 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeX-SAM: From Segment Anything to Any Segmentation
Aug 06, 2025Large Language Models (LLMs) demonstrate strong capabilities in broad knowledge representation, yet they are inherently deficient in pixel-level perceptual understanding. Although the Segment Anything Model (SAM) represents a significant advancement in visual-prompt-driven image segmentation, it exhibits notable limitations in multi-mask prediction and category-specific segmentation tasks, and it cannot integrate all segmentation tasks within a unified model architecture. To address these limitations, we present X-SAM, a streamlined Multimodal Large Language Model (MLLM) framework that extends the segmentation paradigm from \textit{segment anything} to \textit{any segmentation}. Specifically, we introduce a novel unified framework that enables more advanced pixel-level perceptual comprehension for MLLMs. Furthermore, we propose a new segmentation task, termed Visual GrounDed (VGD) segmentation, which segments all instance objects with interactive visual prompts and empowers MLLMs with visual grounded, pixel-wise interpretative capabilities. To enable effective training on diverse data sources, we present a unified training strategy that supports co-training across multiple datasets. Experimental results demonstrate that X-SAM achieves state-of-the-art performance on a wide range of image segmentation benchmarks, highlighting its efficiency for multimodal, pixel-level visual understanding. Code is available at https://github.com/wanghao9610/X-SAM.
Orthogonal Projection Subspace to Aggregate Online Prior-knowledge for Continual Test-time Adaptation
Jun 23, 2025


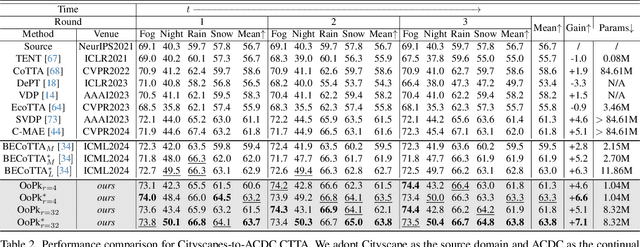
Continual Test Time Adaptation (CTTA) is a task that requires a source pre-trained model to continually adapt to new scenarios with changing target distributions. Existing CTTA methods primarily focus on mitigating the challenges of catastrophic forgetting and error accumulation. Though there have been emerging methods based on forgetting adaptation with parameter-efficient fine-tuning, they still struggle to balance competitive performance and efficient model adaptation, particularly in complex tasks like semantic segmentation. In this paper, to tackle the above issues, we propose a novel pipeline, Orthogonal Projection Subspace to aggregate online Prior-knowledge, dubbed OoPk. Specifically, we first project a tuning subspace orthogonally which allows the model to adapt to new domains while preserving the knowledge integrity of the pre-trained source model to alleviate catastrophic forgetting. Then, we elaborate an online prior-knowledge aggregation strategy that employs an aggressive yet efficient image masking strategy to mimic potential target dynamism, enhancing the student model's domain adaptability. This further gradually ameliorates the teacher model's knowledge, ensuring high-quality pseudo labels and reducing error accumulation. We demonstrate our method with extensive experiments that surpass previous CTTA methods and achieve competitive performances across various continual TTA benchmarks in semantic segmentation tasks.
M4V: Multi-Modal Mamba for Text-to-Video Generation
Jun 12, 2025Text-to-video generation has significantly enriched content creation and holds the potential to evolve into powerful world simulators. However, modeling the vast spatiotemporal space remains computationally demanding, particularly when employing Transformers, which incur quadratic complexity in sequence processing and thus limit practical applications. Recent advancements in linear-time sequence modeling, particularly the Mamba architecture, offer a more efficient alternative. Nevertheless, its plain design limits its direct applicability to multi-modal and spatiotemporal video generation tasks. To address these challenges, we introduce M4V, a Multi-Modal Mamba framework for text-to-video generation. Specifically, we propose a multi-modal diffusion Mamba (MM-DiM) block that enables seamless integration of multi-modal information and spatiotemporal modeling through a multi-modal token re-composition design. As a result, the Mamba blocks in M4V reduce FLOPs by 45% compared to the attention-based alternative when generating videos at 768$\times$1280 resolution. Additionally, to mitigate the visual quality degradation in long-context autoregressive generation processes, we introduce a reward learning strategy that further enhances per-frame visual realism. Extensive experiments on text-to-video benchmarks demonstrate M4V's ability to produce high-quality videos while significantly lowering computational costs. Code and models will be publicly available at https://huangjch526.github.io/M4V_project.
UniToken: Harmonizing Multimodal Understanding and Generation through Unified Visual Encoding
Apr 06, 2025We introduce UniToken, an auto-regressive generation model that encodes visual inputs through a combination of discrete and continuous representations, enabling seamless integration of unified visual understanding and image generation tasks. Unlike previous approaches that rely on unilateral visual representations, our unified visual encoding framework captures both high-level semantics and low-level details, delivering multidimensional information that empowers heterogeneous tasks to selectively assimilate domain-specific knowledge based on their inherent characteristics. Through in-depth experiments, we uncover key principles for developing a unified model capable of both visual understanding and image generation. Extensive evaluations across a diverse range of prominent benchmarks demonstrate that UniToken achieves state-of-the-art performance, surpassing existing approaches. These results establish UniToken as a robust foundation for future research in this domain. The code and models are available at https://github.com/SxJyJay/UniToken.
FlexVAR: Flexible Visual Autoregressive Modeling without Residual Prediction
Feb 27, 2025This work challenges the residual prediction paradigm in visual autoregressive modeling and presents FlexVAR, a new Flexible Visual AutoRegressive image generation paradigm. FlexVAR facilitates autoregressive learning with ground-truth prediction, enabling each step to independently produce plausible images. This simple, intuitive approach swiftly learns visual distributions and makes the generation process more flexible and adaptable. Trained solely on low-resolution images ($\leq$ 256px), FlexVAR can: (1) Generate images of various resolutions and aspect ratios, even exceeding the resolution of the training images. (2) Support various image-to-image tasks, including image refinement, in/out-painting, and image expansion. (3) Adapt to various autoregressive steps, allowing for faster inference with fewer steps or enhancing image quality with more steps. Our 1.0B model outperforms its VAR counterpart on the ImageNet 256$\times$256 benchmark. Moreover, when zero-shot transfer the image generation process with 13 steps, the performance further improves to 2.08 FID, outperforming state-of-the-art autoregressive models AiM/VAR by 0.25/0.28 FID and popular diffusion models LDM/DiT by 1.52/0.19 FID, respectively. When transferring our 1.0B model to the ImageNet 512$\times$512 benchmark in a zero-shot manner, FlexVAR achieves competitive results compared to the VAR 2.3B model, which is a fully supervised model trained at 512$\times$512 resolution.
Mitigating Hallucination for Large Vision Language Model by Inter-Modality Correlation Calibration Decoding
Jan 03, 2025



Large vision-language models (LVLMs) have shown remarkable capabilities in visual-language understanding for downstream multi-modal tasks. Despite their success, LVLMs still suffer from generating hallucinations in complex generation tasks, leading to inconsistencies between visual inputs and generated content. To address this issue, some approaches have introduced inference-time interventions, such as contrastive decoding and attention rectification, to reduce overreliance on language priors. However, these approaches overlook hallucinations stemming from spurious inter-modality correlations. In this paper, we propose an Inter-Modality Correlation Calibration Decoding (IMCCD) method to mitigate hallucinations in LVLMs in a training-free manner. In this method, we design a Cross-Modal Value-Enhanced Decoding(CMVED) module to alleviate hallucination by a novel contrastive decoding mechanism. During the estimation of distorted distribution, CMVED masks the value vectors associated with significant cross-modal attention weights, which address both uni-modality overreliance and misleading inter-modality correlations. Additionally, a Content-Driven Attention Refinement(CDAR) module refines cross-modal attention weights, guiding LVLMs to focus on important visual content. Experimental results on diverse hallucination benchmarks validate the superiority of our method over existing state-of-the-art techniques in reducing hallucinations in LVLM text generation. Our code will be available at https://github.com/lijm48/IMCCD.
CLIP-GS: Unifying Vision-Language Representation with 3D Gaussian Splatting
Dec 26, 2024



Recent works in 3D multimodal learning have made remarkable progress. However, typically 3D multimodal models are only capable of handling point clouds. Compared to the emerging 3D representation technique, 3D Gaussian Splatting (3DGS), the spatially sparse point cloud cannot depict the texture information of 3D objects, resulting in inferior reconstruction capabilities. This limitation constrains the potential of point cloud-based 3D multimodal representation learning. In this paper, we present CLIP-GS, a novel multimodal representation learning framework grounded in 3DGS. We introduce the GS Tokenizer to generate serialized gaussian tokens, which are then processed through transformer layers pre-initialized with weights from point cloud models, resulting in the 3DGS embeddings. CLIP-GS leverages contrastive loss between 3DGS and the visual-text embeddings of CLIP, and we introduce an image voting loss to guide the directionality and convergence of gradient optimization. Furthermore, we develop an efficient way to generate triplets of 3DGS, images, and text, facilitating CLIP-GS in learning unified multimodal representations. Leveraging the well-aligned multimodal representations, CLIP-GS demonstrates versatility and outperforms point cloud-based models on various 3D tasks, including multimodal retrieval, zero-shot, and few-shot classification.
DriveMM: All-in-One Large Multimodal Model for Autonomous Driving
Dec 10, 2024



Large Multimodal Models (LMMs) have demonstrated exceptional comprehension and interpretation capabilities in Autonomous Driving (AD) by incorporating large language models. Despite the advancements, current data-driven AD approaches tend to concentrate on a single dataset and specific tasks, neglecting their overall capabilities and ability to generalize. To bridge these gaps, we propose DriveMM, a general large multimodal model designed to process diverse data inputs, such as images and multi-view videos, while performing a broad spectrum of AD tasks, including perception, prediction, and planning. Initially, the model undergoes curriculum pre-training to process varied visual signals and perform basic visual comprehension and perception tasks. Subsequently, we augment and standardize various AD-related datasets to fine-tune the model, resulting in an all-in-one LMM for autonomous driving. To assess the general capabilities and generalization ability, we conduct evaluations on six public benchmarks and undertake zero-shot transfer on an unseen dataset, where DriveMM achieves state-of-the-art performance across all tasks. We hope DriveMM as a promising solution for future end-toend autonomous driving applications in the real world.
TimeMarker: A Versatile Video-LLM for Long and Short Video Understanding with Superior Temporal Localization Ability
Nov 27, 2024



Rapid development of large language models (LLMs) has significantly advanced multimodal large language models (LMMs), particularly in vision-language tasks. However, existing video-language models often overlook precise temporal localization and struggle with videos of varying lengths. We introduce TimeMarker, a versatile Video-LLM designed for high-quality dialogue based on video content, emphasizing temporal localization. TimeMarker integrates Temporal Separator Tokens to enhance temporal awareness, accurately marking specific moments within videos. It employs the AnyLength mechanism for dynamic frame sampling and adaptive token merging, enabling effective handling of both short and long videos. Additionally, TimeMarker utilizes diverse datasets, including further transformed temporal-related video QA datasets, to bolster its temporal understanding capabilities. Image and interleaved data are also employed to further enhance the model's semantic perception ability. Evaluations demonstrate that TimeMarker achieves state-of-the-art performance across multiple benchmarks, excelling in both short and long video categories. Our project page is at \url{https://github.com/TimeMarker-LLM/TimeMarker/}.
VidCompress: Memory-Enhanced Temporal Compression for Video Understanding in Large Language Models
Oct 15, 2024



Video-based multimodal large language models (Video-LLMs) possess significant potential for video understanding tasks. However, most Video-LLMs treat videos as a sequential set of individual frames, which results in insufficient temporal-spatial interaction that hinders fine-grained comprehension and difficulty in processing longer videos due to limited visual token capacity. To address these challenges, we propose VidCompress, a novel Video-LLM featuring memory-enhanced temporal compression. VidCompress employs a dual-compressor approach: a memory-enhanced compressor captures both short-term and long-term temporal relationships in videos and compresses the visual tokens using a multiscale transformer with a memory-cache mechanism, while a text-perceived compressor generates condensed visual tokens by utilizing Q-Former and integrating temporal contexts into query embeddings with cross attention. Experiments on several VideoQA datasets and comprehensive benchmarks demonstrate that VidCompress efficiently models complex temporal-spatial relations and significantly outperforms existing Video-LLMs.