 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTopoDiT-3D: Topology-Aware Diffusion Transformer with Bottleneck Structure for 3D Point Cloud Generation
May 14, 2025



Recent advancements in Diffusion Transformer (DiT) models have significantly improved 3D point cloud generation. However, existing methods primarily focus on local feature extraction while overlooking global topological information, such as voids, which are crucial for maintaining shape consistency and capturing complex geometries. To address this limitation, we propose TopoDiT-3D, a Topology-Aware Diffusion Transformer with a bottleneck structure for 3D point cloud generation. Specifically, we design the bottleneck structure utilizing Perceiver Resampler, which not only offers a mode to integrate topological information extracted through persistent homology into feature learning, but also adaptively filters out redundant local features to improve training efficiency. Experimental results demonstrate that TopoDiT-3D outperforms state-of-the-art models in visual quality, diversity, and training efficiency. Furthermore, TopoDiT-3D demonstrates the importance of rich topological information for 3D point cloud generation and its synergy with conventional local feature learning. Videos and code are available at https://github.com/Zechao-Guan/TopoDiT-3D.
Recovering 3D Planar Arrangements from Videos
Jan 25, 2017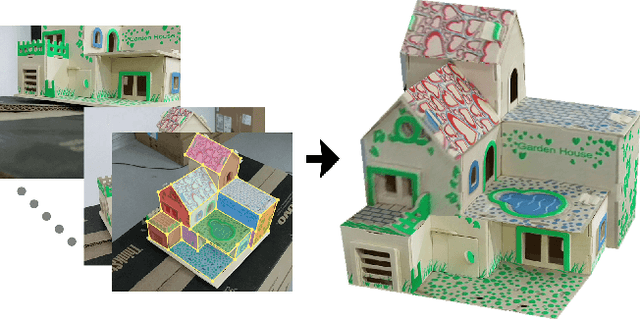
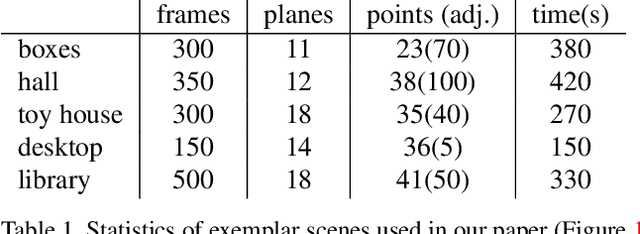


Acquiring 3D geometry of real world objects has various applications in 3D digitization, such as navigation and content generation in virtual environments. Image remains one of the most popular media for such visual tasks due to its simplicity of acquisition. Traditional image-based 3D reconstruction approaches heavily exploit point-to-point correspondence among multiple images to estimate camera motion and 3D geometry. Establishing point-to-point correspondence lies at the center of the 3D reconstruction pipeline, which however is easily prone to errors. In this paper, we propose an optimization framework which traces image points using a novel structure-guided dynamic tracking algorithm and estimates both the camera motion and a 3D structure model by enforcing a set of planar constraints. The key to our method is a structure model represented as a set of planes and their arrangements. Constraints derived from the structure model is used both in the correspondence establishment stage and the bundle adjustment stage in our reconstruction pipeline. Experiments show that our algorithm can effectively localize structure correspondence across dense image frames while faithfully reconstructing the camera motion and the underlying structured 3D model.