 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRainbow Delay Compensation: A Multi-Agent Reinforcement Learning Framework for Mitigating Delayed Observation
May 06, 2025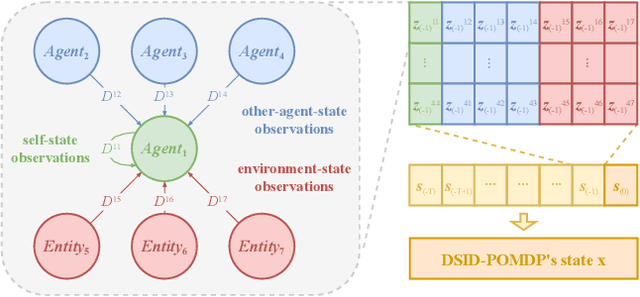

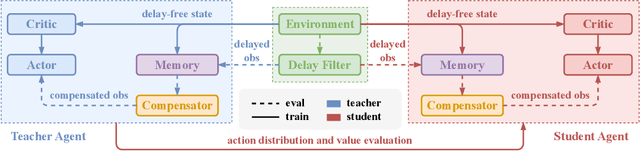
In real-world multi-agent systems (MASs), observation delays are ubiquitous, preventing agents from making decisions based on the environment's true state. An individual agent's local observation often consists of multiple components from other agents or dynamic entities in the environment. These discrete observation components with varying delay characteristics pose significant challenges for multi-agent reinforcement learning (MARL). In this paper, we first formulate the decentralized stochastic individual delay partially observable Markov decision process (DSID-POMDP) by extending the standard Dec-POMDP. We then propose the Rainbow Delay Compensation (RDC), a MARL training framework for addressing stochastic individual delays, along with recommended implementations for its constituent modules. We implement the DSID-POMDP's observation generation pattern using standard MARL benchmarks, including MPE and SMAC. Experiments demonstrate that baseline MARL methods suffer severe performance degradation under fixed and unfixed delays. The RDC-enhanced approach mitigates this issue, remarkably achieving ideal delay-free performance in certain delay scenarios while maintaining generalization capability. Our work provides a novel perspective on multi-agent delayed observation problems and offers an effective solution framework.
Automatic Text Pronunciation Correlation Generation and Application for Contextual Biasing
Jan 01, 2025



Effectively distinguishing the pronunciation correlations between different written texts is a significant issue in linguistic acoustics. Traditionally, such pronunciation correlations are obtained through manually designed pronunciation lexicons. In this paper, we propose a data-driven method to automatically acquire these pronunciation correlations, called automatic text pronunciation correlation (ATPC). The supervision required for this method is consistent with the supervision needed for training end-to-end automatic speech recognition (E2E-ASR) systems, i.e., speech and corresponding text annotations. First, the iteratively-trained timestamp estimator (ITSE) algorithm is employed to align the speech with their corresponding annotated text symbols. Then, a speech encoder is used to convert the speech into speech embeddings. Finally, we compare the speech embeddings distances of different text symbols to obtain ATPC. Experimental results on Mandarin show that ATPC enhances E2E-ASR performance in contextual biasing and holds promise for dialects or languages lacking artificial pronunciation lexicons.
Alternative Pseudo-Labeling for Semi-Supervised Automatic Speech Recognition
Aug 12, 2023



When labeled data is insufficient, semi-supervised learning with the pseudo-labeling technique can significantly improve the performance of automatic speech recognition. However, pseudo-labels are often noisy, containing numerous incorrect tokens. Taking noisy labels as ground-truth in the loss function results in suboptimal performance. Previous works attempted to mitigate this issue by either filtering out the nosiest pseudo-labels or improving the overall quality of pseudo-labels. While these methods are effective to some extent, it is unrealistic to entirely eliminate incorrect tokens in pseudo-labels. In this work, we propose a novel framework named alternative pseudo-labeling to tackle the issue of noisy pseudo-labels from the perspective of the training objective. The framework comprises several components. Firstly, a generalized CTC loss function is introduced to handle noisy pseudo-labels by accepting alternative tokens in the positions of incorrect tokens. Applying this loss function in pseudo-labeling requires detecting incorrect tokens in the predicted pseudo-labels. In this work, we adopt a confidence-based error detection method that identifies the incorrect tokens by comparing their confidence scores with a given threshold, thus necessitating the confidence score to be discriminative. Hence, the second proposed technique is the contrastive CTC loss function that widens the confidence gap between the correctly and incorrectly predicted tokens, thereby improving the error detection ability. Additionally, obtaining satisfactory performance with confidence-based error detection typically requires extensive threshold tuning. Instead, we propose an automatic thresholding method that uses labeled data as a proxy for determining the threshold, thus saving the pain of manual tuning.
Online Hybrid CTC/Attention End-to-End Automatic Speech Recognition Architecture
Jul 05, 2023



Recently, there has been increasing progress in end-to-end automatic speech recognition (ASR) architecture, which transcribes speech to text without any pre-trained alignments. One popular end-to-end approach is the hybrid Connectionist Temporal Classification (CTC) and attention (CTC/attention) based ASR architecture. However, how to deploy hybrid CTC/attention systems for online speech recognition is still a non-trivial problem. This article describes our proposed online hybrid CTC/attention end-to-end ASR architecture, which replaces all the offline components of conventional CTC/attention ASR architecture with their corresponding streaming components. Firstly, we propose stable monotonic chunk-wise attention (sMoChA) to stream the conventional global attention, and further propose monotonic truncated attention (MTA) to simplify sMoChA and solve the training-and-decoding mismatch problem of sMoChA. Secondly, we propose truncated CTC (T-CTC) prefix score to stream CTC prefix score calculation. Thirdly, we design dynamic waiting joint decoding (DWJD) algorithm to dynamically collect the predictions of CTC and attention in an online manner. Finally, we use latency-controlled bidirectional long short-term memory (LC-BLSTM) to stream the widely-used offline bidirectional encoder network. Experiments with LibriSpeech English and HKUST Mandarin tasks demonstrate that, compared with the offline CTC/attention model, our proposed online CTC/attention model improves the real time factor in human-computer interaction services and maintains its performance with moderate degradation. To the best of our knowledge, this is the first work to provide the full-stack online solution for CTC/attention end-to-end ASR architecture.
ForkNet: Simultaneous Time and Time-Frequency Domain Modeling for Speech Enhancement
May 15, 2023Previous research in speech enhancement has mostly focused on modeling time or time-frequency domain information alone, with little consideration given to the potential benefits of simultaneously modeling both domains. Since these domains contain complementary information, combining them may improve the performance of the model. In this letter, we propose a new approach to simultaneously model time and time-frequency domain information in a single model. We begin with the DPT-FSNet (causal version) model as a baseline and modify the encoder structure by replacing the original encoder with three separate encoders, each dedicated to modeling time-domain, real-imaginary, and magnitude information, respectively. Additionally, we introduce a feature fusion module both before and after the dual-path processing blocks to better leverage information from the different domains. The outcomes of our experiments reveal that the proposed approach achieves superior performance compared to existing state-of-the-art causal models, while preserving a relatively compact model size and low computational complexity.
Speech Corpora Divergence Based Unsupervised Data Selection for ASR
Feb 26, 2023Selecting application scenarios matching data is important for the automatic speech recognition (ASR) training, but it is difficult to measure the matching degree of the training corpus. This study proposes a unsupervised target-aware data selection method based on speech corpora divergence (SCD), which can measure the similarity between two speech corpora. We first use the self-supervised Hubert model to discretize the speech corpora into label sequence and calculate the N-gram probability distribution. Then we calculate the Kullback-Leibler divergence between the N-grams as the SCD. Finally, we can choose the subset which has minimum SCD to the target corpus for annotation and training. Compared to previous data selection method, the SCD data selection method can focus on more acoustic details and guarantee the diversity of the selected set. We evaluate our method on different accents from Common Voice. Experiments show that the proposed SCD data selection can realize 14.8% relative improvements to the random selection, comparable or even superior to the result of supervised selection.
Summary on the ISCSLP 2022 Chinese-English Code-Switching ASR Challenge
Oct 13, 2022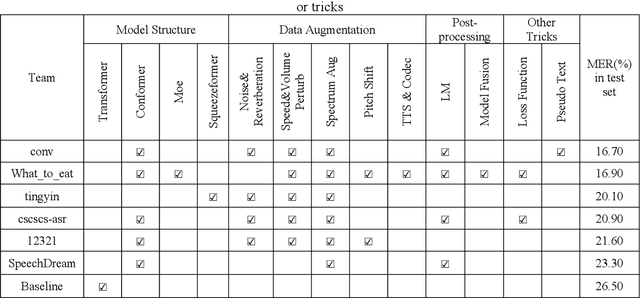
Code-switching automatic speech recognition becomes one of the most challenging and the most valuable scenarios of automatic speech recognition, due to the code-switching phenomenon between multilingual language and the frequent occurrence of code-switching phenomenon in daily life. The ISCSLP 2022 Chinese-English Code-Switching Automatic Speech Recognition (CSASR) Challenge aims to promote the development of code-switching automatic speech recognition. The ISCSLP 2022 CSASR challenge provided two training sets, TAL_CSASR corpus and MagicData-RAMC corpus, a development and a test set for participants, which are used for CSASR model training and evaluation. Along with the challenge, we also provide the baseline system performance for reference. As a result, more than 40 teams participated in this challenge, and the winner team achieved 16.70% Mixture Error Rate (MER) performance on the test set and has achieved 9.8% MER absolute improvement compared with the baseline system. In this paper, we will describe the datasets, the associated baselines system and the requirements, and summarize the CSASR challenge results and major techniques and tricks used in the submitted systems.
The Conversational Short-phrase Speaker Diarization (CSSD) Task: Dataset, Evaluation Metric and Baselines
Aug 17, 2022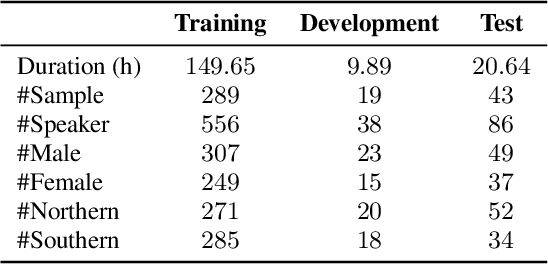

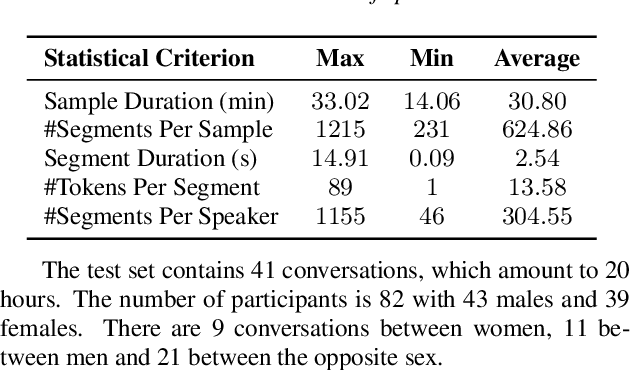
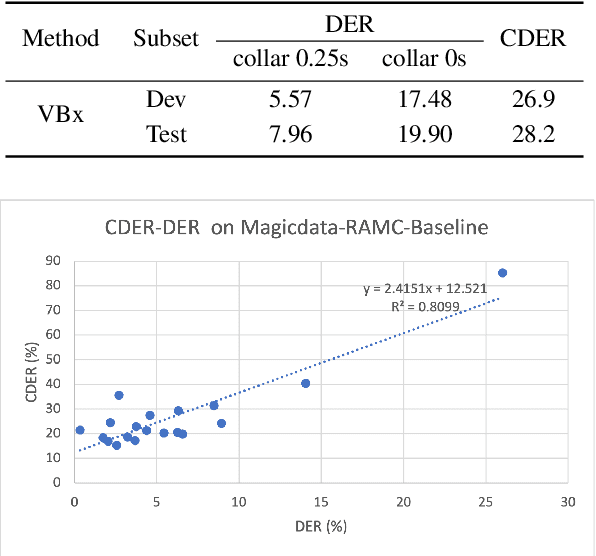
The conversation scenario is one of the most important and most challenging scenarios for speech processing technologies because people in conversation respond to each other in a casual style. Detecting the speech activities of each person in a conversation is vital to downstream tasks, like natural language processing, machine translation, etc. People refer to the detection technology of "who speak when" as speaker diarization (SD). Traditionally, diarization error rate (DER) has been used as the standard evaluation metric of SD systems for a long time. However, DER fails to give enough importance to short conversational phrases, which are short but important on the semantic level. Also, a carefully and accurately manually-annotated testing dataset suitable for evaluating the conversational SD technologies is still unavailable in the speech community. In this paper, we design and describe the Conversational Short-phrases Speaker Diarization (CSSD) task, which consists of training and testing datasets, evaluation metric and baselines. In the dataset aspect, despite the previously open-sourced 180-hour conversational MagicData-RAMC dataset, we prepare an individual 20-hour conversational speech test dataset with carefully and artificially verified speakers timestamps annotations for the CSSD task. In the metric aspect, we design the new conversational DER (CDER) evaluation metric, which calculates the SD accuracy at the utterance level. In the baseline aspect, we adopt a commonly used method: Variational Bayes HMM x-vector system, as the baseline of the CSSD task. Our evaluation metric is publicly available at https://github.com/SpeechClub/CDER_Metric.
Improving Streaming End-to-End ASR on Transformer-based Causal Models with Encoder States Revision Strategies
Jul 06, 2022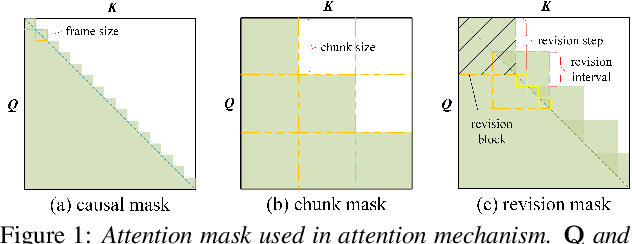
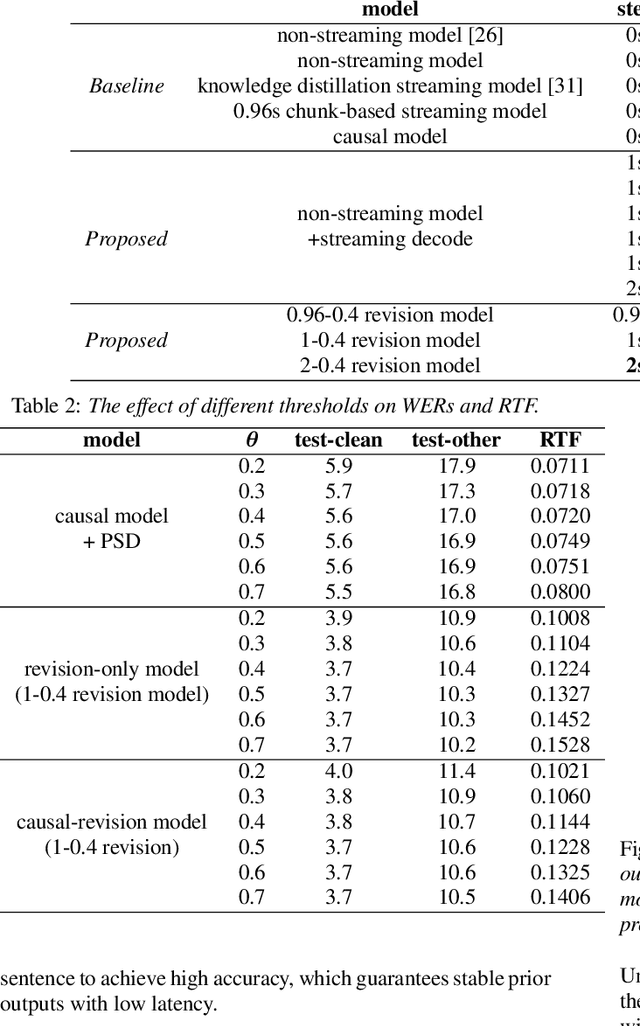
There is often a trade-off between performance and latency in streaming automatic speech recognition (ASR). Traditional methods such as look-ahead and chunk-based methods, usually require information from future frames to advance recognition accuracy, which incurs inevitable latency even if the computation is fast enough. A causal model that computes without any future frames can avoid this latency, but its performance is significantly worse than traditional methods. In this paper, we propose corresponding revision strategies to improve the causal model. Firstly, we introduce a real-time encoder states revision strategy to modify previous states. Encoder forward computation starts once the data is received and revises the previous encoder states after several frames, which is no need to wait for any right context. Furthermore, a CTC spike position alignment decoding algorithm is designed to reduce time costs brought by the revision strategy. Experiments are all conducted on Librispeech datasets. Fine-tuning on the CTC-based wav2vec2.0 model, our best method can achieve 3.7/9.2 WERs on test-clean/other sets, which is also competitive with the chunk-based methods and the knowledge distillation methods.
Interrelate Training and Searching: A Unified Online Clustering Framework for Speaker Diarization
Jun 28, 2022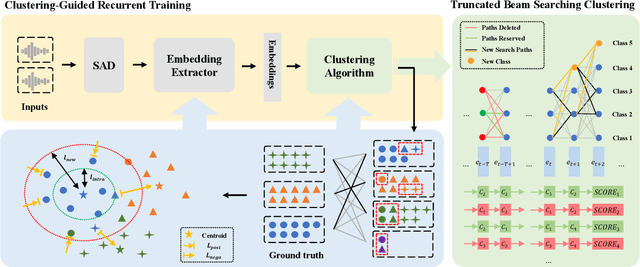
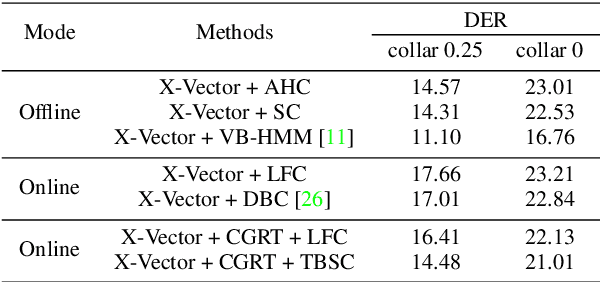
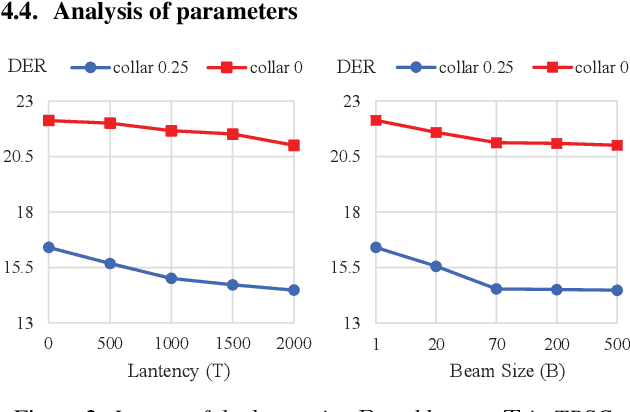
For online speaker diarization, samples arrive incrementally, and the overall distribution of the samples is invisible. Moreover, in most existing clustering-based methods, the training objective of the embedding extractor is not designed specially for clustering. To improve online speaker diarization performance, we propose a unified online clustering framework, which provides an interactive manner between embedding extractors and clustering algorithms. Specifically, the framework consists of two highly coupled parts: clustering-guided recurrent training (CGRT) and truncated beam searching clustering (TBSC). The CGRT introduces the clustering algorithm into the training process of embedding extractors, which could provide not only cluster-aware information for the embedding extractor, but also crucial parameters for the clustering process afterward. And with these parameters, which contain preliminary information of the metric space, the TBSC penalizes the probability score of each cluster, in order to output more accurate clustering results in online fashion with low latency. With the above innovations, our proposed online clustering system achieves 14.48\% DER with collar 0.25 at 2.5s latency on the AISHELL-4, while the DER of the offline agglomerative hierarchical clustering is 14.57\%.