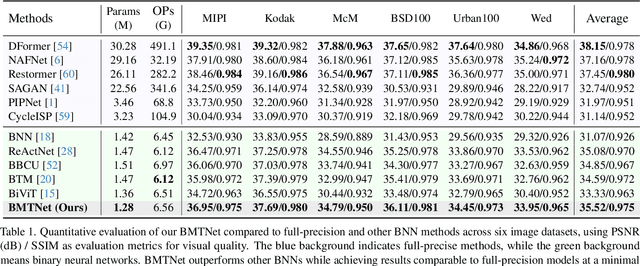
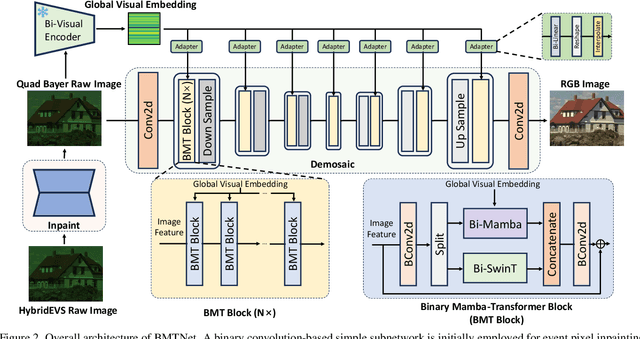

Quad Bayer demosaicing is the central challenge for enabling the widespread application of Hybrid Event-based Vision Sensors (HybridEVS). Although existing learning-based methods that leverage long-range dependency modeling have achieved promising results, their complexity severely limits deployment on mobile devices for real-world applications. To address these limitations, we propose a lightweight Mamba-based binary neural network designed for efficient and high-performing demosaicing of HybridEVS RAW images. First, to effectively capture both global and local dependencies, we introduce a hybrid Binarized Mamba-Transformer architecture that combines the strengths of the Mamba and Swin Transformer architectures. Next, to significantly reduce computational complexity, we propose a binarized Mamba (Bi-Mamba), which binarizes all projections while retaining the core Selective Scan in full precision. Bi-Mamba also incorporates additional global visual information to enhance global context and mitigate precision loss. We conduct quantitative and qualitative experiments to demonstrate the effectiveness of BMTNet in both performance and computational efficiency, providing a lightweight demosaicing solution suited for real-world edge devices. Our codes and models are available at https://github.com/Clausy9/BMTNet.
SEE: See Everything Every Time -- Adaptive Brightness Adjustment for Broad Light Range Images via Events
Feb 28, 2025Event cameras, with a high dynamic range exceeding $120dB$, significantly outperform traditional embedded cameras, robustly recording detailed changing information under various lighting conditions, including both low- and high-light situations. However, recent research on utilizing event data has primarily focused on low-light image enhancement, neglecting image enhancement and brightness adjustment across a broader range of lighting conditions, such as normal or high illumination. Based on this, we propose a novel research question: how to employ events to enhance and adaptively adjust the brightness of images captured under broad lighting conditions? To investigate this question, we first collected a new dataset, SEE-600K, consisting of 610,126 images and corresponding events across 202 scenarios, each featuring an average of four lighting conditions with over a 1000-fold variation in illumination. Subsequently, we propose a framework that effectively utilizes events to smoothly adjust image brightness through the use of prompts. Our framework captures color through sensor patterns, uses cross-attention to model events as a brightness dictionary, and adjusts the image's dynamic range to form a broad light-range representation (BLR), which is then decoded at the pixel level based on the brightness prompt. Experimental results demonstrate that our method not only performs well on the low-light enhancement dataset but also shows robust performance on broader light-range image enhancement using the SEE-600K dataset. Additionally, our approach enables pixel-level brightness adjustment, providing flexibility for post-processing and inspiring more imaging applications. The dataset and source code are publicly available at:https://github.com/yunfanLu/SEE.
RGB-Event ISP: The Dataset and Benchmark
Jan 31, 2025



Event-guided imaging has received significant attention due to its potential to revolutionize instant imaging systems. However, the prior methods primarily focus on enhancing RGB images in a post-processing manner, neglecting the challenges of image signal processor (ISP) dealing with event sensor and the benefits events provide for reforming the ISP process. To achieve this, we conduct the first research on event-guided ISP. First, we present a new event-RAW paired dataset, collected with a novel but still confidential sensor that records pixel-level aligned events and RAW images. This dataset includes 3373 RAW images with 2248 x 3264 resolution and their corresponding events, spanning 24 scenes with 3 exposure modes and 3 lenses. Second, we propose a conventional ISP pipeline to generate good RGB frames as reference. This conventional ISP pipleline performs basic ISP operations, e.g.demosaicing, white balancing, denoising and color space transforming, with a ColorChecker as reference. Third, we classify the existing learnable ISP methods into 3 classes, and select multiple methods to train and evaluate on our new dataset. Lastly, since there is no prior work for reference, we propose a simple event-guided ISP method and test it on our dataset. We further put forward key technical challenges and future directions in RGB-Event ISP. In summary, to the best of our knowledge, this is the very first research focusing on event-guided ISP, and we hope it will inspire the community. The code and dataset are available at: https://github.com/yunfanLu/RGB-Event-ISP.
EventVL: Understand Event Streams via Multimodal Large Language Model
Jan 23, 2025The event-based Vision-Language Model (VLM) recently has made good progress for practical vision tasks. However, most of these works just utilize CLIP for focusing on traditional perception tasks, which obstruct model understanding explicitly the sufficient semantics and context from event streams. To address the deficiency, we propose EventVL, the first generative event-based MLLM (Multimodal Large Language Model) framework for explicit semantic understanding. Specifically, to bridge the data gap for connecting different modalities semantics, we first annotate a large event-image/video-text dataset, containing almost 1.4 million high-quality pairs of data, which enables effective learning across various scenes, e.g., drive scene or human motion. After that, we design Event Spatiotemporal Representation to fully explore the comprehensive information by diversely aggregating and segmenting the event stream. To further promote a compact semantic space, Dynamic Semantic Alignment is introduced to improve and complete sparse semantic spaces of events. Extensive experiments show that our EventVL can significantly surpass existing MLLM baselines in event captioning and scene description generation tasks. We hope our research could contribute to the development of the event vision community.
EvLight++: Low-Light Video Enhancement with an Event Camera: A Large-Scale Real-World Dataset, Novel Method, and More
Aug 29, 2024



Event cameras offer significant advantages for low-light video enhancement, primarily due to their high dynamic range. Current research, however, is severely limited by the absence of large-scale, real-world, and spatio-temporally aligned event-video datasets. To address this, we introduce a large-scale dataset with over 30,000 pairs of frames and events captured under varying illumination. This dataset was curated using a robotic arm that traces a consistent non-linear trajectory, achieving spatial alignment precision under 0.03mm and temporal alignment with errors under 0.01s for 90% of the dataset. Based on the dataset, we propose \textbf{EvLight++}, a novel event-guided low-light video enhancement approach designed for robust performance in real-world scenarios. Firstly, we design a multi-scale holistic fusion branch to integrate structural and textural information from both images and events. To counteract variations in regional illumination and noise, we introduce Signal-to-Noise Ratio (SNR)-guided regional feature selection, enhancing features from high SNR regions and augmenting those from low SNR regions by extracting structural information from events. To incorporate temporal information and ensure temporal coherence, we further introduce a recurrent module and temporal loss in the whole pipeline. Extensive experiments on our and the synthetic SDSD dataset demonstrate that EvLight++ significantly outperforms both single image- and video-based methods by 1.37 dB and 3.71 dB, respectively. To further explore its potential in downstream tasks like semantic segmentation and monocular depth estimation, we extend our datasets by adding pseudo segmentation and depth labels via meticulous annotation efforts with foundation models. Experiments under diverse low-light scenes show that the enhanced results achieve a 15.97% improvement in mIoU for semantic segmentation.
Revisit Event Generation Model: Self-Supervised Learning of Event-to-Video Reconstruction with Implicit Neural Representations
Jul 26, 2024



Reconstructing intensity frames from event data while maintaining high temporal resolution and dynamic range is crucial for bridging the gap between event-based and frame-based computer vision. Previous approaches have depended on supervised learning on synthetic data, which lacks interpretability and risk over-fitting to the setting of the event simulator. Recently, self-supervised learning (SSL) based methods, which primarily utilize per-frame optical flow to estimate intensity via photometric constancy, has been actively investigated. However, they are vulnerable to errors in the case of inaccurate optical flow. This paper proposes a novel SSL event-to-video reconstruction approach, dubbed EvINR, which eliminates the need for labeled data or optical flow estimation. Our core idea is to reconstruct intensity frames by directly addressing the event generation model, essentially a partial differential equation (PDE) that describes how events are generated based on the time-varying brightness signals. Specifically, we utilize an implicit neural representation (INR), which takes in spatiotemporal coordinate $(x, y, t)$ and predicts intensity values, to represent the solution of the event generation equation. The INR, parameterized as a fully-connected Multi-layer Perceptron (MLP), can be optimized with its temporal derivatives supervised by events. To make EvINR feasible for online requisites, we propose several acceleration techniques that substantially expedite the training process. Comprehensive experiments demonstrate that our EvINR surpasses previous SSL methods by 38% w.r.t. Mean Squared Error (MSE) and is comparable or superior to SoTA supervised methods. Project page: https://vlislab22.github.io/EvINR/.
BiGym: A Demo-Driven Mobile Bi-Manual Manipulation Benchmark
Jul 11, 2024



We introduce BiGym, a new benchmark and learning environment for mobile bi-manual demo-driven robotic manipulation. BiGym features 40 diverse tasks set in home environments, ranging from simple target reaching to complex kitchen cleaning. To capture the real-world performance accurately, we provide human-collected demonstrations for each task, reflecting the diverse modalities found in real-world robot trajectories. BiGym supports a variety of observations, including proprioceptive data and visual inputs such as RGB, and depth from 3 camera views. To validate the usability of BiGym, we thoroughly benchmark the state-of-the-art imitation learning algorithms and demo-driven reinforcement learning algorithms within the environment and discuss the future opportunities.
HR-INR: Continuous Space-Time Video Super-Resolution via Event Camera
May 22, 2024



Continuous space-time video super-resolution (C-STVSR) aims to simultaneously enhance video resolution and frame rate at an arbitrary scale. Recently, implicit neural representation (INR) has been applied to video restoration, representing videos as implicit fields that can be decoded at an arbitrary scale. However, the highly ill-posed nature of C-STVSR limits the effectiveness of current INR-based methods: they assume linear motion between frames and use interpolation or feature warping to generate features at arbitrary spatiotemporal positions with two consecutive frames. This restrains C-STVSR from capturing rapid and nonlinear motion and long-term dependencies (involving more than two frames) in complex dynamic scenes. In this paper, we propose a novel C-STVSR framework, called HR-INR, which captures both holistic dependencies and regional motions based on INR. It is assisted by an event camera, a novel sensor renowned for its high temporal resolution and low latency. To fully utilize the rich temporal information from events, we design a feature extraction consisting of (1) a regional event feature extractor - taking events as inputs via the proposed event temporal pyramid representation to capture the regional nonlinear motion and (2) a holistic event-frame feature extractor for long-term dependence and continuity motion. We then propose a novel INR-based decoder with spatiotemporal embeddings to capture long-term dependencies with a larger temporal perception field. We validate the effectiveness and generalization of our method on four datasets (both simulated and real data), showing the superiority of our method.