 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetis-HOME: Hybrid Optimized Mixture-of-Experts for Multimodal Reasoning
Oct 23, 2025Inspired by recent advancements in LLM reasoning, the field of multimodal reasoning has seen remarkable progress, achieving significant performance gains on intricate tasks such as mathematical problem-solving. Despite this progress, current multimodal large reasoning models exhibit two key limitations. They tend to employ computationally expensive reasoning even for simple queries, leading to inefficiency. Furthermore, this focus on specialized reasoning often impairs their broader, more general understanding capabilities. In this paper, we propose Metis-HOME: a Hybrid Optimized Mixture-of-Experts framework designed to address this trade-off. Metis-HOME enables a ''Hybrid Thinking'' paradigm by structuring the original dense model into two distinct expert branches: a thinking branch tailored for complex, multi-step reasoning, and a non-thinking branch optimized for rapid, direct inference on tasks like general VQA and OCR. A lightweight, trainable router dynamically allocates queries to the most suitable expert. We instantiate Metis-HOME by adapting the Qwen2.5-VL-7B into an MoE architecture. Comprehensive evaluations reveal that our approach not only substantially enhances complex reasoning abilities but also improves the model's general capabilities, reversing the degradation trend observed in other reasoning-specialized models. Our work establishes a new paradigm for building powerful and versatile MLLMs, effectively resolving the prevalent reasoning-vs-generalization dilemma.
Metis-RISE: RL Incentivizes and SFT Enhances Multimodal Reasoning Model Learning
Jun 16, 2025Recent advancements in large language models (LLMs) have witnessed a surge in the development of advanced reasoning paradigms, which are now being integrated into multimodal large language models (MLLMs). However, existing approaches often fall short: methods solely employing reinforcement learning (RL) can struggle with sample inefficiency and activating entirely absent reasoning capabilities, while conventional pipelines that initiate with a cold-start supervised fine-tuning (SFT) phase before RL may restrict the model's exploratory capacity and face suboptimal convergence. In this work, we introduce \textbf{Metis-RISE} (\textbf{R}L \textbf{I}ncentivizes and \textbf{S}FT \textbf{E}nhances) for multimodal reasoning model learning. Unlike conventional approaches, Metis-RISE distinctively omits an initial SFT stage, beginning instead with an RL phase (e.g., using a Group Relative Policy Optimization variant) to incentivize and activate the model's latent reasoning capacity. Subsequently, the targeted SFT stage addresses two key challenges identified during RL: (1) \textit{inefficient trajectory sampling} for tasks where the model possesses but inconsistently applies correct reasoning, which we tackle using self-distilled reasoning trajectories from the RL model itself; and (2) \textit{fundamental capability absence}, which we address by injecting expert-augmented knowledge for prompts where the model entirely fails. This strategic application of RL for incentivization followed by SFT for enhancement forms the core of Metis-RISE, leading to two versions of our MLLMs (7B and 72B parameters). Evaluations on the OpenCompass Multimodal Reasoning Leaderboard demonstrate that both models achieve state-of-the-art performance among similar-sized models, with the 72B version ranking fourth overall.
Feature Decomposition and Reconstruction Learning for Effective Facial Expression Recognition
Apr 21, 2021
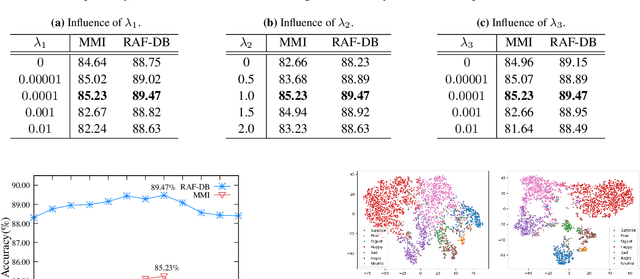
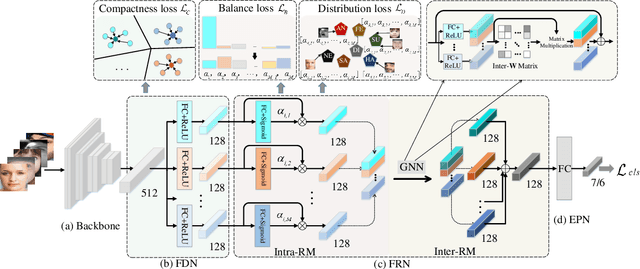
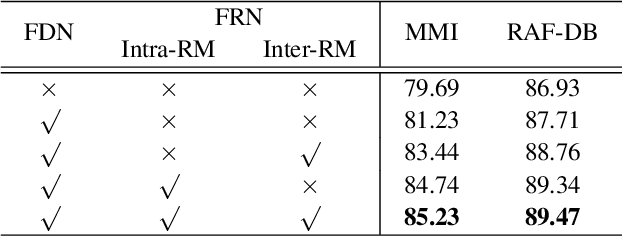
In this paper, we propose a novel Feature Decomposition and Reconstruction Learning (FDRL) method for effective facial expression recognition. We view the expression information as the combination of the shared information (expression similarities) across different expressions and the unique information (expression-specific variations) for each expression. More specifically, FDRL mainly consists of two crucial networks: a Feature Decomposition Network (FDN) and a Feature Reconstruction Network (FRN). In particular, FDN first decomposes the basic features extracted from a backbone network into a set of facial action-aware latent features to model expression similarities. Then, FRN captures the intra-feature and inter-feature relationships for latent features to characterize expression-specific variations, and reconstructs the expression feature. To this end, two modules including an intra-feature relation modeling module and an inter-feature relation modeling module are developed in FRN. Experimental results on both the in-the-lab databases (including CK+, MMI, and Oulu-CASIA) and the in-the-wild databases (including RAF-DB and SFEW) show that the proposed FDRL method consistently achieves higher recognition accuracy than several state-of-the-art methods. This clearly highlights the benefit of feature decomposition and reconstruction for classifying expressions.