 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePanoWorld: Towards Spatial Supersensing in 360$^\circ$ Panorama World
May 13, 2026Multimodal large laboratory models (MLLMs) still struggle with spatial understanding under the dominant perspective-image paradigm, which inherits the narrow field of view of human-like perception. For navigation, robotic search, and 3D scene understanding, 360-degree panoramic sensing offers a form of supersensing by capturing the entire surrounding environment at once. However, existing MLLM pipelines typically decompose panoramas into multiple perspective views, leaving the spherical structure of equirectangular projection (ERP) largely implicit. In this paper, we study pano-native understanding, which requires an MLLM to reason over an ERP panorama as a continuous, observer-centered space. To this end, we first define the key abilities for pano-native understanding, including semantic anchoring, spherical localization, reference-frame transformation, and depth-aware 3D spatial reasoning. We then build a large-scale metadata construction pipeline that converts mixed-source ERP panoramas into geometry-aware, language-grounded, and depth-aware supervision, and instantiate these signals as capability-aligned instruction tuning data. On the model side, we introduce PanoWorld with Spherical Spatial Cross-Attention, which injects spherical geometry into the visual stream. We further construct PanoSpace-Bench, a diagnostic benchmark for evaluating ERP-native spatial reasoning. Experiments show that PanoWorld substantially outperforms both proprietary and open-source baselines on PanoSpace-Bench, H* Bench, and R2R-CE Val-Unseen benchmarks. These results demonstrate that robust panoramic reasoning requires dedicated pano-native supervision and geometry-aware model adaptation. All source code and proposed data will be publicly released.
Hermes: Memory-Efficient Pipeline Inference for Large Models on Edge Devices
Sep 09, 2024



The application of Transformer-based large models has achieved numerous success in recent years. However, the exponential growth in the parameters of large models introduces formidable memory challenge for edge deployment. Prior works to address this challenge mainly focus on optimizing the model structure and adopting memory swapping methods. However, the former reduces the inference accuracy, and the latter raises the inference latency. This paper introduces PIPELOAD, a novel memory-efficient pipeline execution mechanism. It reduces memory usage by incorporating dynamic memory management and minimizes inference latency by employing parallel model loading. Based on PIPELOAD mechanism, we present Hermes, a framework optimized for large model inference on edge devices. We evaluate Hermes on Transformer-based models of different sizes. Our experiments illustrate that Hermes achieves up to 4.24 X increase in inference speed and 86.7% lower memory consumption than the state-of-the-art pipeline mechanism for BERT and ViT models, 2.58 X increase in inference speed and 90.3% lower memory consumption for GPT-style models.
Privacy Threats Analysis to Secure Federated Learning
Jun 24, 2021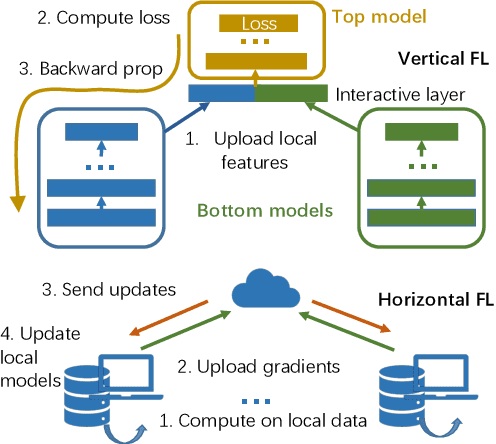
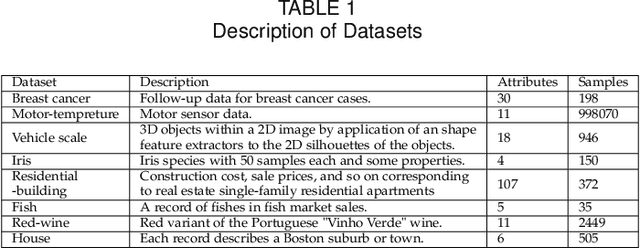
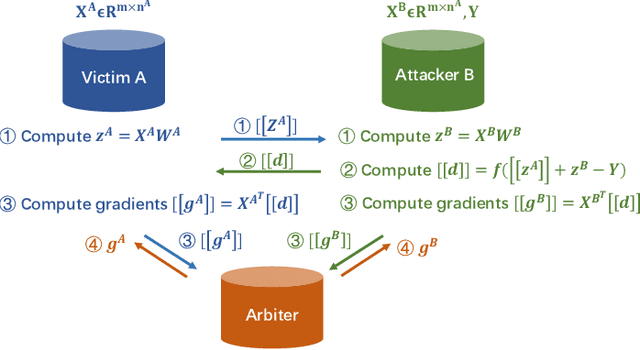
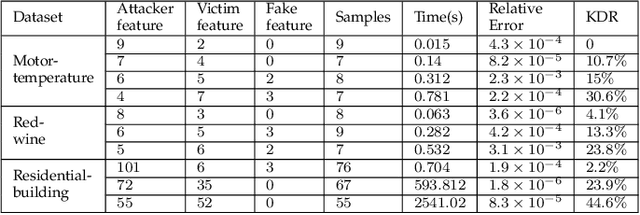
Federated learning is emerging as a machine learning technique that trains a model across multiple decentralized parties. It is renowned for preserving privacy as the data never leaves the computational devices, and recent approaches further enhance its privacy by hiding messages transferred in encryption. However, we found that despite the efforts, federated learning remains privacy-threatening, due to its interactive nature across different parties. In this paper, we analyze the privacy threats in industrial-level federated learning frameworks with secure computation, and reveal such threats widely exist in typical machine learning models such as linear regression, logistic regression and decision tree. For the linear and logistic regression, we show through theoretical analysis that it is possible for the attacker to invert the entire private input of the victim, given very few information. For the decision tree model, we launch an attack to infer the range of victim's private inputs. All attacks are evaluated on popular federated learning frameworks and real-world datasets.