 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReasoning Path Divergence: A New Metric and Curation Strategy to Unlock LLM Diverse Thinking
Oct 30, 2025While Test-Time Scaling (TTS) has proven effective in improving the reasoning ability of large language models (LLMs), low diversity in model outputs often becomes a bottleneck; this is partly caused by the common "one problem, one solution" (1P1S) training practice, which provides a single canonical answer and can push models toward a narrow set of reasoning paths. To address this, we propose a "one problem, multiple solutions" (1PNS) training paradigm that exposes the model to a variety of valid reasoning trajectories and thus increases inference diversity. A core challenge for 1PNS is reliably measuring semantic differences between multi-step chains of thought, so we introduce Reasoning Path Divergence (RPD), a step-level metric that aligns and scores Long Chain-of-Thought solutions to capture differences in intermediate reasoning. Using RPD, we curate maximally diverse solution sets per problem and fine-tune Qwen3-4B-Base. Experiments show that RPD-selected training yields more varied outputs and higher pass@k, with an average +2.80% gain in pass@16 over a strong 1P1S baseline and a +4.99% gain on AIME24, demonstrating that 1PNS further amplifies the effectiveness of TTS. Our code is available at https://github.com/fengjujf/Reasoning-Path-Divergence .
A1: Asynchronous Test-Time Scaling via Conformal Prediction
Sep 18, 2025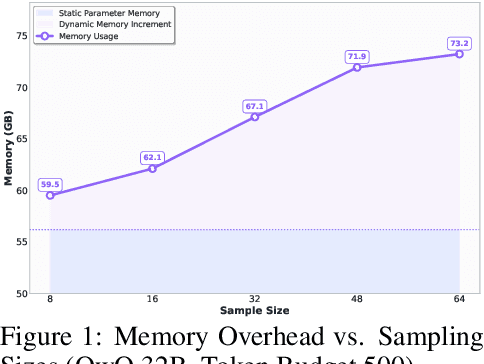
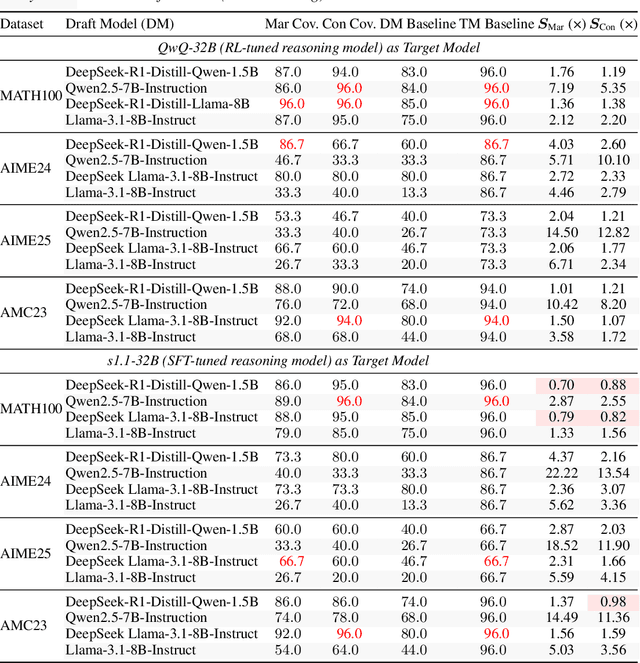
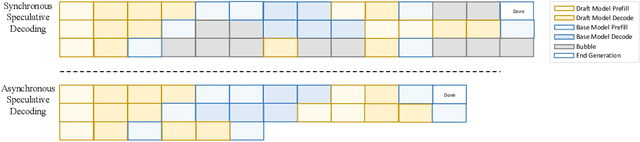
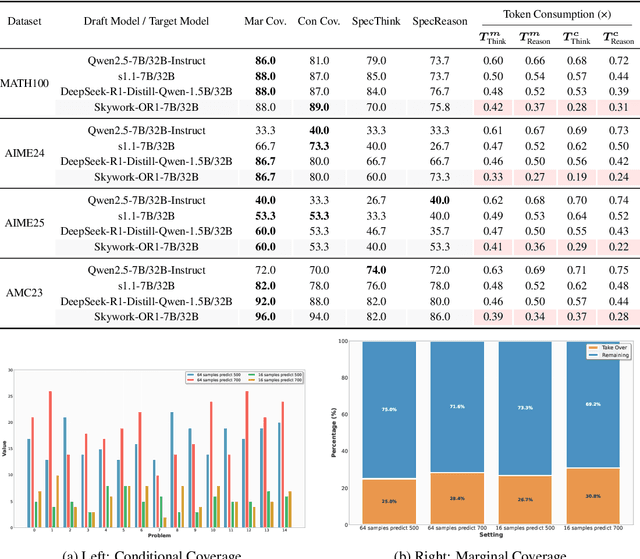
Large language models (LLMs) benefit from test-time scaling, but existing methods face significant challenges, including severe synchronization overhead, memory bottlenecks, and latency, especially during speculative decoding with long reasoning chains. We introduce A1 (Asynchronous Test-Time Scaling), a statistically guaranteed adaptive inference framework that addresses these challenges. A1 refines arithmetic intensity to identify synchronization as the dominant bottleneck, proposes an online calibration strategy to enable asynchronous inference, and designs a three-stage rejection sampling pipeline that supports both sequential and parallel scaling. Through experiments on the MATH, AMC23, AIME24, and AIME25 datasets, across various draft-target model families, we demonstrate that A1 achieves a remarkable 56.7x speedup in test-time scaling and a 4.14x improvement in throughput, all while maintaining accurate rejection-rate control, reducing latency and memory overhead, and no accuracy loss compared to using target model scaling alone. These results position A1 as an efficient and principled solution for scalable LLM inference. We have released the code at https://github.com/menik1126/asynchronous-test-time-scaling.
LongEmotion: Measuring Emotional Intelligence of Large Language Models in Long-Context Interaction
Sep 09, 2025



Large language models (LLMs) make significant progress in Emotional Intelligence (EI) and long-context understanding. However, existing benchmarks tend to overlook certain aspects of EI in long-context scenarios, especially under realistic, practical settings where interactions are lengthy, diverse, and often noisy. To move towards such realistic settings, we present LongEmotion, a benchmark specifically designed for long-context EI tasks. It covers a diverse set of tasks, including Emotion Classification, Emotion Detection, Emotion QA, Emotion Conversation, Emotion Summary, and Emotion Expression. On average, the input length for these tasks reaches 8,777 tokens, with long-form generation required for Emotion Expression. To enhance performance under realistic constraints, we incorporate Retrieval-Augmented Generation (RAG) and Collaborative Emotional Modeling (CoEM), and compare them with standard prompt-based methods. Unlike conventional approaches, our RAG method leverages both the conversation context and the large language model itself as retrieval sources, avoiding reliance on external knowledge bases. The CoEM method further improves performance by decomposing the task into five stages, integrating both retrieval augmentation and limited knowledge injection. Experimental results show that both RAG and CoEM consistently enhance EI-related performance across most long-context tasks, advancing LLMs toward more practical and real-world EI applications. Furthermore, we conducted a comparative case study experiment on the GPT series to demonstrate the differences among various models in terms of EI. Code is available on GitHub at https://github.com/LongEmotion/LongEmotion, and the project page can be found at https://longemotion.github.io/.
DiffuCoder: Understanding and Improving Masked Diffusion Models for Code Generation
Jun 26, 2025Diffusion large language models (dLLMs) are compelling alternatives to autoregressive (AR) models because their denoising models operate over the entire sequence. The global planning and iterative refinement features of dLLMs are particularly useful for code generation. However, current training and inference mechanisms for dLLMs in coding are still under-explored. To demystify the decoding behavior of dLLMs and unlock their potential for coding, we systematically investigate their denoising processes and reinforcement learning (RL) methods. We train a 7B dLLM, \textbf{DiffuCoder}, on 130B tokens of code. Using this model as a testbed, we analyze its decoding behavior, revealing how it differs from that of AR models: (1) dLLMs can decide how causal their generation should be without relying on semi-AR decoding, and (2) increasing the sampling temperature diversifies not only token choices but also their generation order. This diversity creates a rich search space for RL rollouts. For RL training, to reduce the variance of token log-likelihood estimates and maintain training efficiency, we propose \textbf{coupled-GRPO}, a novel sampling scheme that constructs complementary mask noise for completions used in training. In our experiments, coupled-GRPO significantly improves DiffuCoder's performance on code generation benchmarks (+4.4\% on EvalPlus) and reduces reliance on AR bias during decoding. Our work provides deeper insight into the machinery of dLLM generation and offers an effective, diffusion-native RL training framework. https://github.com/apple/ml-diffucoder.
SwingArena: Competitive Programming Arena for Long-context GitHub Issue Solving
May 29, 2025



We present SwingArena, a competitive evaluation framework for Large Language Models (LLMs) that closely mirrors real-world software development workflows. Unlike traditional static benchmarks, SwingArena models the collaborative process of software iteration by pairing LLMs as submitters, who generate patches, and reviewers, who create test cases and verify the patches through continuous integration (CI) pipelines. To support these interactive evaluations, we introduce a retrieval-augmented code generation (RACG) module that efficiently handles long-context challenges by providing syntactically and semantically relevant code snippets from large codebases, supporting multiple programming languages (C++, Python, Rust, and Go). This enables the framework to scale across diverse tasks and contexts while respecting token limitations. Our experiments, using over 400 high-quality real-world GitHub issues selected from a pool of 2,300 issues, show that models like GPT-4o excel at aggressive patch generation, whereas DeepSeek and Gemini prioritize correctness in CI validation. SwingArena presents a scalable and extensible methodology for evaluating LLMs in realistic, CI-driven software development settings. More details are available on our project page: swing-bench.github.io
Scaling Reasoning without Attention
May 28, 2025Large language models (LLMs) have made significant advances in complex reasoning tasks, yet they remain bottlenecked by two core challenges: architectural inefficiency due to reliance on Transformers, and a lack of structured fine-tuning for high-difficulty domains. We introduce \ourmodel, an attention-free language model that addresses both issues through architectural and data-centric innovations. Built on the state space dual (SSD) layers of Mamba-2, our model eliminates the need for self-attention and key-value caching, enabling fixed-memory, constant-time inference. To train it for complex reasoning, we propose a two-phase curriculum fine-tuning strategy based on the \textsc{PromptCoT} synthesis paradigm, which generates pedagogically structured problems via abstract concept selection and rationale-guided generation. On benchmark evaluations, \ourmodel-7B outperforms strong Transformer and hybrid models of comparable scale, and even surpasses the much larger Gemma3-27B by 2.6\% on AIME 24, 0.6\% on AIME 25, and 3.0\% on Livecodebench. These results highlight the potential of state space models as efficient and scalable alternatives to attention-based architectures for high-capacity reasoning.
ScienceBoard: Evaluating Multimodal Autonomous Agents in Realistic Scientific Workflows
May 26, 2025



Large Language Models (LLMs) have extended their impact beyond Natural Language Processing, substantially fostering the development of interdisciplinary research. Recently, various LLM-based agents have been developed to assist scientific discovery progress across multiple aspects and domains. Among these, computer-using agents, capable of interacting with operating systems as humans do, are paving the way to automated scientific problem-solving and addressing routines in researchers' workflows. Recognizing the transformative potential of these agents, we introduce ScienceBoard, which encompasses two complementary contributions: (i) a realistic, multi-domain environment featuring dynamic and visually rich scientific workflows with integrated professional software, where agents can autonomously interact via different interfaces to accelerate complex research tasks and experiments; and (ii) a challenging benchmark of 169 high-quality, rigorously validated real-world tasks curated by humans, spanning scientific-discovery workflows in domains such as biochemistry, astronomy, and geoinformatics. Extensive evaluations of agents with state-of-the-art backbones (e.g., GPT-4o, Claude 3.7, UI-TARS) show that, despite some promising results, they still fall short of reliably assisting scientists in complex workflows, achieving only a 15% overall success rate. In-depth analysis further provides valuable insights for addressing current agent limitations and more effective design principles, paving the way to build more capable agents for scientific discovery. Our code, environment, and benchmark are at https://qiushisun.github.io/ScienceBoard-Home/.
TimeChat-Online: 80% Visual Tokens are Naturally Redundant in Streaming Videos
Apr 24, 2025The rapid growth of online video platforms, particularly live streaming services, has created an urgent need for real-time video understanding systems. These systems must process continuous video streams and respond to user queries instantaneously, presenting unique challenges for current Video Large Language Models (VideoLLMs). While existing VideoLLMs excel at processing complete videos, they face significant limitations in streaming scenarios due to their inability to handle dense, redundant frames efficiently. We introduce TimeChat-Online, a novel online VideoLLM that revolutionizes real-time video interaction. At its core lies our innovative Differential Token Drop (DTD) module, which addresses the fundamental challenge of visual redundancy in streaming videos. Drawing inspiration from human visual perception's Change Blindness phenomenon, DTD preserves meaningful temporal changes while filtering out static, redundant content between frames. Remarkably, our experiments demonstrate that DTD achieves an 82.8% reduction in video tokens while maintaining 98% performance on StreamingBench, revealing that over 80% of visual content in streaming videos is naturally redundant without requiring language guidance. To enable seamless real-time interaction, we present TimeChat-Online-139K, a comprehensive streaming video dataset featuring diverse interaction patterns including backward-tracing, current-perception, and future-responding scenarios. TimeChat-Online's unique Proactive Response capability, naturally achieved through continuous monitoring of video scene transitions via DTD, sets it apart from conventional approaches. Our extensive evaluation demonstrates TimeChat-Online's superior performance on streaming benchmarks (StreamingBench and OvOBench) and maintaining competitive results on long-form video tasks such as Video-MME and MLVU.
TreeSynth: Synthesizing Diverse Data from Scratch via Tree-Guided Subspace Partitioning
Mar 21, 2025



Model customization requires high-quality and diverse datasets, but acquiring such data remains challenging and costly. Although large language models (LLMs) can synthesize training data, current approaches are constrained by limited seed data, model bias and insufficient control over the generation process, resulting in limited diversity and biased distribution with the increase of data scales. To tackle this challenge, we present TreeSynth, a tree-guided subspace-based data synthesis framework that recursively partitions the entire data space into hierar-chical subspaces, enabling comprehensive and diverse scaling of data synthesis. Briefly, given a task-specific description, we construct a data space partitioning tree by iteratively executing criteria determination and subspace coverage steps. This hierarchically divides the whole space (i.e., root node) into mutually exclusive and complementary atomic subspaces (i.e., leaf nodes). By collecting synthesized data according to the attributes of each leaf node, we obtain a diverse dataset that fully covers the data space. Empirically, our extensive experiments demonstrate that TreeSynth surpasses both human-designed datasets and the state-of-the-art data synthesis baselines, achieving maximum improvements of 45.2% in data diversity and 17.6% in downstream task performance across various models and tasks. Hopefully, TreeSynth provides a scalable solution to synthesize diverse and comprehensive datasets from scratch without human intervention.
Developing and Utilizing a Large-Scale Cantonese Dataset for Multi-Tasking in Large Language Models
Mar 05, 2025



High-quality data resources play a crucial role in learning large language models (LLMs), particularly for low-resource languages like Cantonese. Despite having more than 85 million native speakers, Cantonese is still considered a low-resource language in the field of natural language processing (NLP) due to factors such as the dominance of Mandarin, lack of cohesion within the Cantonese-speaking community, diversity in character encoding and input methods, and the tendency of overseas Cantonese speakers to prefer using English. In addition, rich colloquial vocabulary of Cantonese, English loanwords, and code-switching characteristics add to the complexity of corpus collection and processing. To address these challenges, we collect Cantonese texts from a variety of sources, including open source corpora, Hong Kong-specific forums, Wikipedia, and Common Crawl data. We conduct rigorous data processing through language filtering, quality filtering, content filtering, and de-duplication steps, successfully constructing a high-quality Cantonese corpus of over 2 billion tokens for training large language models. We further refined the model through supervised fine-tuning (SFT) on curated Cantonese tasks, enhancing its ability to handle specific applications. Upon completion of the training, the model achieves state-of-the-art (SOTA) performance on four Cantonese benchmarks. After training on our dataset, the model also exhibits improved performance on other mainstream language tasks.