 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUSE: Uncertainty Structure Estimation for Robust Semi-Supervised Learning
Feb 28, 2026In this study, a novel idea, Uncertainty Structure Estimation (USE), a lightweight, algorithm-agnostic procedure that emphasizes the often-overlooked role of unlabeled data quality is introduced for Semi-supervised learning (SSL). SSL has achieved impressive progress, but its reliability in deployment is limited by the quality of the unlabeled pool. In practice, unlabeled data are almost always contaminated by out-of-distribution (OOD) samples, where both near-OOD and far-OOD can negatively affect performance in different ways. We argue that the bottleneck does not lie in algorithmic design, but rather in the absence of principled mechanisms to assess and curate the quality of unlabeled data. The proposed USE trains a proxy model on the labeled set to compute entropy scores for unlabeled samples, and then derives a threshold, via statistical comparison against a reference distribution, that separates informative (structured) from uninformative (structureless) samples. This enables assessment as a preprocessing step, removing uninformative or harmful unlabeled data before SSL training begins. Through extensive experiments on imaging (CIFAR-100) and NLP (Yelp Review) data, it is evident that USE consistently improves accuracy and robustness under varying levels of OOD contamination. Thus, it can be concluded that the proposed approach reframes unlabeled data quality control as a structural assessment problem, and considers it as a necessary component for reliable and efficient SSL in realistic mixed-distribution environments.
Two-Stage Mesh Deep Learning for Automated Tooth Segmentation and Landmark Localization on 3D Intraoral Scans
Sep 24, 2021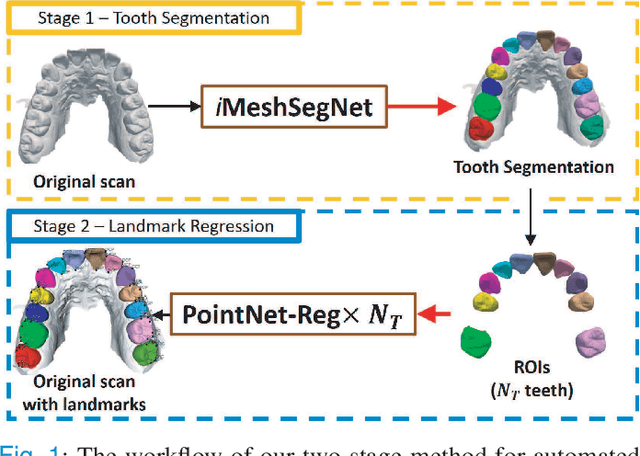
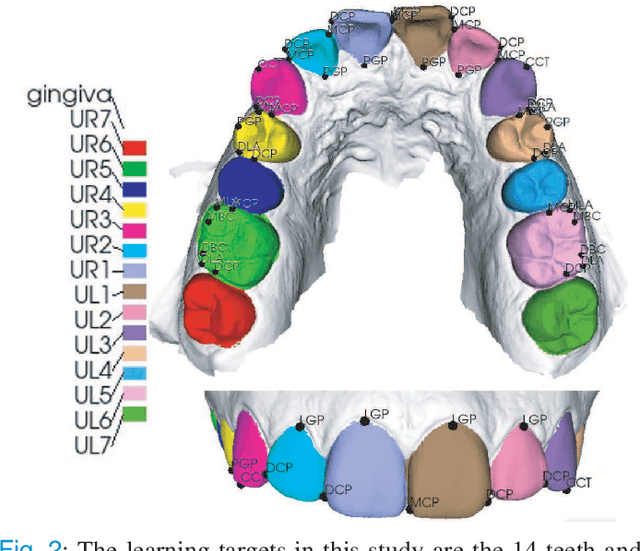
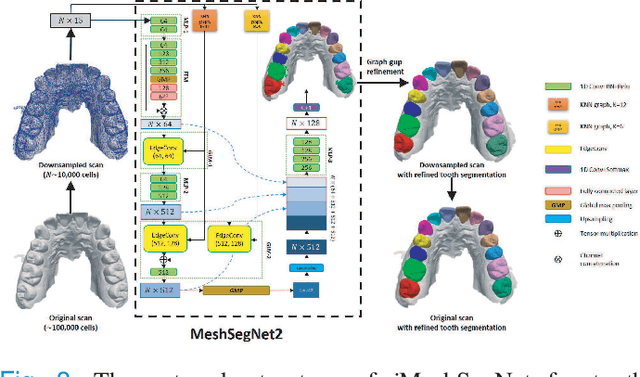
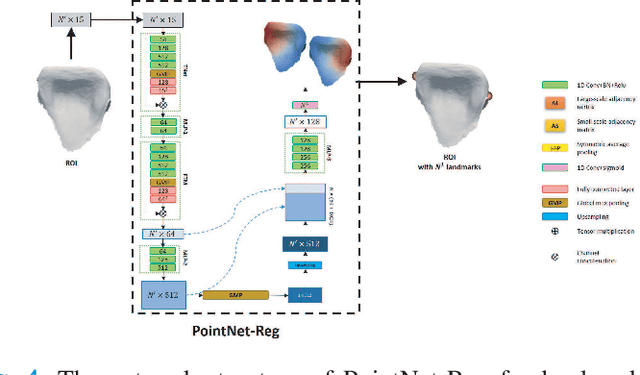
Accurately segmenting teeth and identifying the corresponding anatomical landmarks on dental mesh models are essential in computer-aided orthodontic treatment. Manually performing these two tasks is time-consuming, tedious, and, more importantly, highly dependent on orthodontists' experiences due to the abnormality and large-scale variance of patients' teeth. Some machine learning-based methods have been designed and applied in the orthodontic field to automatically segment dental meshes (e.g., intraoral scans). In contrast, the number of studies on tooth landmark localization is still limited. This paper proposes a two-stage framework based on mesh deep learning (called TS-MDL) for joint tooth labeling and landmark identification on raw intraoral scans. Our TS-MDL first adopts an end-to-end \emph{i}MeshSegNet method (i.e., a variant of the existing MeshSegNet with both improved accuracy and efficiency) to label each tooth on the downsampled scan. Guided by the segmentation outputs, our TS-MDL further selects each tooth's region of interest (ROI) on the original mesh to construct a light-weight variant of the pioneering PointNet (i.e., PointNet-Reg) for regressing the corresponding landmark heatmaps. Our TS-MDL was evaluated on a real-clinical dataset, showing promising segmentation and localization performance. Specifically, \emph{i}MeshSegNet in the first stage of TS-MDL reached an averaged Dice similarity coefficient (DSC) at $0.953\pm0.076$, significantly outperforming the original MeshSegNet. In the second stage, PointNet-Reg achieved a mean absolute error (MAE) of $0.623\pm0.718 \, mm$ in distances between the prediction and ground truth for $44$ landmarks, which is superior compared with other networks for landmark detection. All these results suggest the potential usage of our TS-MDL in clinical practices.