 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrototype-Guided Curriculum Learning for Zero-Shot Learning
Aug 11, 2025In Zero-Shot Learning (ZSL), embedding-based methods enable knowledge transfer from seen to unseen classes by learning a visual-semantic mapping from seen-class images to class-level semantic prototypes (e.g., attributes). However, these semantic prototypes are manually defined and may introduce noisy supervision for two main reasons: (i) instance-level mismatch: variations in perspective, occlusion, and annotation bias will cause discrepancies between individual sample and the class-level semantic prototypes; and (ii) class-level imprecision: the manually defined semantic prototypes may not accurately reflect the true semantics of the class. Consequently, the visual-semantic mapping will be misled, reducing the effectiveness of knowledge transfer to unseen classes. In this work, we propose a prototype-guided curriculum learning framework (dubbed as CLZSL), which mitigates instance-level mismatches through a Prototype-Guided Curriculum Learning (PCL) module and addresses class-level imprecision via a Prototype Update (PUP) module. Specifically, the PCL module prioritizes samples with high cosine similarity between their visual mappings and the class-level semantic prototypes, and progressively advances to less-aligned samples, thereby reducing the interference of instance-level mismatches to achieve accurate visual-semantic mapping. Besides, the PUP module dynamically updates the class-level semantic prototypes by leveraging the visual mappings learned from instances, thereby reducing class-level imprecision and further improving the visual-semantic mapping. Experiments were conducted on standard benchmark datasets-AWA2, SUN, and CUB-to verify the effectiveness of our method.
HSA-Net: Hierarchical and Structure-Aware Framework for Efficient and Scalable Molecular Language Modeling
Aug 10, 2025Molecular representation learning, a cornerstone for downstream tasks like molecular captioning and molecular property prediction, heavily relies on Graph Neural Networks (GNN). However, GNN suffers from the over-smoothing problem, where node-level features collapse in deep GNN layers. While existing feature projection methods with cross-attention have been introduced to mitigate this issue, they still perform poorly in deep features. This motivated our exploration of using Mamba as an alternative projector for its ability to handle complex sequences. However, we observe that while Mamba excels at preserving global topological information from deep layers, it neglects fine-grained details in shallow layers. The capabilities of Mamba and cross-attention exhibit a global-local trade-off. To resolve this critical global-local trade-off, we propose Hierarchical and Structure-Aware Network (HSA-Net), a novel framework with two modules that enables a hierarchical feature projection and fusion. Firstly, a Hierarchical Adaptive Projector (HAP) module is introduced to process features from different graph layers. It learns to dynamically switch between a cross-attention projector for shallow layers and a structure-aware Graph-Mamba projector for deep layers, producing high-quality, multi-level features. Secondly, to adaptively merge these multi-level features, we design a Source-Aware Fusion (SAF) module, which flexibly selects fusion experts based on the characteristics of the aggregation features, ensuring a precise and effective final representation fusion. Extensive experiments demonstrate that our HSA-Net framework quantitatively and qualitatively outperforms current state-of-the-art (SOTA) methods.
HunyuanWorld 1.0: Generating Immersive, Explorable, and Interactive 3D Worlds from Words or Pixels
Jul 29, 2025



Creating immersive and playable 3D worlds from texts or images remains a fundamental challenge in computer vision and graphics. Existing world generation approaches typically fall into two categories: video-based methods that offer rich diversity but lack 3D consistency and rendering efficiency, and 3D-based methods that provide geometric consistency but struggle with limited training data and memory-inefficient representations. To address these limitations, we present HunyuanWorld 1.0, a novel framework that combines the best of both worlds for generating immersive, explorable, and interactive 3D scenes from text and image conditions. Our approach features three key advantages: 1) 360{\deg} immersive experiences via panoramic world proxies; 2) mesh export capabilities for seamless compatibility with existing computer graphics pipelines; 3) disentangled object representations for augmented interactivity. The core of our framework is a semantically layered 3D mesh representation that leverages panoramic images as 360{\deg} world proxies for semantic-aware world decomposition and reconstruction, enabling the generation of diverse 3D worlds. Extensive experiments demonstrate that our method achieves state-of-the-art performance in generating coherent, explorable, and interactive 3D worlds while enabling versatile applications in virtual reality, physical simulation, game development, and interactive content creation.
BOASF: A Unified Framework for Speeding up Automatic Machine Learning via Adaptive Successive Filtering
Jul 28, 2025Machine learning has been making great success in many application areas. However, for the non-expert practitioners, it is always very challenging to address a machine learning task successfully and efficiently. Finding the optimal machine learning model or the hyperparameter combination set from a large number of possible alternatives usually requires considerable expert knowledge and experience. To tackle this problem, we propose a combined Bayesian Optimization and Adaptive Successive Filtering algorithm (BOASF) under a unified multi-armed bandit framework to automate the model selection or the hyperparameter optimization. Specifically, BOASF consists of multiple evaluation rounds in each of which we select promising configurations for each arm using the Bayesian optimization. Then, ASF can early discard the poor-performed arms adaptively using a Gaussian UCB-based probabilistic model. Furthermore, a Softmax model is employed to adaptively allocate available resources for each promising arm that advances to the next round. The arm with a higher probability of advancing will be allocated more resources. Experimental results show that BOASF is effective for speeding up the model selection and hyperparameter optimization processes while achieving robust and better prediction performance than the existing state-of-the-art automatic machine learning methods. Moreover, BOASF achieves better anytime performance under various time budgets.
Representation Entanglement for Generation:Training Diffusion Transformers Is Much Easier Than You Think
Jul 02, 2025
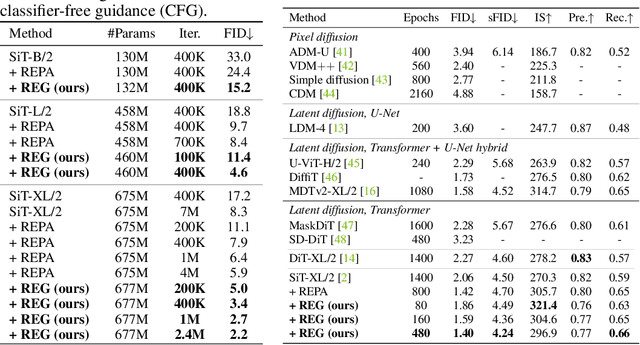
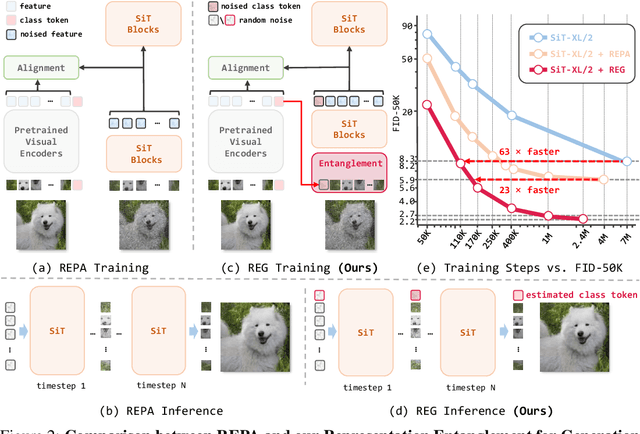
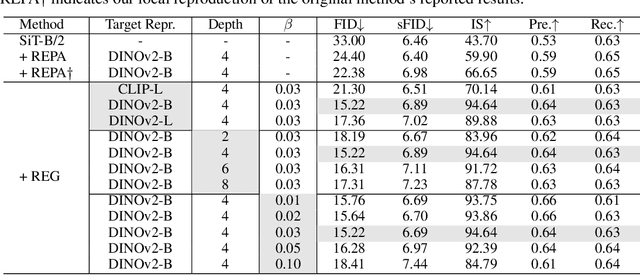
REPA and its variants effectively mitigate training challenges in diffusion models by incorporating external visual representations from pretrained models, through alignment between the noisy hidden projections of denoising networks and foundational clean image representations. We argue that the external alignment, which is absent during the entire denoising inference process, falls short of fully harnessing the potential of discriminative representations. In this work, we propose a straightforward method called Representation Entanglement for Generation (REG), which entangles low-level image latents with a single high-level class token from pretrained foundation models for denoising. REG acquires the capability to produce coherent image-class pairs directly from pure noise, substantially improving both generation quality and training efficiency. This is accomplished with negligible additional inference overhead, requiring only one single additional token for denoising (<0.5\% increase in FLOPs and latency). The inference process concurrently reconstructs both image latents and their corresponding global semantics, where the acquired semantic knowledge actively guides and enhances the image generation process. On ImageNet 256$\times$256, SiT-XL/2 + REG demonstrates remarkable convergence acceleration, achieving $\textbf{63}\times$ and $\textbf{23}\times$ faster training than SiT-XL/2 and SiT-XL/2 + REPA, respectively. More impressively, SiT-L/2 + REG trained for merely 400K iterations outperforms SiT-XL/2 + REPA trained for 4M iterations ($\textbf{10}\times$ longer). Code is available at: https://github.com/Martinser/REG.
ChartReasoner: Code-Driven Modality Bridging for Long-Chain Reasoning in Chart Question Answering
Jun 11, 2025Recently, large language models have shown remarkable reasoning capabilities through long-chain reasoning before responding. However, how to extend this capability to visual reasoning tasks remains an open challenge. Existing multimodal reasoning approaches transfer such visual reasoning task into textual reasoning task via several image-to-text conversions, which often lose critical structural and semantic information embedded in visualizations, especially for tasks like chart question answering that require a large amount of visual details. To bridge this gap, we propose ChartReasoner, a code-driven novel two-stage framework designed to enable precise, interpretable reasoning over charts. We first train a high-fidelity model to convert diverse chart images into structured ECharts codes, preserving both layout and data semantics as lossless as possible. Then, we design a general chart reasoning data synthesis pipeline, which leverages this pretrained transport model to automatically and scalably generate chart reasoning trajectories and utilizes a code validator to filter out low-quality samples. Finally, we train the final multimodal model using a combination of supervised fine-tuning and reinforcement learning on our synthesized chart reasoning dataset and experimental results on four public benchmarks clearly demonstrate the effectiveness of our proposed ChartReasoner. It can preserve the original details of the charts as much as possible and perform comparably with state-of-the-art open-source models while using fewer parameters, approaching the performance of proprietary systems like GPT-4o in out-of-domain settings.
SeerAttention-R: Sparse Attention Adaptation for Long Reasoning
Jun 10, 2025



We introduce SeerAttention-R, a sparse attention framework specifically tailored for the long decoding of reasoning models. Extended from SeerAttention, SeerAttention-R retains the design of learning attention sparsity through a self-distilled gating mechanism, while removing query pooling to accommodate auto-regressive decoding. With a lightweight plug-in gating, SeerAttention-R is flexible and can be easily integrated into existing pretrained model without modifying the original parameters. We demonstrate that SeerAttention-R, trained on just 0.4B tokens, maintains near-lossless reasoning accuracy with 4K token budget in AIME benchmark under large sparse attention block sizes (64/128). Using TileLang, we develop a highly optimized sparse decoding kernel that achieves near-theoretical speedups of up to 9x over FlashAttention-3 on H100 GPU at 90% sparsity. Code is available at: https://github.com/microsoft/SeerAttention.
Truth in the Few: High-Value Data Selection for Efficient Multi-Modal Reasoning
Jun 05, 2025While multi-modal large language models (MLLMs) have made significant progress in complex reasoning tasks via reinforcement learning, it is commonly believed that extensive training data is necessary for improving multi-modal reasoning ability, inevitably leading to data redundancy and substantial computational costs. However, can smaller high-value datasets match or outperform full corpora for multi-modal reasoning in MLLMs? In this work, we challenge this assumption through a key observation: meaningful multi-modal reasoning is triggered by only a sparse subset of training samples, termed cognitive samples, whereas the majority contribute marginally. Building on this insight, we propose a novel data selection paradigm termed Reasoning Activation Potential (RAP), which identifies cognitive samples by estimating each sample's potential to stimulate genuine multi-modal reasoning by two complementary estimators: 1) Causal Discrepancy Estimator (CDE) based on the potential outcome model principle, eliminates samples that overly rely on language priors by comparing outputs between multi-modal and text-only inputs; 2) Attention Confidence Estimator (ACE), which exploits token-level self-attention to discard samples dominated by irrelevant but over-emphasized tokens in intermediate reasoning stages. Moreover, we introduce a Difficulty-aware Replacement Module (DRM) to substitute trivial instances with cognitively challenging ones, thereby ensuring complexity for robust multi-modal reasoning. Experiments on six datasets show that our RAP method consistently achieves superior performance using only 9.3% of the training data, while reducing computational costs by over 43%. Our code is available at https://github.com/Leo-ssl/RAP.
TableEval: A Real-World Benchmark for Complex, Multilingual, and Multi-Structured Table Question Answering
Jun 04, 2025LLMs have shown impressive progress in natural language processing. However, they still face significant challenges in TableQA, where real-world complexities such as diverse table structures, multilingual data, and domain-specific reasoning are crucial. Existing TableQA benchmarks are often limited by their focus on simple flat tables and suffer from data leakage. Furthermore, most benchmarks are monolingual and fail to capture the cross-lingual and cross-domain variability in practical applications. To address these limitations, we introduce TableEval, a new benchmark designed to evaluate LLMs on realistic TableQA tasks. Specifically, TableEval includes tables with various structures (such as concise, hierarchical, and nested tables) collected from four domains (including government, finance, academia, and industry reports). Besides, TableEval features cross-lingual scenarios with tables in Simplified Chinese, Traditional Chinese, and English. To minimize the risk of data leakage, we collect all data from recent real-world documents. Considering that existing TableQA metrics fail to capture semantic accuracy, we further propose SEAT, a new evaluation framework that assesses the alignment between model responses and reference answers at the sub-question level. Experimental results have shown that SEAT achieves high agreement with human judgment. Extensive experiments on TableEval reveal critical gaps in the ability of state-of-the-art LLMs to handle these complex, real-world TableQA tasks, offering insights for future improvements. We make our dataset available here: https://github.com/wenge-research/TableEval.
ChartMind: A Comprehensive Benchmark for Complex Real-world Multimodal Chart Question Answering
May 29, 2025Chart question answering (CQA) has become a critical multimodal task for evaluating the reasoning capabilities of vision-language models. While early approaches have shown promising performance by focusing on visual features or leveraging large-scale pre-training, most existing evaluations rely on rigid output formats and objective metrics, thus ignoring the complex, real-world demands of practical chart analysis. In this paper, we introduce ChartMind, a new benchmark designed for complex CQA tasks in real-world settings. ChartMind covers seven task categories, incorporates multilingual contexts, supports open-domain textual outputs, and accommodates diverse chart formats, bridging the gap between real-world applications and traditional academic benchmarks. Furthermore, we propose a context-aware yet model-agnostic framework, ChartLLM, that focuses on extracting key contextual elements, reducing noise, and enhancing the reasoning accuracy of multimodal large language models. Extensive evaluations on ChartMind and three representative public benchmarks with 14 mainstream multimodal models show our framework significantly outperforms the previous three common CQA paradigms: instruction-following, OCR-enhanced, and chain-of-thought, highlighting the importance of flexible chart understanding for real-world CQA. These findings suggest new directions for developing more robust chart reasoning in future research.