 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatial Mental Modeling from Limited Views
Jun 26, 2025



Can Vision Language Models (VLMs) imagine the full scene from just a few views, like humans do? Humans form spatial mental models, internal representations of unseen space, to reason about layout, perspective, and motion. Our new MindCube benchmark with 21,154 questions across 3,268 images exposes this critical gap, where existing VLMs exhibit near-random performance. Using MindCube, we systematically evaluate how well VLMs build robust spatial mental models through representing positions (cognitive mapping), orientations (perspective-taking), and dynamics (mental simulation for "what-if" movements). We then explore three approaches to help VLMs approximate spatial mental models, including unseen intermediate views, natural language reasoning chains, and cognitive maps. The significant improvement comes from a synergistic approach, "map-then-reason", that jointly trains the model to first generate a cognitive map and then reason upon it. By training models to reason over these internal maps, we boosted accuracy from 37.8% to 60.8% (+23.0%). Adding reinforcement learning pushed performance even further to 70.7% (+32.9%). Our key insight is that such scaffolding of spatial mental models, actively constructing and utilizing internal structured spatial representations with flexible reasoning processes, significantly improves understanding of unobservable space.
Exploring Diffusion Transformer Designs via Grafting
Jun 06, 2025Designing model architectures requires decisions such as selecting operators (e.g., attention, convolution) and configurations (e.g., depth, width). However, evaluating the impact of these decisions on model quality requires costly pretraining, limiting architectural investigation. Inspired by how new software is built on existing code, we ask: can new architecture designs be studied using pretrained models? To this end, we present grafting, a simple approach for editing pretrained diffusion transformers (DiTs) to materialize new architectures under small compute budgets. Informed by our analysis of activation behavior and attention locality, we construct a testbed based on the DiT-XL/2 design to study the impact of grafting on model quality. Using this testbed, we develop a family of hybrid designs via grafting: replacing softmax attention with gated convolution, local attention, and linear attention, and replacing MLPs with variable expansion ratio and convolutional variants. Notably, many hybrid designs achieve good quality (FID: 2.38-2.64 vs. 2.27 for DiT-XL/2) using <2% pretraining compute. We then graft a text-to-image model (PixArt-Sigma), achieving a 1.43x speedup with less than a 2% drop in GenEval score. Finally, we present a case study that restructures DiT-XL/2 by converting every pair of sequential transformer blocks into parallel blocks via grafting. This reduces model depth by 2x and yields better quality (FID: 2.77) than other models of comparable depth. Together, we show that new diffusion model designs can be explored by grafting pretrained DiTs, with edits ranging from operator replacement to architecture restructuring. Code and grafted models: https://grafting.stanford.edu
Bring Reason to Vision: Understanding Perception and Reasoning through Model Merging
May 08, 2025Vision-Language Models (VLMs) combine visual perception with the general capabilities, such as reasoning, of Large Language Models (LLMs). However, the mechanisms by which these two abilities can be combined and contribute remain poorly understood. In this work, we explore to compose perception and reasoning through model merging that connects parameters of different models. Unlike previous works that often focus on merging models of the same kind, we propose merging models across modalities, enabling the incorporation of the reasoning capabilities of LLMs into VLMs. Through extensive experiments, we demonstrate that model merging offers a successful pathway to transfer reasoning abilities from LLMs to VLMs in a training-free manner. Moreover, we utilize the merged models to understand the internal mechanism of perception and reasoning and how merging affects it. We find that perception capabilities are predominantly encoded in the early layers of the model, whereas reasoning is largely facilitated by the middle-to-late layers. After merging, we observe that all layers begin to contribute to reasoning, whereas the distribution of perception abilities across layers remains largely unchanged. These observations shed light on the potential of model merging as a tool for multimodal integration and interpretation.
RAGEN: Understanding Self-Evolution in LLM Agents via Multi-Turn Reinforcement Learning
Apr 24, 2025Training large language models (LLMs) as interactive agents presents unique challenges including long-horizon decision making and interacting with stochastic environment feedback. While reinforcement learning (RL) has enabled progress in static tasks, multi-turn agent RL training remains underexplored. We propose StarPO (State-Thinking-Actions-Reward Policy Optimization), a general framework for trajectory-level agent RL, and introduce RAGEN, a modular system for training and evaluating LLM agents. Our study on three stylized environments reveals three core findings. First, our agent RL training shows a recurring mode of Echo Trap where reward variance cliffs and gradient spikes; we address this with StarPO-S, a stabilized variant with trajectory filtering, critic incorporation, and decoupled clipping. Second, we find the shaping of RL rollouts would benefit from diverse initial states, medium interaction granularity and more frequent sampling. Third, we show that without fine-grained, reasoning-aware reward signals, agent reasoning hardly emerge through multi-turn RL and they may show shallow strategies or hallucinated thoughts. Code and environments are available at https://github.com/RAGEN-AI/RAGEN.
Re-thinking Temporal Search for Long-Form Video Understanding
Apr 03, 2025



Efficient understanding of long-form videos remains a significant challenge in computer vision. In this work, we revisit temporal search paradigms for long-form video understanding, studying a fundamental issue pertaining to all state-of-the-art (SOTA) long-context vision-language models (VLMs). In particular, our contributions are two-fold: First, we formulate temporal search as a Long Video Haystack problem, i.e., finding a minimal set of relevant frames (typically one to five) among tens of thousands of frames from real-world long videos given specific queries. To validate our formulation, we create LV-Haystack, the first benchmark containing 3,874 human-annotated instances with fine-grained evaluation metrics for assessing keyframe search quality and computational efficiency. Experimental results on LV-Haystack highlight a significant research gap in temporal search capabilities, with SOTA keyframe selection methods achieving only 2.1% temporal F1 score on the LVBench subset. Next, inspired by visual search in images, we re-think temporal searching and propose a lightweight keyframe searching framework, T*, which casts the expensive temporal search as a spatial search problem. T* leverages superior visual localization capabilities typically used in images and introduces an adaptive zooming-in mechanism that operates across both temporal and spatial dimensions. Our extensive experiments show that when integrated with existing methods, T* significantly improves SOTA long-form video understanding performance. Specifically, under an inference budget of 32 frames, T* improves GPT-4o's performance from 50.5% to 53.1% and LLaVA-OneVision-72B's performance from 56.5% to 62.4% on LongVideoBench XL subset. Our PyTorch code, benchmark dataset and models are included in the Supplementary material.
Why Is Spatial Reasoning Hard for VLMs? An Attention Mechanism Perspective on Focus Areas
Mar 04, 2025



Large Vision Language Models (VLMs) have long struggled with spatial reasoning tasks. Surprisingly, even simple spatial reasoning tasks, such as recognizing "under" or "behind" relationships between only two objects, pose significant challenges for current VLMs. In this work, we study the spatial reasoning challenge from the lens of mechanistic interpretability, diving into the model's internal states to examine the interactions between image and text tokens. By tracing attention distribution over the image through out intermediate layers, we observe that successful spatial reasoning correlates strongly with the model's ability to align its attention distribution with actual object locations, particularly differing between familiar and unfamiliar spatial relationships. Motivated by these findings, we propose ADAPTVIS based on inference-time confidence scores to sharpen the attention on highly relevant regions when confident, while smoothing and broadening the attention window to consider a wider context when confidence is lower. This training-free decoding method shows significant improvement (e.g., up to a 50 absolute point improvement) on spatial reasoning benchmarks such as WhatsUp and VSR with negligible cost. We make code and data publicly available for research purposes at https://github.com/shiqichen17/AdaptVis.
The Law of Knowledge Overshadowing: Towards Understanding, Predicting, and Preventing LLM Hallucination
Feb 22, 2025



Hallucination is a persistent challenge in large language models (LLMs), where even with rigorous quality control, models often generate distorted facts. This paradox, in which error generation continues despite high-quality training data, calls for a deeper understanding of the underlying LLM mechanisms. To address it, we propose a novel concept: knowledge overshadowing, where model's dominant knowledge can obscure less prominent knowledge during text generation, causing the model to fabricate inaccurate details. Building on this idea, we introduce a novel framework to quantify factual hallucinations by modeling knowledge overshadowing. Central to our approach is the log-linear law, which predicts that the rate of factual hallucination increases linearly with the logarithmic scale of (1) Knowledge Popularity, (2) Knowledge Length, and (3) Model Size. The law provides a means to preemptively quantify hallucinations, offering foresight into their occurrence even before model training or inference. Built on overshadowing effect, we propose a new decoding strategy CoDa, to mitigate hallucinations, which notably enhance model factuality on Overshadow (27.9%), MemoTrap (13.1%) and NQ-Swap (18.3%). Our findings not only deepen understandings of the underlying mechanisms behind hallucinations but also provide actionable insights for developing more predictable and controllable language models.
EmbodiedBench: Comprehensive Benchmarking Multi-modal Large Language Models for Vision-Driven Embodied Agents
Feb 13, 2025



Leveraging Multi-modal Large Language Models (MLLMs) to create embodied agents offers a promising avenue for tackling real-world tasks. While language-centric embodied agents have garnered substantial attention, MLLM-based embodied agents remain underexplored due to the lack of comprehensive evaluation frameworks. To bridge this gap, we introduce EmbodiedBench, an extensive benchmark designed to evaluate vision-driven embodied agents. EmbodiedBench features: (1) a diverse set of 1,128 testing tasks across four environments, ranging from high-level semantic tasks (e.g., household) to low-level tasks involving atomic actions (e.g., navigation and manipulation); and (2) six meticulously curated subsets evaluating essential agent capabilities like commonsense reasoning, complex instruction understanding, spatial awareness, visual perception, and long-term planning. Through extensive experiments, we evaluated 13 leading proprietary and open-source MLLMs within EmbodiedBench. Our findings reveal that: MLLMs excel at high-level tasks but struggle with low-level manipulation, with the best model, GPT-4o, scoring only 28.9% on average. EmbodiedBench provides a multifaceted standardized evaluation platform that not only highlights existing challenges but also offers valuable insights to advance MLLM-based embodied agents. Our code is available at https://embodiedbench.github.io.
SyncMind: Measuring Agent Out-of-Sync Recovery in Collaborative Software Engineering
Feb 10, 2025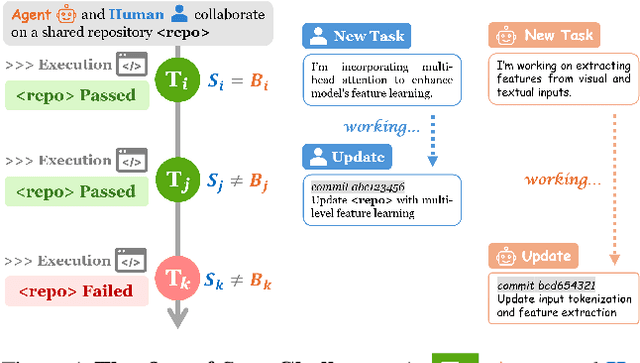
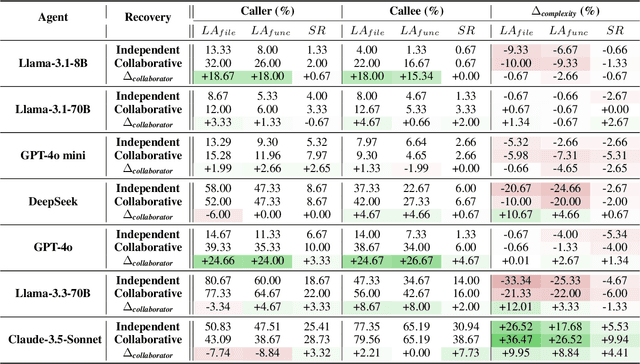


Software engineering (SE) is increasingly collaborative, with developers working together on shared complex codebases. Effective collaboration in shared environments requires participants -- whether humans or AI agents -- to stay on the same page as their environment evolves. When a collaborator's understanding diverges from the current state -- what we term the out-of-sync challenge -- the collaborator's actions may fail, leading to integration issues. In this work, we introduce SyncMind, a framework that systematically defines the out-of-sync problem faced by large language model (LLM) agents in collaborative software engineering (CSE). Based on SyncMind, we create SyncBench, a benchmark featuring 24,332 instances of agent out-of-sync scenarios in real-world CSE derived from 21 popular GitHub repositories with executable verification tests. Experiments on SyncBench uncover critical insights into existing LLM agents' capabilities and limitations. Besides substantial performance gaps among agents (from Llama-3.1 agent <= 3.33% to Claude-3.5-Sonnet >= 28.18%), their consistently low collaboration willingness (<= 4.86%) suggests fundamental limitations of existing LLM in CSE. However, when collaboration occurs, it positively correlates with out-of-sync recovery success. Minimal performance differences in agents' resource-aware out-of-sync recoveries further reveal their significant lack of resource awareness and adaptability, shedding light on future resource-efficient collaborative systems. Code and data are openly available on our project website: https://xhguo7.github.io/SyncMind/.
LayoutVLM: Differentiable Optimization of 3D Layout via Vision-Language Models
Dec 03, 2024Open-universe 3D layout generation arranges unlabeled 3D assets conditioned on language instruction. Large language models (LLMs) struggle with generating physically plausible 3D scenes and adherence to input instructions, particularly in cluttered scenes. We introduce LayoutVLM, a framework and scene layout representation that exploits the semantic knowledge of Vision-Language Models (VLMs) and supports differentiable optimization to ensure physical plausibility. LayoutVLM employs VLMs to generate two mutually reinforcing representations from visually marked images, and a self-consistent decoding process to improve VLMs spatial planning. Our experiments show that LayoutVLM addresses the limitations of existing LLM and constraint-based approaches, producing physically plausible 3D layouts better aligned with the semantic intent of input language instructions. We also demonstrate that fine-tuning VLMs with the proposed scene layout representation extracted from existing scene datasets can improve performance.