 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAION: Aerial Indoor Object-Goal Navigation Using Dual-Policy Reinforcement Learning
Jan 22, 2026Object-Goal Navigation (ObjectNav) requires an agent to autonomously explore an unknown environment and navigate toward target objects specified by a semantic label. While prior work has primarily studied zero-shot ObjectNav under 2D locomotion, extending it to aerial platforms with 3D locomotion capability remains underexplored. Aerial robots offer superior maneuverability and search efficiency, but they also introduce new challenges in spatial perception, dynamic control, and safety assurance. In this paper, we propose AION for vision-based aerial ObjectNav without relying on external localization or global maps. AION is an end-to-end dual-policy reinforcement learning (RL) framework that decouples exploration and goal-reaching behaviors into two specialized policies. We evaluate AION on the AI2-THOR benchmark and further assess its real-time performance in IsaacSim using high-fidelity drone models. Experimental results show that AION achieves superior performance across comprehensive evaluation metrics in exploration, navigation efficiency, and safety. The video can be found at https://youtu.be/TgsUm6bb7zg.
S2DiT: Sandwich Diffusion Transformer for Mobile Streaming Video Generation
Jan 19, 2026Diffusion Transformers (DiTs) have recently improved video generation quality. However, their heavy computational cost makes real-time or on-device generation infeasible. In this work, we introduce S2DiT, a Streaming Sandwich Diffusion Transformer designed for efficient, high-fidelity, and streaming video generation on mobile hardware. S2DiT generates more tokens but maintains efficiency with novel efficient attentions: a mixture of LinConv Hybrid Attention (LCHA) and Stride Self-Attention (SSA). Based on this, we uncover the sandwich design via a budget-aware dynamic programming search, achieving superior quality and efficiency. We further propose a 2-in-1 distillation framework that transfers the capacity of large teacher models (e.g., Wan 2.2-14B) to the compact few-step sandwich model. Together, S2DiT achieves quality on par with state-of-the-art server video models, while streaming at over 10 FPS on an iPhone.
Data Fusion-Enhanced Decision Transformer for Stable Cross-Domain Generalization
Nov 12, 2025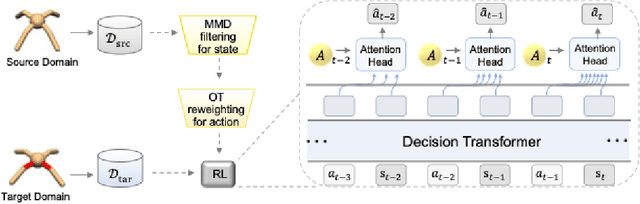


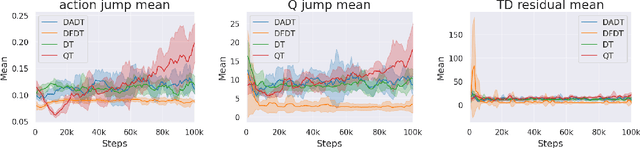
Cross-domain shifts present a significant challenge for decision transformer (DT) policies. Existing cross-domain policy adaptation methods typically rely on a single simple filtering criterion to select source trajectory fragments and stitch them together. They match either state structure or action feasibility. However, the selected fragments still have poor stitchability: state structures can misalign, the return-to-go (RTG) becomes incomparable when the reward or horizon changes, and actions may jump at trajectory junctions. As a result, RTG tokens lose continuity, which compromises DT's inference ability. To tackle these challenges, we propose Data Fusion-Enhanced Decision Transformer (DFDT), a compact pipeline that restores stitchability. Particularly, DFDT fuses scarce target data with selectively trusted source fragments via a two-level data filter, maximum mean discrepancy (MMD) mismatch for state-structure alignment, and optimal transport (OT) deviation for action feasibility. It then trains on a feasibility-weighted fusion distribution. Furthermore, DFDT replaces RTG tokens with advantage-conditioned tokens, which improves the continuity of the semantics in the token sequence. It also applies a $Q$-guided regularizer to suppress junction value and action jumps. Theoretically, we provide bounds that tie state value and policy performance gaps to the MMD-mismatch and OT-deviation measures, and show that the bounds tighten as these two measures shrink. We show that DFDT improves return and stability over strong offline RL and sequence-model baselines across gravity, kinematic, and morphology shifts on D4RL-style control tasks, and further corroborate these gains with token-stitching and sequence-semantics stability analyses.
MacroNav: Multi-Task Context Representation Learning Enables Efficient Navigation in Unknown Environments
Nov 06, 2025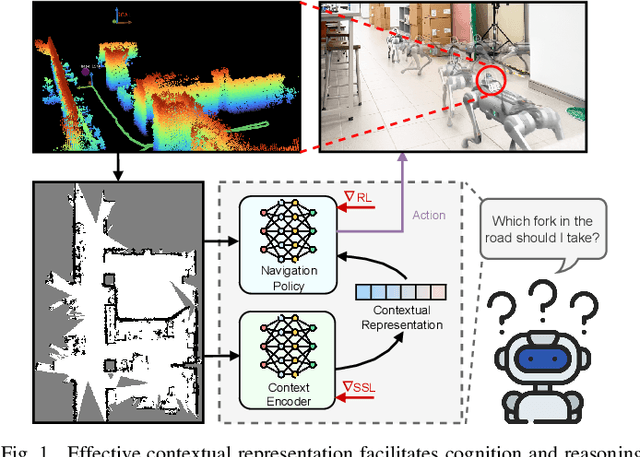
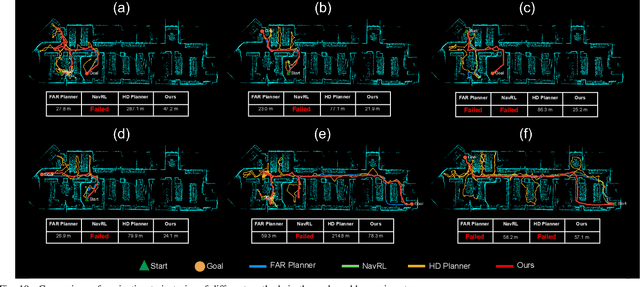
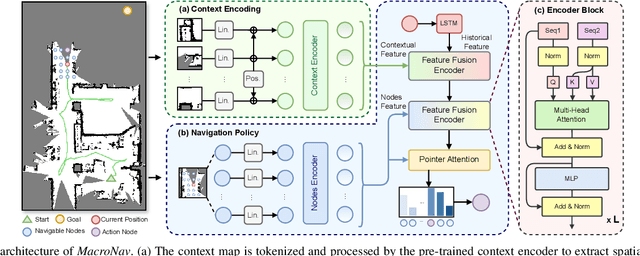
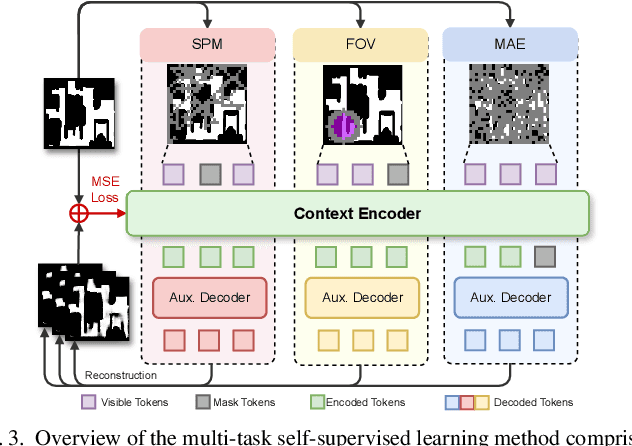
Autonomous navigation in unknown environments requires compact yet expressive spatial understanding under partial observability to support high-level decision making. Existing approaches struggle to balance rich contextual representation with navigation efficiency. We present MacroNav, a learning-based navigation framework featuring two key components: (1) a lightweight context encoder trained via multi-task self-supervised learning to capture multi-scale, navigation-centric spatial representations; and (2) a reinforcement learning policy that seamlessly integrates these representations with graph-based reasoning for efficient action selection. Extensive experiments demonstrate the context encoder's efficient and robust environmental understanding. Real-world deployments further validate MacroNav's effectiveness, yielding significant gains over state-of-the-art navigation methods in both Success Rate (SR) and Success weighted by Path Length (SPL), while maintaining low computational cost. Code will be released upon acceptance.
RAU: Reference-based Anatomical Understanding with Vision Language Models
Sep 26, 2025Anatomical understanding through deep learning is critical for automatic report generation, intra-operative navigation, and organ localization in medical imaging; however, its progress is constrained by the scarcity of expert-labeled data. A promising remedy is to leverage an annotated reference image to guide the interpretation of an unlabeled target. Although recent vision-language models (VLMs) exhibit non-trivial visual reasoning, their reference-based understanding and fine-grained localization remain limited. We introduce RAU, a framework for reference-based anatomical understanding with VLMs. We first show that a VLM learns to identify anatomical regions through relative spatial reasoning between reference and target images, trained on a moderately sized dataset. We validate this capability through visual question answering (VQA) and bounding box prediction. Next, we demonstrate that the VLM-derived spatial cues can be seamlessly integrated with the fine-grained segmentation capability of SAM2, enabling localization and pixel-level segmentation of small anatomical regions, such as vessel segments. Across two in-distribution and two out-of-distribution datasets, RAU consistently outperforms a SAM2 fine-tuning baseline using the same memory setup, yielding more accurate segmentations and more reliable localization. More importantly, its strong generalization ability makes it scalable to out-of-distribution datasets, a property crucial for medical image applications. To the best of our knowledge, RAU is the first to explore the capability of VLMs for reference-based identification, localization, and segmentation of anatomical structures in medical images. Its promising performance highlights the potential of VLM-driven approaches for anatomical understanding in automated clinical workflows.
TransforMARS: Fault-Tolerant Self-Reconfiguration for Arbitrarily Shaped Modular Aerial Robot Systems
Sep 17, 2025Modular Aerial Robot Systems (MARS) consist of multiple drone modules that are physically bound together to form a single structure for flight. Exploiting structural redundancy, MARS can be reconfigured into different formations to mitigate unit or rotor failures and maintain stable flight. Prior work on MARS self-reconfiguration has solely focused on maximizing controllability margins to tolerate a single rotor or unit fault for rectangular-shaped MARS. We propose TransforMARS, a general fault-tolerant reconfiguration framework that transforms arbitrarily shaped MARS under multiple rotor and unit faults while ensuring continuous in-air stability. Specifically, we develop algorithms to first identify and construct minimum controllable assemblies containing faulty units. We then plan feasible disassembly-assembly sequences to transport MARS units or subassemblies to form target configuration. Our approach enables more flexible and practical feasible reconfiguration. We validate TransforMARS in challenging arbitrarily shaped MARS configurations, demonstrating substantial improvements over prior works in both the capacity of handling diverse configurations and the number of faults tolerated. The videos and source code of this work are available at the anonymous repository: https://anonymous.4open.science/r/TransforMARS-1030/
Learning Agile Gate Traversal via Analytical Optimal Policy Gradient
Aug 29, 2025Traversing narrow gates presents a significant challenge and has become a standard benchmark for evaluating agile and precise quadrotor flight. Traditional modularized autonomous flight stacks require extensive design and parameter tuning, while end-to-end reinforcement learning (RL) methods often suffer from low sample efficiency and limited interpretability. In this work, we present a novel hybrid framework that adaptively fine-tunes model predictive control (MPC) parameters online using outputs from a neural network (NN) trained offline. The NN jointly predicts a reference pose and cost-function weights, conditioned on the coordinates of the gate corners and the current drone state. To achieve efficient training, we derive analytical policy gradients not only for the MPC module but also for an optimization-based gate traversal detection module. Furthermore, we introduce a new formulation of the attitude tracking error that admits a simplified representation, facilitating effective learning with bounded gradients. Hardware experiments demonstrate that our method enables fast and accurate quadrotor traversal through narrow gates in confined environments. It achieves several orders of magnitude improvement in sample efficiency compared to naive end-to-end RL approaches.
SIGN: Safety-Aware Image-Goal Navigation for Autonomous Drones via Reinforcement Learning
Aug 17, 2025Image-goal navigation (ImageNav) tasks a robot with autonomously exploring an unknown environment and reaching a location that visually matches a given target image. While prior works primarily study ImageNav for ground robots, enabling this capability for autonomous drones is substantially more challenging due to their need for high-frequency feedback control and global localization for stable flight. In this paper, we propose a novel sim-to-real framework that leverages visual reinforcement learning (RL) to achieve ImageNav for drones. To enhance visual representation ability, our approach trains the vision backbone with auxiliary tasks, including image perturbations and future transition prediction, which results in more effective policy training. The proposed algorithm enables end-to-end ImageNav with direct velocity control, eliminating the need for external localization. Furthermore, we integrate a depth-based safety module for real-time obstacle avoidance, allowing the drone to safely navigate in cluttered environments. Unlike most existing drone navigation methods that focus solely on reference tracking or obstacle avoidance, our framework supports comprehensive navigation behaviors--autonomous exploration, obstacle avoidance, and image-goal seeking--without requiring explicit global mapping. Code and model checkpoints will be released upon acceptance.
FED-PsyAU: Privacy-Preserving Micro-Expression Recognition via Psychological AU Coordination and Dynamic Facial Motion Modeling
Jul 28, 2025



Micro-expressions (MEs) are brief, low-intensity, often localized facial expressions. They could reveal genuine emotions individuals may attempt to conceal, valuable in contexts like criminal interrogation and psychological counseling. However, ME recognition (MER) faces challenges, such as small sample sizes and subtle features, which hinder efficient modeling. Additionally, real-world applications encounter ME data privacy issues, leaving the task of enhancing recognition across settings under privacy constraints largely unexplored. To address these issues, we propose a FED-PsyAU research framework. We begin with a psychological study on the coordination of upper and lower facial action units (AUs) to provide structured prior knowledge of facial muscle dynamics. We then develop a DPK-GAT network that combines these psychological priors with statistical AU patterns, enabling hierarchical learning of facial motion features from regional to global levels, effectively enhancing MER performance. Additionally, our federated learning framework advances MER capabilities across multiple clients without data sharing, preserving privacy and alleviating the limited-sample issue for each client. Extensive experiments on commonly-used ME databases demonstrate the effectiveness of our approach.
CheXPO: Preference Optimization for Chest X-ray VLMs with Counterfactual Rationale
Jul 09, 2025Vision-language models (VLMs) are prone to hallucinations that critically compromise reliability in medical applications. While preference optimization can mitigate these hallucinations through clinical feedback, its implementation faces challenges such as clinically irrelevant training samples, imbalanced data distributions, and prohibitive expert annotation costs. To address these challenges, we introduce CheXPO, a Chest X-ray Preference Optimization strategy that combines confidence-similarity joint mining with counterfactual rationale. Our approach begins by synthesizing a unified, fine-grained multi-task chest X-ray visual instruction dataset across different question types for supervised fine-tuning (SFT). We then identify hard examples through token-level confidence analysis of SFT failures and use similarity-based retrieval to expand hard examples for balancing preference sample distributions, while synthetic counterfactual rationales provide fine-grained clinical preferences, eliminating the need for additional expert input. Experiments show that CheXPO achieves 8.93% relative performance gain using only 5% of SFT samples, reaching state-of-the-art performance across diverse clinical tasks and providing a scalable, interpretable solution for real-world radiology applications.