 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-Driven Scenario-Aware Planning for Autonomous Driving
Jan 29, 2026Hybrid planner switching framework (HPSF) for autonomous driving needs to reconcile high-speed driving efficiency with safe maneuvering in dense traffic. Existing HPSF methods often fail to make reliable mode transitions or sustain efficient driving in congested environments, owing to heuristic scene recognition and low-frequency control updates. To address the limitation, this paper proposes LAP, a large language model (LLM) driven, adaptive planning method, which switches between high-speed driving in low-complexity scenes and precise driving in high-complexity scenes, enabling high qualities of trajectory generation through confined gaps. This is achieved by leveraging LLM for scene understanding and integrating its inference into the joint optimization of mode configuration and motion planning. The joint optimization is solved using tree-search model predictive control and alternating minimization. We implement LAP by Python in Robot Operating System (ROS). High-fidelity simulation results show that the proposed LAP outperforms other benchmarks in terms of both driving time and success rate.
Representation Entanglement for Generation:Training Diffusion Transformers Is Much Easier Than You Think
Jul 02, 2025
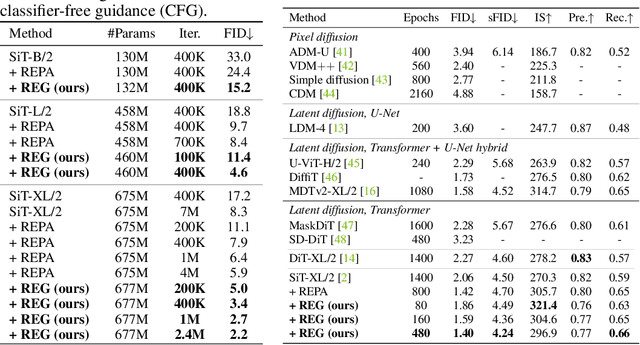
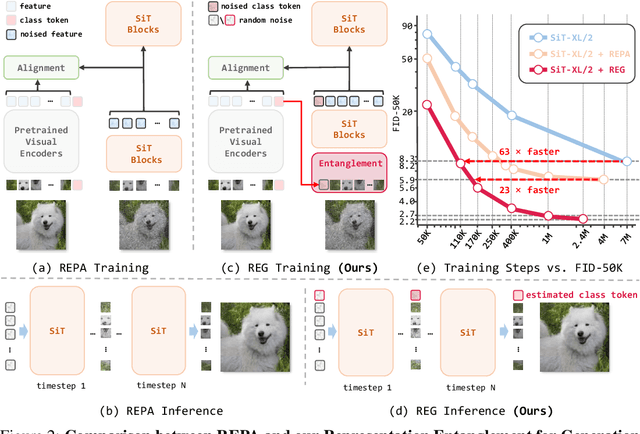
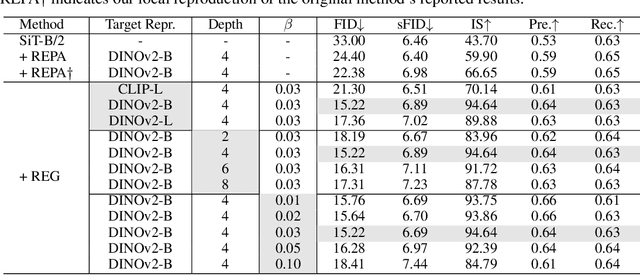
REPA and its variants effectively mitigate training challenges in diffusion models by incorporating external visual representations from pretrained models, through alignment between the noisy hidden projections of denoising networks and foundational clean image representations. We argue that the external alignment, which is absent during the entire denoising inference process, falls short of fully harnessing the potential of discriminative representations. In this work, we propose a straightforward method called Representation Entanglement for Generation (REG), which entangles low-level image latents with a single high-level class token from pretrained foundation models for denoising. REG acquires the capability to produce coherent image-class pairs directly from pure noise, substantially improving both generation quality and training efficiency. This is accomplished with negligible additional inference overhead, requiring only one single additional token for denoising (<0.5\% increase in FLOPs and latency). The inference process concurrently reconstructs both image latents and their corresponding global semantics, where the acquired semantic knowledge actively guides and enhances the image generation process. On ImageNet 256$\times$256, SiT-XL/2 + REG demonstrates remarkable convergence acceleration, achieving $\textbf{63}\times$ and $\textbf{23}\times$ faster training than SiT-XL/2 and SiT-XL/2 + REPA, respectively. More impressively, SiT-L/2 + REG trained for merely 400K iterations outperforms SiT-XL/2 + REPA trained for 4M iterations ($\textbf{10}\times$ longer). Code is available at: https://github.com/Martinser/REG.
Asymmetric Decision-Making in Online Knowledge Distillation:Unifying Consensus and Divergence
Mar 09, 2025



Online Knowledge Distillation (OKD) methods streamline the distillation training process into a single stage, eliminating the need for knowledge transfer from a pretrained teacher network to a more compact student network. This paper presents an innovative approach to leverage intermediate spatial representations. Our analysis of the intermediate features from both teacher and student models reveals two pivotal insights: (1) the similar features between students and teachers are predominantly focused on foreground objects. (2) teacher models emphasize foreground objects more than students. Building on these findings, we propose Asymmetric Decision-Making (ADM) to enhance feature consensus learning for student models while continuously promoting feature diversity in teacher models. Specifically, Consensus Learning for student models prioritizes spatial features with high consensus relative to teacher models. Conversely, Divergence Learning for teacher models highlights spatial features with lower similarity compared to student models, indicating superior performance by teacher models in these regions. Consequently, ADM facilitates the student models to catch up with the feature learning process of the teacher models. Extensive experiments demonstrate that ADM consistently surpasses existing OKD methods across various online knowledge distillation settings and also achieves superior results when applied to offline knowledge distillation, semantic segmentation and diffusion distillation tasks.
LEDiT: Your Length-Extrapolatable Diffusion Transformer without Positional Encoding
Mar 07, 2025

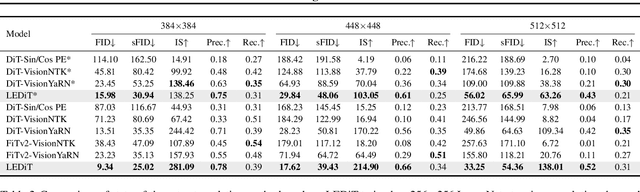

Diffusion transformers(DiTs) struggle to generate images at resolutions higher than their training resolutions. The primary obstacle is that the explicit positional encodings(PE), such as RoPE, need extrapolation which degrades performance when the inference resolution differs from training. In this paper, we propose a Length-Extrapolatable Diffusion Transformer(LEDiT), a simple yet powerful architecture to overcome this limitation. LEDiT needs no explicit PEs, thereby avoiding extrapolation. The key innovations of LEDiT are introducing causal attention to implicitly impart global positional information to tokens, while enhancing locality to precisely distinguish adjacent tokens. Experiments on 256x256 and 512x512 ImageNet show that LEDiT can scale the inference resolution to 512x512 and 1024x1024, respectively, while achieving better image quality compared to current state-of-the-art length extrapolation methods(NTK-aware, YaRN). Moreover, LEDiT achieves strong extrapolation performance with just 100K steps of fine-tuning on a pretrained DiT, demonstrating its potential for integration into existing text-to-image DiTs. Project page: https://shenzhang2145.github.io/ledit/
Cascade Prompt Learning for Vision-Language Model Adaptation
Sep 26, 2024



Prompt learning has surfaced as an effective approach to enhance the performance of Vision-Language Models (VLMs) like CLIP when applied to downstream tasks. However, current learnable prompt tokens are primarily used for the single phase of adapting to tasks (i.e., adapting prompt), easily leading to overfitting risks. In this work, we propose a novel Cascade Prompt Learning CasPL framework to enable prompt learning to serve both generic and specific expertise (i.e., boosting and adapting prompt) simultaneously. Specifically, CasPL is a new learning paradigm comprising two distinct phases of learnable prompts: the first boosting prompt is crafted to extract domain-general knowledge from a senior larger CLIP teacher model by aligning their predicted logits using extensive unlabeled domain images. The second adapting prompt is then cascaded with the frozen first set to fine-tune the downstream tasks, following the approaches employed in prior research. In this manner, CasPL can effectively capture both domain-general and task-specific representations into explicitly different gradual groups of prompts, thus potentially alleviating overfitting issues in the target domain. It's worth noting that CasPL serves as a plug-and-play module that can seamlessly integrate into any existing prompt learning approach. CasPL achieves a significantly better balance between performance and inference speed, which is especially beneficial for deploying smaller VLM models in resource-constrained environments. Compared to the previous state-of-the-art method PromptSRC, CasPL shows an average improvement of 1.85% for base classes, 3.44% for novel classes, and 2.72% for the harmonic mean over 11 image classification datasets. Code is publicly available at: https://github.com/megvii-research/CasPL.
Revisiting Prompt Pretraining of Vision-Language Models
Sep 10, 2024



Prompt learning is an effective method to customize Vision-Language Models (VLMs) for various downstream tasks, involving tuning very few parameters of input prompt tokens. Recently, prompt pretraining in large-scale dataset (e.g., ImageNet-21K) has played a crucial role in prompt learning for universal visual discrimination. However, we revisit and observe that the limited learnable prompts could face underfitting risks given the extensive images during prompt pretraining, simultaneously leading to poor generalization. To address the above issues, in this paper, we propose a general framework termed Revisiting Prompt Pretraining (RPP), which targets at improving the fitting and generalization ability from two aspects: prompt structure and prompt supervision. For prompt structure, we break the restriction in common practice where query, key, and value vectors are derived from the shared learnable prompt token. Instead, we introduce unshared individual query, key, and value learnable prompts, thereby enhancing the model's fitting capacity through increased parameter diversity. For prompt supervision, we additionally utilize soft labels derived from zero-shot probability predictions provided by a pretrained Contrastive Language Image Pretraining (CLIP) teacher model. These soft labels yield more nuanced and general insights into the inter-class relationships, thereby endowing the pretraining process with better generalization ability. RPP produces a more resilient prompt initialization, enhancing its robust transferability across diverse visual recognition tasks. Experiments across various benchmarks consistently confirm the state-of-the-art (SOTA) performance of our pretrained prompts. Codes and models will be made available soon.
HiDiffusion: Unlocking High-Resolution Creativity and Efficiency in Low-Resolution Trained Diffusion Models
Nov 29, 2023We introduce HiDiffusion, a tuning-free framework comprised of Resolution-Aware U-Net (RAU-Net) and Modified Shifted Window Multi-head Self-Attention (MSW-MSA) to enable pretrained large text-to-image diffusion models to efficiently generate high-resolution images (e.g. 1024$\times$1024) that surpass the training image resolution. Pretrained diffusion models encounter unreasonable object duplication in generating images beyond the training image resolution. We attribute it to the mismatch between the feature map size of high-resolution images and the receptive field of U-Net's convolution. To address this issue, we propose a simple yet scalable method named RAU-Net. RAU-Net dynamically adjusts the feature map size to match the convolution's receptive field in the deep block of U-Net. Another obstacle in high-resolution synthesis is the slow inference speed of U-Net. Our observations reveal that the global self-attention in the top block, which exhibits locality, however, consumes the majority of computational resources. To tackle this issue, we propose MSW-MSA. Unlike previous window attention mechanisms, our method uses a much larger window size and dynamically shifts windows to better accommodate diffusion models. Extensive experiments demonstrate that our HiDiffusion can scale diffusion models to generate 1024$\times$1024, 2048$\times$2048, or even 4096$\times$4096 resolution images, while simultaneously reducing inference time by 40\%-60\%, achieving state-of-the-art performance on high-resolution image synthesis. The most significant revelation of our work is that a pretrained diffusion model on low-resolution images is scalable for high-resolution generation without further tuning. We hope this revelation can provide insights for future research on the scalability of diffusion models.
Boosting Semi-Supervised Learning by Exploiting All Unlabeled Data
Mar 20, 2023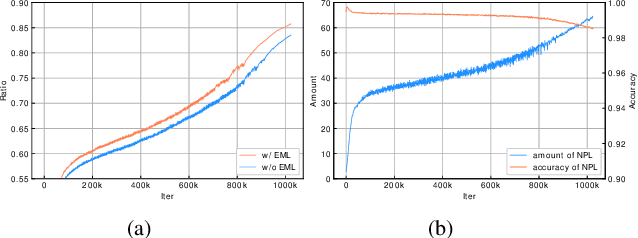
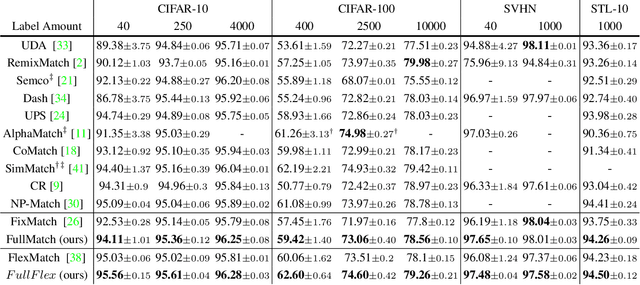
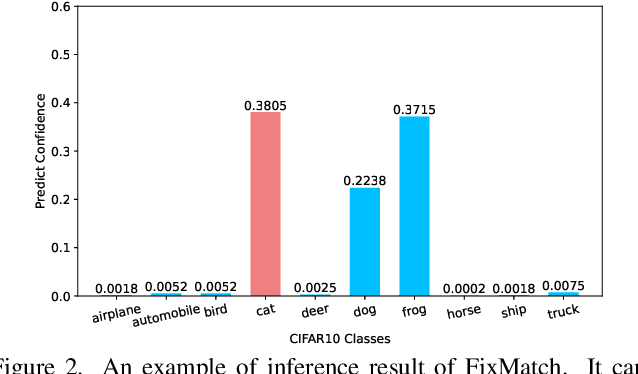
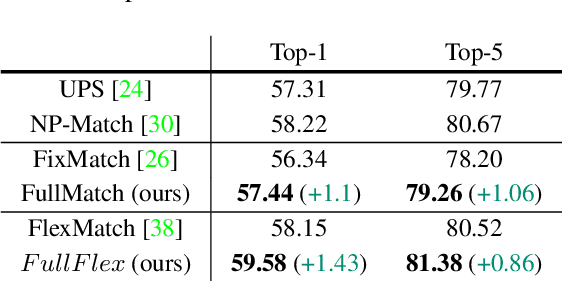
Semi-supervised learning (SSL) has attracted enormous attention due to its vast potential of mitigating the dependence on large labeled datasets. The latest methods (e.g., FixMatch) use a combination of consistency regularization and pseudo-labeling to achieve remarkable successes. However, these methods all suffer from the waste of complicated examples since all pseudo-labels have to be selected by a high threshold to filter out noisy ones. Hence, the examples with ambiguous predictions will not contribute to the training phase. For better leveraging all unlabeled examples, we propose two novel techniques: Entropy Meaning Loss (EML) and Adaptive Negative Learning (ANL). EML incorporates the prediction distribution of non-target classes into the optimization objective to avoid competition with target class, and thus generating more high-confidence predictions for selecting pseudo-label. ANL introduces the additional negative pseudo-label for all unlabeled data to leverage low-confidence examples. It adaptively allocates this label by dynamically evaluating the top-k performance of the model. EML and ANL do not introduce any additional parameter and hyperparameter. We integrate these techniques with FixMatch, and develop a simple yet powerful framework called FullMatch. Extensive experiments on several common SSL benchmarks (CIFAR-10/100, SVHN, STL-10 and ImageNet) demonstrate that FullMatch exceeds FixMatch by a large margin. Integrated with FlexMatch (an advanced FixMatch-based framework), we achieve state-of-the-art performance. Source code is at https://github.com/megvii-research/FullMatch.
GeoGCN: Geometric Dual-domain Graph Convolution Network for Point Cloud Denoising
Oct 28, 2022We propose GeoGCN, a novel geometric dual-domain graph convolution network for point cloud denoising (PCD). Beyond the traditional wisdom of PCD, to fully exploit the geometric information of point clouds, we define two kinds of surface normals, one is called Real Normal (RN), and the other is Virtual Normal (VN). RN preserves the local details of noisy point clouds while VN avoids the global shape shrinkage during denoising. GeoGCN is a new PCD paradigm that, 1) first regresses point positions by spatialbased GCN with the help of VNs, 2) then estimates initial RNs by performing Principal Component Analysis on the regressed points, and 3) finally regresses fine RNs by normalbased GCN. Unlike existing PCD methods, GeoGCN not only exploits two kinds of geometry expertise (i.e., RN and VN) but also benefits from training data. Experiments validate that GeoGCN outperforms SOTAs in terms of both noise-robustness and local-and-global feature preservation.
Lane Detection in Low-light Conditions Using an Efficient Data Enhancement : Light Conditions Style Transfer
Feb 04, 2020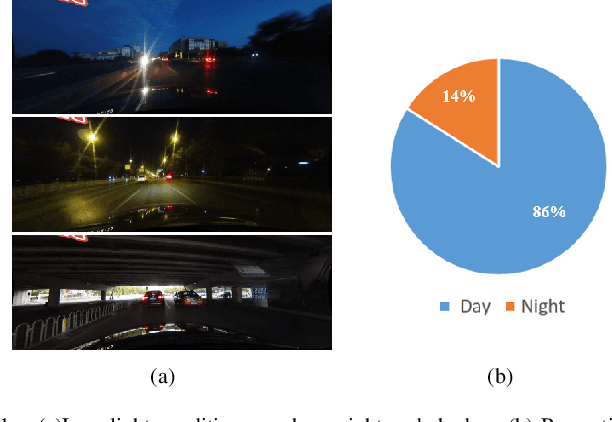

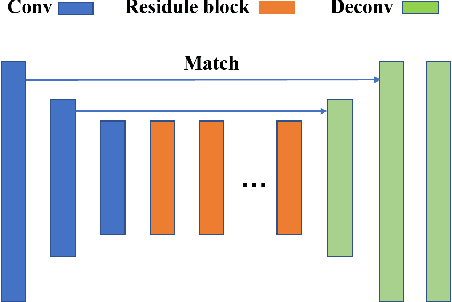

Nowadays, deep learning techniques are widely used for lane detection, but application in low-light conditions remains a challenge until this day. Although multi-task learning and contextual information based methods have been proposed to solve the problem, they either require additional manual annotations or introduce extra inference computation respectively. In this paper, we propose a style-transfer-based data enhancement method, which uses Generative Adversarial Networks (GANs) to generate images in low-light conditions, that increases the environmental adaptability of the lane detector. Our solution consists of three models: the proposed Better-CycleGAN, light conditions style transfer network and lane detection network. It does not require additional manual annotations nor extra inference computation. We validated our methods on the lane detection benchmark CULane using ERFNet. Empirically, lane detection model trained using our method demonstrated adaptability in low-light conditions and robustness in complex scenarios. Our code for this paper will be publicly available.