 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoboTron-Sim: Improving Real-World Driving via Simulated Hard-Case
Aug 06, 2025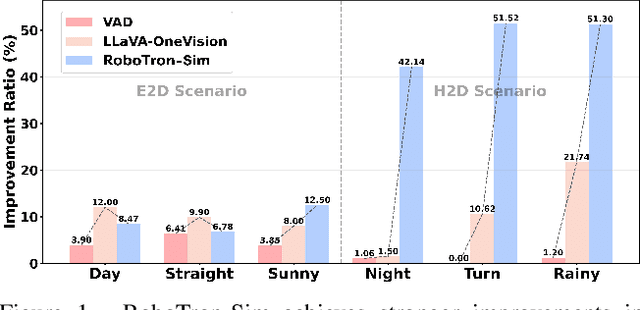



Collecting real-world data for rare high-risk scenarios, long-tailed driving events, and complex interactions remains challenging, leading to poor performance of existing autonomous driving systems in these critical situations. In this paper, we propose RoboTron-Sim that improves real-world driving in critical situations by utilizing simulated hard cases. First, we develop a simulated dataset called Hard-case Augmented Synthetic Scenarios (HASS), which covers 13 high-risk edge-case categories, as well as balanced environmental conditions such as day/night and sunny/rainy. Second, we introduce Scenario-aware Prompt Engineering (SPE) and an Image-to-Ego Encoder (I2E Encoder) to enable multimodal large language models to effectively learn real-world challenging driving skills from HASS, via adapting to environmental deviations and hardware differences between real-world and simulated scenarios. Extensive experiments on nuScenes show that RoboTron-Sim improves driving performance in challenging scenarios by around 50%, achieving state-of-the-art results in real-world open-loop planning. Qualitative results further demonstrate the effectiveness of RoboTron-Sim in better managing rare high-risk driving scenarios. Project page: https://stars79689.github.io/RoboTron-Sim/
DocTron-Formula: Generalized Formula Recognition in Complex and Structured Scenarios
Aug 01, 2025

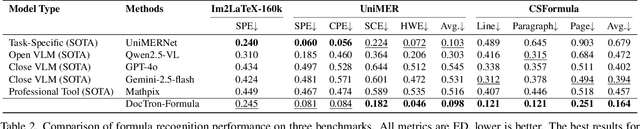
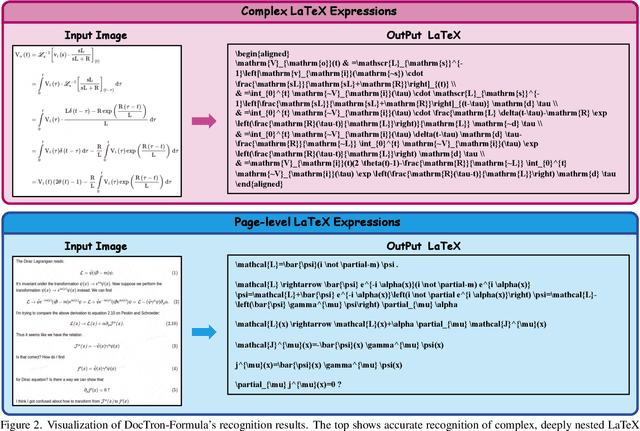
Optical Character Recognition (OCR) for mathematical formula is essential for the intelligent analysis of scientific literature. However, both task-specific and general vision-language models often struggle to handle the structural diversity, complexity, and real-world variability inherent in mathematical content. In this work, we present DocTron-Formula, a unified framework built upon general vision-language models, thereby eliminating the need for specialized architectures. Furthermore, we introduce CSFormula, a large-scale and challenging dataset that encompasses multidisciplinary and structurally complex formulas at the line, paragraph, and page levels. Through straightforward supervised fine-tuning, our approach achieves state-of-the-art performance across a variety of styles, scientific domains, and complex layouts. Experimental results demonstrate that our method not only surpasses specialized models in terms of accuracy and robustness, but also establishes a new paradigm for the automated understanding of complex scientific documents.
Orthogonal Projection Subspace to Aggregate Online Prior-knowledge for Continual Test-time Adaptation
Jun 23, 2025


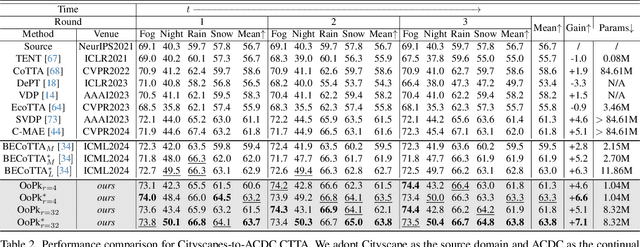
Continual Test Time Adaptation (CTTA) is a task that requires a source pre-trained model to continually adapt to new scenarios with changing target distributions. Existing CTTA methods primarily focus on mitigating the challenges of catastrophic forgetting and error accumulation. Though there have been emerging methods based on forgetting adaptation with parameter-efficient fine-tuning, they still struggle to balance competitive performance and efficient model adaptation, particularly in complex tasks like semantic segmentation. In this paper, to tackle the above issues, we propose a novel pipeline, Orthogonal Projection Subspace to aggregate online Prior-knowledge, dubbed OoPk. Specifically, we first project a tuning subspace orthogonally which allows the model to adapt to new domains while preserving the knowledge integrity of the pre-trained source model to alleviate catastrophic forgetting. Then, we elaborate an online prior-knowledge aggregation strategy that employs an aggressive yet efficient image masking strategy to mimic potential target dynamism, enhancing the student model's domain adaptability. This further gradually ameliorates the teacher model's knowledge, ensuring high-quality pseudo labels and reducing error accumulation. We demonstrate our method with extensive experiments that surpass previous CTTA methods and achieve competitive performances across various continual TTA benchmarks in semantic segmentation tasks.
ImmerseGen: Agent-Guided Immersive World Generation with Alpha-Textured Proxies
Jun 18, 2025Automatic creation of 3D scenes for immersive VR presence has been a significant research focus for decades. However, existing methods often rely on either high-poly mesh modeling with post-hoc simplification or massive 3D Gaussians, resulting in a complex pipeline or limited visual realism. In this paper, we demonstrate that such exhaustive modeling is unnecessary for achieving compelling immersive experience. We introduce ImmerseGen, a novel agent-guided framework for compact and photorealistic world modeling. ImmerseGen represents scenes as hierarchical compositions of lightweight geometric proxies, i.e., simplified terrain and billboard meshes, and generates photorealistic appearance by synthesizing RGBA textures onto these proxies. Specifically, we propose terrain-conditioned texturing for user-centric base world synthesis, and RGBA asset texturing for midground and foreground scenery. This reformulation offers several advantages: (i) it simplifies modeling by enabling agents to guide generative models in producing coherent textures that integrate seamlessly with the scene; (ii) it bypasses complex geometry creation and decimation by directly synthesizing photorealistic textures on proxies, preserving visual quality without degradation; (iii) it enables compact representations suitable for real-time rendering on mobile VR headsets. To automate scene creation from text prompts, we introduce VLM-based modeling agents enhanced with semantic grid-based analysis for improved spatial reasoning and accurate asset placement. ImmerseGen further enriches scenes with dynamic effects and ambient audio to support multisensory immersion. Experiments on scene generation and live VR showcases demonstrate that ImmerseGen achieves superior photorealism, spatial coherence and rendering efficiency compared to prior methods. Project webpage: https://immersegen.github.io.
Metis-RISE: RL Incentivizes and SFT Enhances Multimodal Reasoning Model Learning
Jun 16, 2025Recent advancements in large language models (LLMs) have witnessed a surge in the development of advanced reasoning paradigms, which are now being integrated into multimodal large language models (MLLMs). However, existing approaches often fall short: methods solely employing reinforcement learning (RL) can struggle with sample inefficiency and activating entirely absent reasoning capabilities, while conventional pipelines that initiate with a cold-start supervised fine-tuning (SFT) phase before RL may restrict the model's exploratory capacity and face suboptimal convergence. In this work, we introduce \textbf{Metis-RISE} (\textbf{R}L \textbf{I}ncentivizes and \textbf{S}FT \textbf{E}nhances) for multimodal reasoning model learning. Unlike conventional approaches, Metis-RISE distinctively omits an initial SFT stage, beginning instead with an RL phase (e.g., using a Group Relative Policy Optimization variant) to incentivize and activate the model's latent reasoning capacity. Subsequently, the targeted SFT stage addresses two key challenges identified during RL: (1) \textit{inefficient trajectory sampling} for tasks where the model possesses but inconsistently applies correct reasoning, which we tackle using self-distilled reasoning trajectories from the RL model itself; and (2) \textit{fundamental capability absence}, which we address by injecting expert-augmented knowledge for prompts where the model entirely fails. This strategic application of RL for incentivization followed by SFT for enhancement forms the core of Metis-RISE, leading to two versions of our MLLMs (7B and 72B parameters). Evaluations on the OpenCompass Multimodal Reasoning Leaderboard demonstrate that both models achieve state-of-the-art performance among similar-sized models, with the 72B version ranking fourth overall.
M4V: Multi-Modal Mamba for Text-to-Video Generation
Jun 12, 2025Text-to-video generation has significantly enriched content creation and holds the potential to evolve into powerful world simulators. However, modeling the vast spatiotemporal space remains computationally demanding, particularly when employing Transformers, which incur quadratic complexity in sequence processing and thus limit practical applications. Recent advancements in linear-time sequence modeling, particularly the Mamba architecture, offer a more efficient alternative. Nevertheless, its plain design limits its direct applicability to multi-modal and spatiotemporal video generation tasks. To address these challenges, we introduce M4V, a Multi-Modal Mamba framework for text-to-video generation. Specifically, we propose a multi-modal diffusion Mamba (MM-DiM) block that enables seamless integration of multi-modal information and spatiotemporal modeling through a multi-modal token re-composition design. As a result, the Mamba blocks in M4V reduce FLOPs by 45% compared to the attention-based alternative when generating videos at 768$\times$1280 resolution. Additionally, to mitigate the visual quality degradation in long-context autoregressive generation processes, we introduce a reward learning strategy that further enhances per-frame visual realism. Extensive experiments on text-to-video benchmarks demonstrate M4V's ability to produce high-quality videos while significantly lowering computational costs. Code and models will be publicly available at https://huangjch526.github.io/M4V_project.
DisTime: Distribution-based Time Representation for Video Large Language Models
May 30, 2025



Despite advances in general video understanding, Video Large Language Models (Video-LLMs) face challenges in precise temporal localization due to discrete time representations and limited temporally aware datasets. Existing methods for temporal expression either conflate time with text-based numerical values, add a series of dedicated temporal tokens, or regress time using specialized temporal grounding heads. To address these issues, we introduce DisTime, a lightweight framework designed to enhance temporal comprehension in Video-LLMs. DisTime employs a learnable token to create a continuous temporal embedding space and incorporates a Distribution-based Time Decoder that generates temporal probability distributions, effectively mitigating boundary ambiguities and maintaining temporal continuity. Additionally, the Distribution-based Time Encoder re-encodes timestamps to provide time markers for Video-LLMs. To overcome temporal granularity limitations in existing datasets, we propose an automated annotation paradigm that combines the captioning capabilities of Video-LLMs with the localization expertise of dedicated temporal models. This leads to the creation of InternVid-TG, a substantial dataset with 1.25M temporally grounded events across 179k videos, surpassing ActivityNet-Caption by 55 times. Extensive experiments demonstrate that DisTime achieves state-of-the-art performance across benchmarks in three time-sensitive tasks while maintaining competitive performance in Video QA tasks. Code and data are released at https://github.com/josephzpng/DisTime.
TopoDiT-3D: Topology-Aware Diffusion Transformer with Bottleneck Structure for 3D Point Cloud Generation
May 14, 2025Recent advancements in Diffusion Transformer (DiT) models have significantly improved 3D point cloud generation. However, existing methods primarily focus on local feature extraction while overlooking global topological information, such as voids, which are crucial for maintaining shape consistency and capturing complex geometries. To address this limitation, we propose TopoDiT-3D, a Topology-Aware Diffusion Transformer with a bottleneck structure for 3D point cloud generation. Specifically, we design the bottleneck structure utilizing Perceiver Resampler, which not only offers a mode to integrate topological information extracted through persistent homology into feature learning, but also adaptively filters out redundant local features to improve training efficiency. Experimental results demonstrate that TopoDiT-3D outperforms state-of-the-art models in visual quality, diversity, and training efficiency. Furthermore, TopoDiT-3D demonstrates the importance of rich topological information for 3D point cloud generation and its synergy with conventional local feature learning. Videos and code are available at https://github.com/Zechao-Guan/TopoDiT-3D.
Flash-VL 2B: Optimizing Vision-Language Model Performance for Ultra-Low Latency and High Throughput
May 14, 2025In this paper, we introduce Flash-VL 2B, a novel approach to optimizing Vision-Language Models (VLMs) for real-time applications, targeting ultra-low latency and high throughput without sacrificing accuracy. Leveraging advanced architectural enhancements and efficient computational strategies, Flash-VL 2B is designed to maximize throughput by reducing processing time while maintaining competitive performance across multiple vision-language benchmarks. Our approach includes tailored architectural choices, token compression mechanisms, data curation, training schemes, and a novel image processing technique called implicit semantic stitching that effectively balances computational load and model performance. Through extensive evaluations on 11 standard VLM benchmarks, we demonstrate that Flash-VL 2B achieves state-of-the-art results in both speed and accuracy, making it a promising solution for deployment in resource-constrained environments and large-scale real-time applications.
ScaleTrack: Scaling and back-tracking Automated GUI Agents
May 01, 2025Automated GUI agents aims to facilitate user interaction by automatically performing complex tasks in digital environments, such as web, mobile, desktop devices. It receives textual task instruction and GUI description to generate executable actions (\emph{e.g.}, click) and operation boxes step by step. Training a GUI agent mainly involves grounding and planning stages, in which the GUI grounding focuses on finding the execution coordinates according to the task, while the planning stage aims to predict the next action based on historical actions. However, previous work suffers from the limitations of insufficient training data for GUI grounding, as well as the ignorance of backtracking historical behaviors for GUI planning. To handle the above challenges, we propose ScaleTrack, a training framework by scaling grounding and backtracking planning for automated GUI agents. We carefully collected GUI samples of different synthesis criterions from a wide range of sources, and unified them into the same template for training GUI grounding models. Moreover, we design a novel training strategy that predicts the next action from the current GUI image, while also backtracking the historical actions that led to the GUI image. In this way, ScaleTrack explains the correspondence between GUI images and actions, which effectively describes the evolution rules of the GUI environment. Extensive experimental results demonstrate the effectiveness of ScaleTrack. Data and code will be available at url.