 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntelligent Amphibious Ground-Aerial Vehicles: State of the Art Technology for Future Transportation
Jul 23, 2022



Amphibious ground-aerial vehicles fuse flying and driving modes to enable more flexible air-land mobility and have received growing attention recently. By analyzing the existing amphibious vehicles, we highlight the autonomous fly-driving functionality for the effective uses of amphibious vehicles in complex three-dimensional urban transportation systems. We review and summarize the key enabling technologies for intelligent flying-driving in existing amphibious vehicle designs, identify major technological barriers and propose potential solutions for future research and innovation. This paper aims to serve as a guide for research and development of intelligent amphibious vehicles for urban transportation toward the future.
Mix-Teaching: A Simple, Unified and Effective Semi-Supervised Learning Framework for Monocular 3D Object Detection
Jul 10, 2022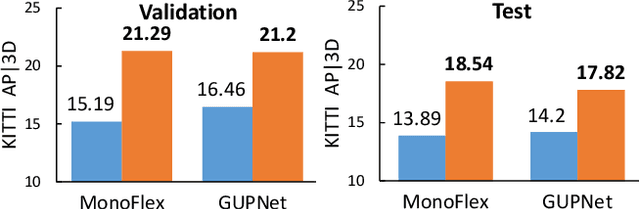
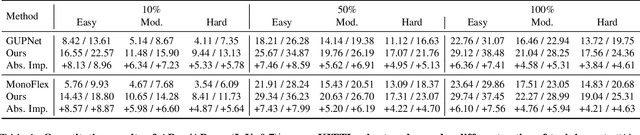
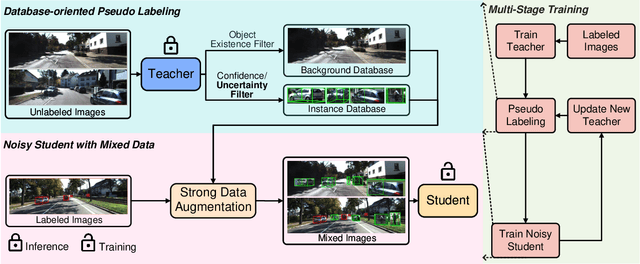
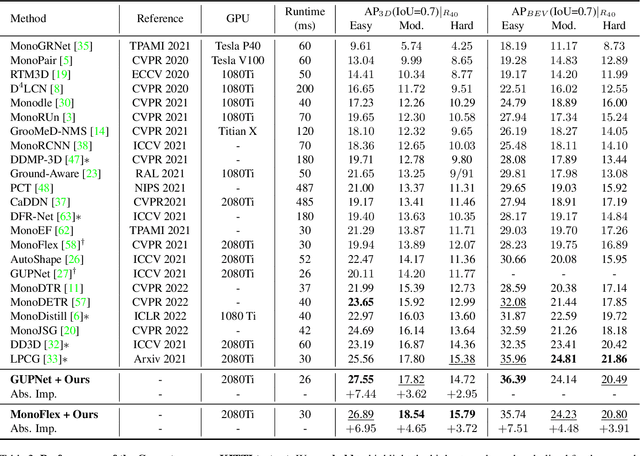
Monocular 3D object detection is an essential perception task for autonomous driving. However, the high reliance on large-scale labeled data make it costly and time-consuming during model optimization. To reduce such over-reliance on human annotations, we propose Mix-Teaching, an effective semi-supervised learning framework applicable to employ both labeled and unlabeled images in training stage. Mix-Teaching first generates pseudo-labels for unlabeled images by self-training. The student model is then trained on the mixed images possessing much more intensive and precise labeling by merging instance-level image patches into empty backgrounds or labeled images. This is the first to break the image-level limitation and put high-quality pseudo labels from multi frames into one image for semi-supervised training. Besides, as a result of the misalignment between confidence score and localization quality, it's hard to discriminate high-quality pseudo-labels from noisy predictions using only confidence-based criterion. To that end, we further introduce an uncertainty-based filter to help select reliable pseudo boxes for the above mixing operation. To the best of our knowledge, this is the first unified SSL framework for monocular 3D object detection. Mix-Teaching consistently improves MonoFlex and GUPNet by significant margins under various labeling ratios on KITTI dataset. For example, our method achieves around +6.34% AP@0.7 improvement against the GUPNet baseline on validation set when using only 10% labeled data. Besides, by leveraging full training set and the additional 48K raw images of KITTI, it can further improve the MonoFlex by +4.65% improvement on AP@0.7 for car detection, reaching 18.54% AP@0.7, which ranks the 1st place among all monocular based methods on KITTI test leaderboard. The code and pretrained models will be released at https://github.com/yanglei18/Mix-Teaching.
Detecting fake news by enhanced text representation with multi-EDU-structure awareness
May 30, 2022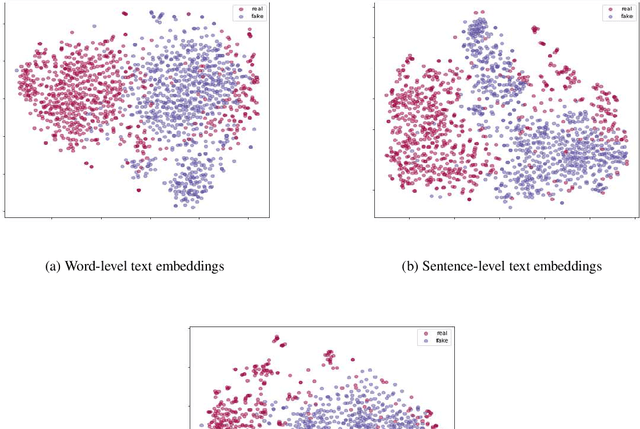


Since fake news poses a serious threat to society and individuals, numerous studies have been brought by considering text, propagation and user profiles. Due to the data collection problem, these methods based on propagation and user profiles are less applicable in the early stages. A good alternative method is to detect news based on text as soon as they are released, and a lot of text-based methods were proposed, which usually utilized words, sentences or paragraphs as basic units. But, word is a too fine-grained unit to express coherent information well, sentence or paragraph is too coarse to show specific information. Which granularity is better and how to utilize it to enhance text representation for fake news detection are two key problems. In this paper, we introduce Elementary Discourse Unit (EDU) whose granularity is between word and sentence, and propose a multi-EDU-structure awareness model to improve text representation for fake news detection, namely EDU4FD. For the multi-EDU-structure awareness, we build the sequence-based EDU representations and the graph-based EDU representations. The former is gotten by modeling the coherence between consecutive EDUs with TextCNN that reflect the semantic coherence. For the latter, we first extract rhetorical relations to build the EDU dependency graph, which can show the global narrative logic and help deliver the main idea truthfully. Then a Relation Graph Attention Network (RGAT) is set to get the graph-based EDU representation. Finally, the two EDU representations are incorporated as the enhanced text representation for fake news detection, using a gated recursive unit combined with a global attention mechanism. Experiments on four cross-source fake news datasets show that our model outperforms the state-of-the-art text-based methods.
Transfer Learning-based Channel Estimation in Orthogonal Frequency Division Multiplexing Systems Using Data-nulling Superimposed Pilots
May 28, 2022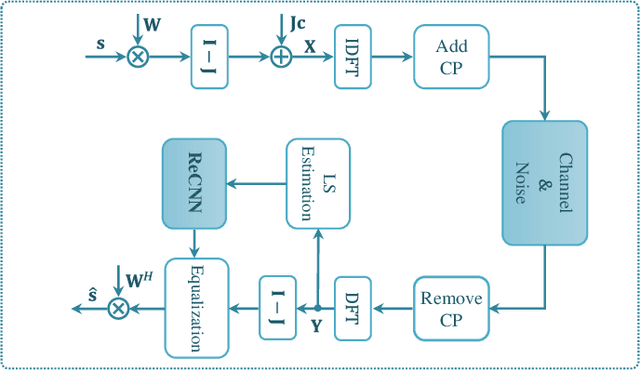
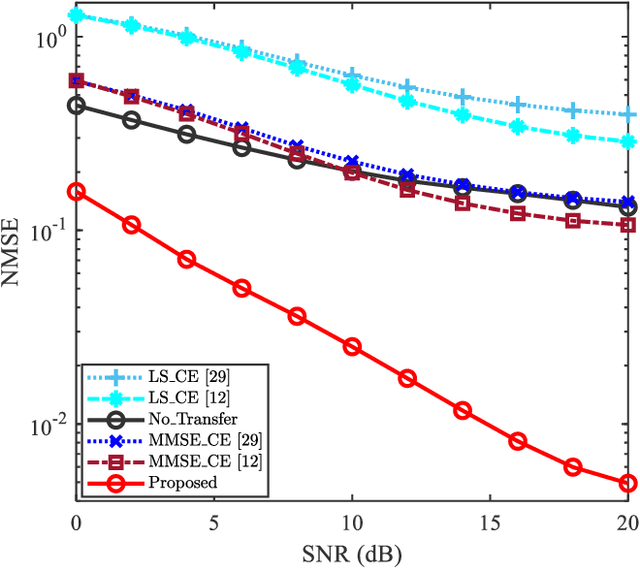
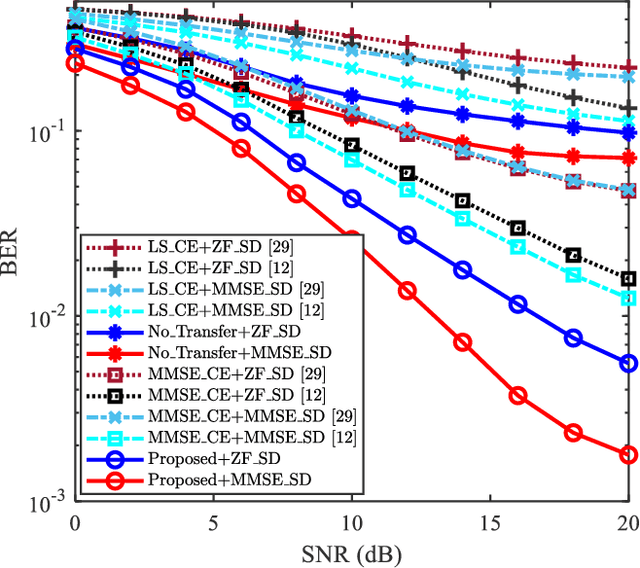
Data-nulling superimposed pilot (DNSP) effectively alleviates the superimposed interference of superimposed training (ST)-based channel estimation (CE) in orthogonal frequency division multiplexing (OFDM) systems, while facing the challenges of the estimation accuracy and computational complexity. By developing the promising solutions of deep learning (DL) in the physical layer of wireless communication, we fuse the DNSP and DL to tackle these challenges in this paper. Nevertheless, due to the changes of wireless scenarios, the model mismatch of DL leads to the performance degradation of CE, and thus faces the issue of network retraining. To address this issue, a lightweight transfer learning (TL) network is further proposed for the DL-based DNSP scheme, and thus structures a TL-based CE in OFDM systems. Specifically, based on the linear receiver, the least squares estimation is first employed to extract the initial features of CE. With the extracted features, we develop a convolutional neural network (CNN) to fuse the solutions of DLbased CE and the CE of DNSP. Finally, a lightweight TL network is constructed to address the model mismatch. To this end, a novel CE network for the DNSP scheme in OFDM systems is structured, which improves its estimation accuracy and alleviates the model mismatch. The experimental results show that in all signal-to-noise-ratio (SNR) regions, the proposed method achieves lower normalized mean squared error (NMSE) than the existing DNSP schemes with minimum mean square error (MMSE)-based CE. For example, when the SNR is 0 decibel (dB), the proposed scheme achieves similar NMSE as that of the MMSE-based CE scheme at 20 dB, thereby significantly improving the estimation accuracy of CE. In addition, relative to the existing schemes, the improvement of the proposed scheme presents its robustness against the impacts of parameter variations.
NTIRE 2022 Challenge on Efficient Super-Resolution: Methods and Results
May 11, 2022



This paper reviews the NTIRE 2022 challenge on efficient single image super-resolution with focus on the proposed solutions and results. The task of the challenge was to super-resolve an input image with a magnification factor of $\times$4 based on pairs of low and corresponding high resolution images. The aim was to design a network for single image super-resolution that achieved improvement of efficiency measured according to several metrics including runtime, parameters, FLOPs, activations, and memory consumption while at least maintaining the PSNR of 29.00dB on DIV2K validation set. IMDN is set as the baseline for efficiency measurement. The challenge had 3 tracks including the main track (runtime), sub-track one (model complexity), and sub-track two (overall performance). In the main track, the practical runtime performance of the submissions was evaluated. The rank of the teams were determined directly by the absolute value of the average runtime on the validation set and test set. In sub-track one, the number of parameters and FLOPs were considered. And the individual rankings of the two metrics were summed up to determine a final ranking in this track. In sub-track two, all of the five metrics mentioned in the description of the challenge including runtime, parameter count, FLOPs, activations, and memory consumption were considered. Similar to sub-track one, the rankings of five metrics were summed up to determine a final ranking. The challenge had 303 registered participants, and 43 teams made valid submissions. They gauge the state-of-the-art in efficient single image super-resolution.
ImpDet: Exploring Implicit Fields for 3D Object Detection
Mar 31, 2022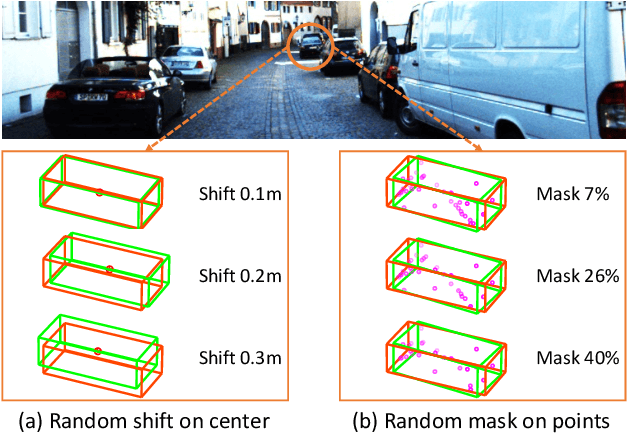
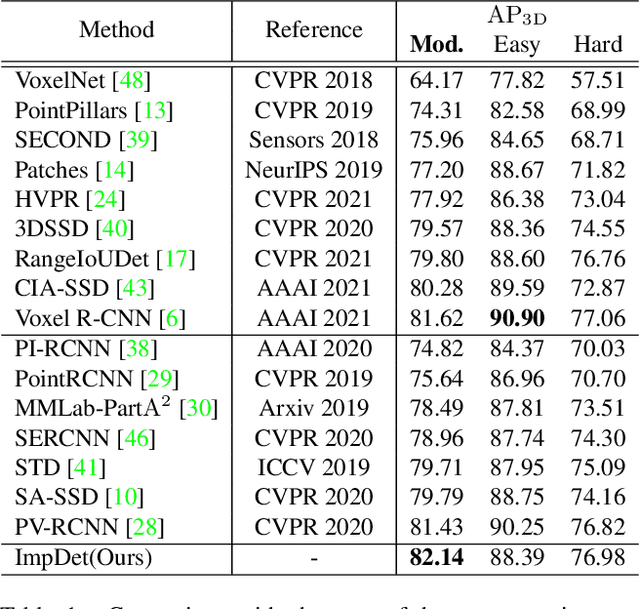
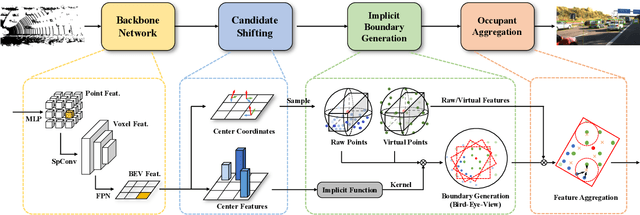
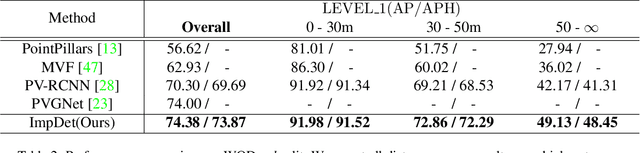
Conventional 3D object detection approaches concentrate on bounding boxes representation learning with several parameters, i.e., localization, dimension, and orientation. Despite its popularity and universality, such a straightforward paradigm is sensitive to slight numerical deviations, especially in localization. By exploiting the property that point clouds are naturally captured on the surface of objects along with accurate location and intensity information, we introduce a new perspective that views bounding box regression as an implicit function. This leads to our proposed framework, termed Implicit Detection or ImpDet, which leverages implicit field learning for 3D object detection. Our ImpDet assigns specific values to points in different local 3D spaces, thereby high-quality boundaries can be generated by classifying points inside or outside the boundary. To solve the problem of sparsity on the object surface, we further present a simple yet efficient virtual sampling strategy to not only fill the empty region, but also learn rich semantic features to help refine the boundaries. Extensive experimental results on KITTI and Waymo benchmarks demonstrate the effectiveness and robustness of unifying implicit fields into object detection.
Learning Decoupling Features Through Orthogonality Regularization
Mar 31, 2022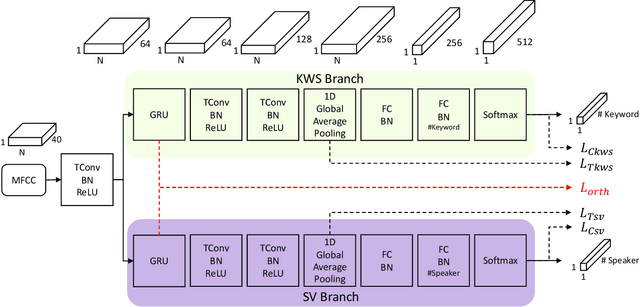
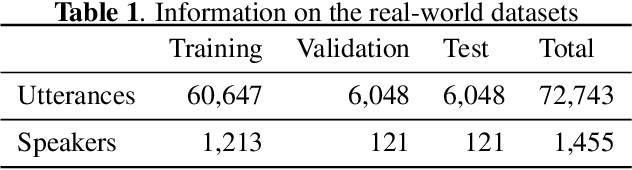
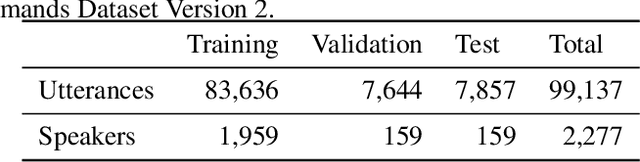
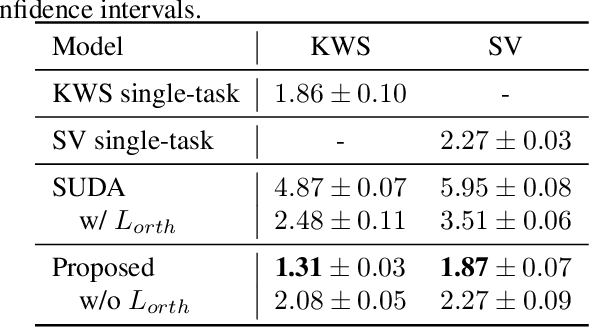
Keyword spotting (KWS) and speaker verification (SV) are two important tasks in speech applications. Research shows that the state-of-art KWS and SV models are trained independently using different datasets since they expect to learn distinctive acoustic features. However, humans can distinguish language content and the speaker identity simultaneously. Motivated by this, we believe it is important to explore a method that can effectively extract common features while decoupling task-specific features. Bearing this in mind, a two-branch deep network (KWS branch and SV branch) with the same network structure is developed and a novel decoupling feature learning method is proposed to push up the performance of KWS and SV simultaneously where speaker-invariant keyword representations and keyword-invariant speaker representations are expected respectively. Experiments are conducted on Google Speech Commands Dataset (GSCD). The results demonstrate that the orthogonality regularization helps the network to achieve SOTA EER of 1.31% and 1.87% on KWS and SV, respectively.
Source-free Domain Adaptation for Multi-site and Lifespan Brain Skull Stripping
Mar 11, 2022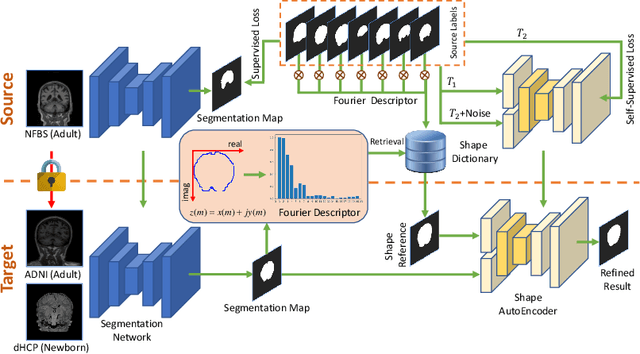

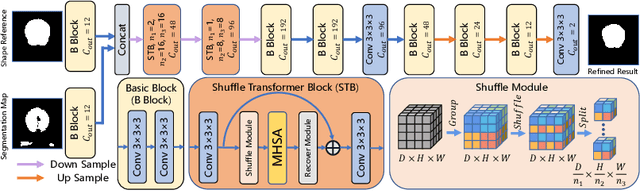

Skull stripping is a crucial prerequisite step in the analysis of brain magnetic resonance (MR) images. Although many excellent works or tools have been proposed, they suffer from low generalization capability. For instance, the model trained on a dataset with specific imaging parameters (source domain) cannot be well applied to other datasets with different imaging parameters (target domain). Especially, for the lifespan datasets, the model trained on an adult dataset is not applicable to an infant dataset due to the large domain difference. To address this issue, numerous domain adaptation (DA) methods have been proposed to align the extracted features between the source and target domains, requiring concurrent access to the input images of both domains. Unfortunately, it is problematic to share the images due to privacy. In this paper, we design a source-free domain adaptation framework (SDAF) for multi-site and lifespan skull stripping that can accomplish domain adaptation without access to source domain images. Our method only needs to share the source labels as shape dictionaries and the weights trained on the source data, without disclosing private information from source domain subjects. To deal with the domain shift between multi-site lifespan datasets, we take advantage of the brain shape prior which is invariant to imaging parameters and ages. Experiments demonstrate that our framework can significantly outperform the state-of-the-art methods on multi-site lifespan datasets.
Computer-Aided Road Inspection: Systems and Algorithms
Mar 04, 2022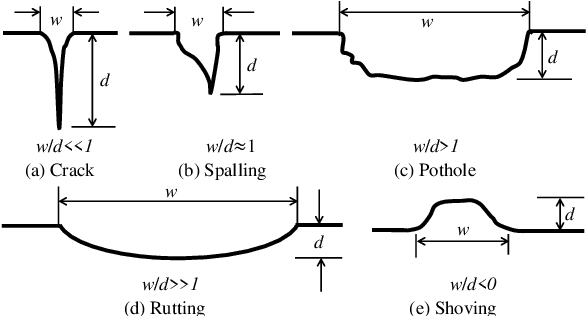
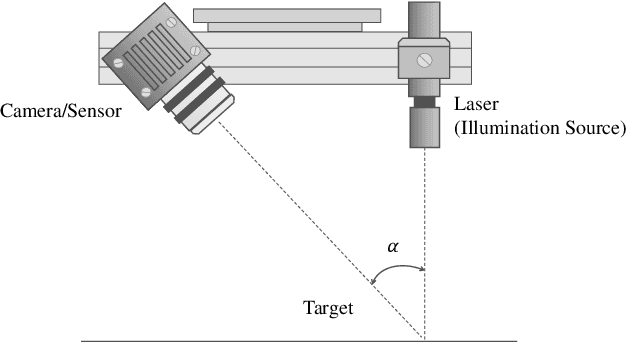
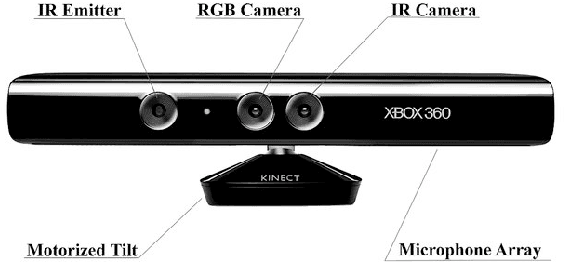
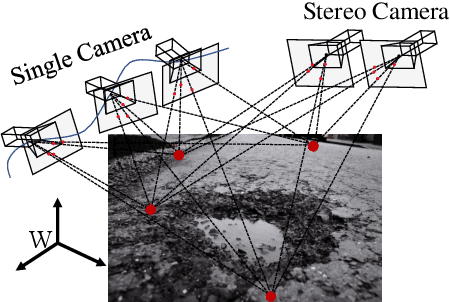
Road damage is an inconvenience and a safety hazard, severely affecting vehicle condition, driving comfort, and traffic safety. The traditional manual visual road inspection process is pricey, dangerous, exhausting, and cumbersome. Also, manual road inspection results are qualitative and subjective, as they depend entirely on the inspector's personal experience. Therefore, there is an ever-increasing need for automated road inspection systems. This chapter first compares the five most common road damage types. Then, 2-D/3-D road imaging systems are discussed. Finally, state-of-the-art machine vision and intelligence-based road damage detection algorithms are introduced.
A Framework for Multi-stage Bonus Allocation in meal delivery Platform
Feb 22, 2022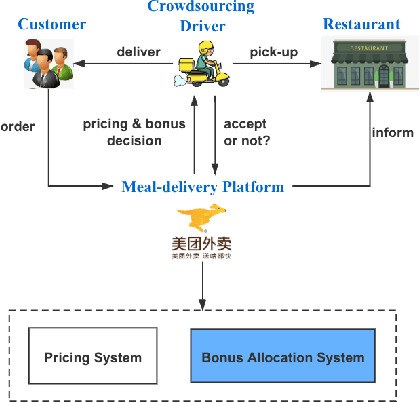

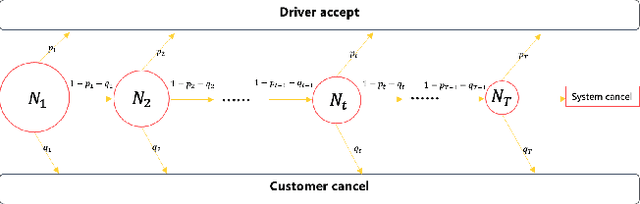
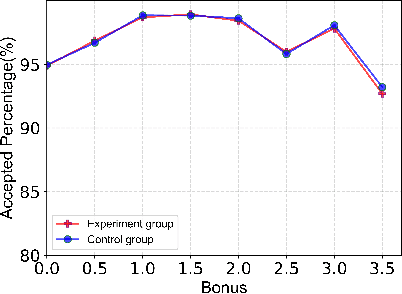
Online meal delivery is undergoing explosive growth, as this service is becoming increasingly popular. A meal delivery platform aims to provide excellent and stable services for customers and restaurants. However, in reality, several hundred thousand orders are canceled per day in the Meituan meal delivery platform since they are not accepted by the crowd soucing drivers. The cancellation of the orders is incredibly detrimental to the customer's repurchase rate and the reputation of the Meituan meal delivery platform. To solve this problem, a certain amount of specific funds is provided by Meituan's business managers to encourage the crowdsourcing drivers to accept more orders. To make better use of the funds, in this work, we propose a framework to deal with the multi-stage bonus allocation problem for a meal delivery platform. The objective of this framework is to maximize the number of accepted orders within a limited bonus budget. This framework consists of a semi-black-box acceptance probability model, a Lagrangian dual-based dynamic programming algorithm, and an online allocation algorithm. The semi-black-box acceptance probability model is employed to forecast the relationship between the bonus allocated to order and its acceptance probability, the Lagrangian dual-based dynamic programming algorithm aims to calculate the empirical Lagrangian multiplier for each allocation stage offline based on the historical data set, and the online allocation algorithm uses the results attained in the offline part to calculate a proper delivery bonus for each order. To verify the effectiveness and efficiency of our framework, both offline experiments on a real-world data set and online A/B tests on the Meituan meal delivery platform are conducted. Our results show that using the proposed framework, the total order cancellations can be decreased by more than 25\% in reality.