 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEncore: Conditioning Trajectory Forecasting via Biased Ego Rehearsals
May 12, 2026Learning and representing the subjectivities of agents has become a challenging but crucial problem in the trajectory prediction task. Such subjectivities not only present specific spatial or temporal structures, but also are anisotropic for all interaction participants. Despite great efforts, it remains difficult to explicitly learn and forecast these subjectivities, let alone further modulate models' predictions through a specific ego's subjectivity. Inspired by prefactual thoughts in psychology and relevant theatrical concepts, we interpret such subjectivities in future trajectories as the continuous process from rehearsal to encore. In the rehearsal phase, the proposed ego predictor focuses on how each ego agent learns to derive and direct a set of explicitly biased rehearsal trajectories for all participants in the scene from the short-term observations. Then, these rehearsal trajectories serve as immediate controls to condition final predictions, providing direct yet distinct ego biases for the prediction network to simulate agents' various subjectivities. Experiments across datasets not only demonstrate a consistent improvement in the performance of the proposed \emph{Encore} trajectory prediction model but also provide clear interpretability regarding subjectivities as biased ego rehearsals.
Stealthy and Adjustable Text-Guided Backdoor Attacks on Multimodal Pretrained Models
Apr 07, 2026Multimodal pretrained models are vulnerable to backdoor attacks, yet most existing methods rely on visual or multimodal triggers, which are impractical since visually embedded triggers rarely occur in real-world data. To overcome this limitation, we propose a novel Text-Guided Backdoor (TGB) attack on multimodal pretrained models, where commonly occurring words in textual descriptions serve as backdoor triggers, significantly improving stealthiness and practicality. Furthermore, we introduce visual adversarial perturbations on poisoned samples to modulate the model's learning of textual triggers, enabling a controllable and adjustable TGB attack. Extensive experiments on downstream tasks built upon multimodal pretrained models, including Composed Image Retrieval (CIR) and Visual Question Answering (VQA), demonstrate that TGB achieves practicality and stealthiness with adjustable attack success rates across diverse realistic settings, revealing critical security vulnerabilities in multimodal pretrained models.
WRF4CIR: Weight-Regularized Fine-Tuning Network for Composed Image Retrieval
Apr 07, 2026Composed Image Retrieval (CIR) task aims to retrieve target images based on reference images and modification texts. Current CIR methods primarily rely on fine-tuning vision-language pre-trained models. However, we find that these approaches commonly suffer from severe overfitting, posing challenges for CIR with limited triplet data. To better understand this issue, we present a systematic study of overfitting in VLP-based CIR, revealing a significant and previously overlooked generalization gap across different models and datasets. Motivated by these findings, we introduce WRF4CIR, a Weight-Regularized Fine-tuning network for CIR. Specifically, during the fine-tuning process, we apply adversarial perturbations to the model weights for regularization, where these perturbations are generated in the opposite direction of gradient descent. Intuitively, WRF4CIR increases the difficulty of fitting the training data, which helps mitigate overfitting in CIR under limited triplet supervision. Extensive experiments on benchmark datasets demonstrate that WRF4CIR significantly narrows the generalization gap and achieves substantial improvements over existing methods.
Mutually Causal Semantic Distillation Network for Zero-Shot Learning
Mar 18, 2026Zero-shot learning (ZSL) aims to recognize the unseen classes in the open-world guided by the side-information (e.g., attributes). Its key task is how to infer the latent semantic knowledge between visual and attribute features on seen classes, and thus conducting a desirable semantic knowledge transfer from seen classes to unseen ones. Prior works simply utilize unidirectional attention within a weakly-supervised manner to learn the spurious and limited latent semantic representations, which fail to effectively discover the intrinsic semantic knowledge (e.g., attribute semantic) between visual and attribute features. To solve the above challenges, we propose a mutually causal semantic distillation network (termed MSDN++) to distill the intrinsic and sufficient semantic representations for ZSL. MSDN++ consists of an attribute$\rightarrow$visual causal attention sub-net that learns attribute-based visual features, and a visual$\rightarrow$attribute causal attention sub-net that learns visual-based attribute features. The causal attentions encourages the two sub-nets to learn causal vision-attribute associations for representing reliable features with causal visual/attribute learning. With the guidance of semantic distillation loss, the two mutual attention sub-nets learn collaboratively and teach each other throughout the training process. Extensive experiments on three widely-used benchmark datasets (e.g., CUB, SUN, AWA2, and FLO) show that our MSDN++ yields significant improvements over the strong baselines, leading to new state-of-the-art performances.
VII: Visual Instruction Injection for Jailbreaking Image-to-Video Generation Models
Feb 24, 2026Image-to-Video (I2V) generation models, which condition video generation on reference images, have shown emerging visual instruction-following capability, allowing certain visual cues in reference images to act as implicit control signals for video generation. However, this capability also introduces a previously overlooked risk: adversaries may exploit visual instructions to inject malicious intent through the image modality. In this work, we uncover this risk by proposing Visual Instruction Injection (VII), a training-free and transferable jailbreaking framework that intentionally disguises the malicious intent of unsafe text prompts as benign visual instructions in the safe reference image. Specifically, VII coordinates a Malicious Intent Reprogramming module to distill malicious intent from unsafe text prompts while minimizing their static harmfulness, and a Visual Instruction Grounding module to ground the distilled intent onto a safe input image by rendering visual instructions that preserve semantic consistency with the original unsafe text prompt, thereby inducing harmful content during I2V generation. Empirically, our extensive experiments on four state-of-the-art commercial I2V models (Kling-v2.5-turbo, Gemini Veo-3.1, Seedance-1.5-pro, and PixVerse-V5) demonstrate that VII achieves Attack Success Rates of up to 83.5% while reducing Refusal Rates to near zero, significantly outperforming existing baselines.
Reverberation: Learning the Latencies Before Forecasting Trajectories
Nov 14, 2025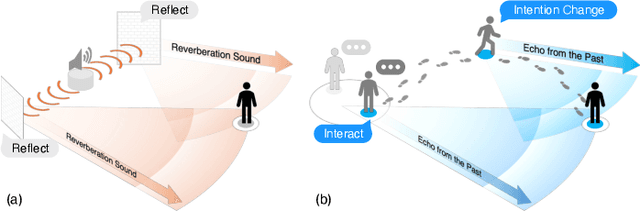
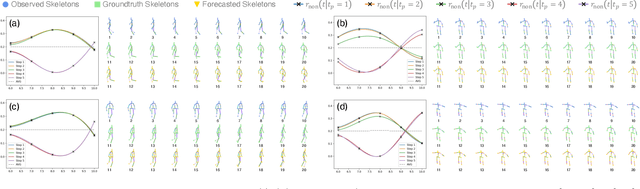
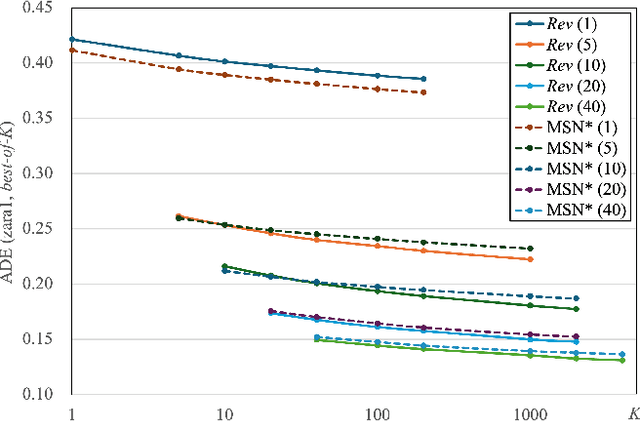
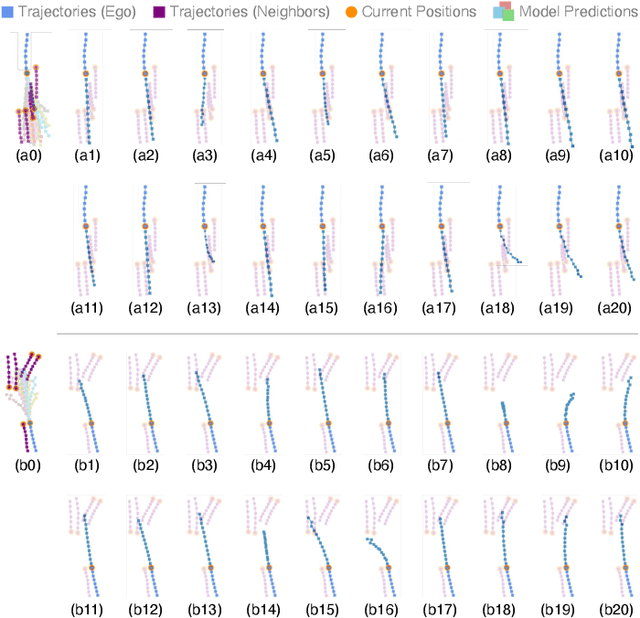
Bridging the past to the future, connecting agents both spatially and temporally, lies at the core of the trajectory prediction task. Despite great efforts, it remains challenging to explicitly learn and predict latencies, the temporal delays with which agents respond to different trajectory-changing events and adjust their future paths, whether on their own or interactively. Different agents may exhibit distinct latency preferences for noticing, processing, and reacting to any specific trajectory-changing event. The lack of consideration of such latencies may undermine the causal continuity of the forecasting system and also lead to implausible or unintended trajectories. Inspired by the reverberation curves in acoustics, we propose a new reverberation transform and the corresponding Reverberation (short for Rev) trajectory prediction model, which simulates and predicts different latency preferences of each agent as well as their stochasticity by using two explicit and learnable reverberation kernels, allowing for the controllable trajectory prediction based on these forecasted latencies. Experiments on multiple datasets, whether pedestrians or vehicles, demonstrate that Rev achieves competitive accuracy while revealing interpretable latency dynamics across agents and scenarios. Qualitative analyses further verify the properties of the proposed reverberation transform, highlighting its potential as a general latency modeling approach.
Prototype-Guided Curriculum Learning for Zero-Shot Learning
Aug 11, 2025In Zero-Shot Learning (ZSL), embedding-based methods enable knowledge transfer from seen to unseen classes by learning a visual-semantic mapping from seen-class images to class-level semantic prototypes (e.g., attributes). However, these semantic prototypes are manually defined and may introduce noisy supervision for two main reasons: (i) instance-level mismatch: variations in perspective, occlusion, and annotation bias will cause discrepancies between individual sample and the class-level semantic prototypes; and (ii) class-level imprecision: the manually defined semantic prototypes may not accurately reflect the true semantics of the class. Consequently, the visual-semantic mapping will be misled, reducing the effectiveness of knowledge transfer to unseen classes. In this work, we propose a prototype-guided curriculum learning framework (dubbed as CLZSL), which mitigates instance-level mismatches through a Prototype-Guided Curriculum Learning (PCL) module and addresses class-level imprecision via a Prototype Update (PUP) module. Specifically, the PCL module prioritizes samples with high cosine similarity between their visual mappings and the class-level semantic prototypes, and progressively advances to less-aligned samples, thereby reducing the interference of instance-level mismatches to achieve accurate visual-semantic mapping. Besides, the PUP module dynamically updates the class-level semantic prototypes by leveraging the visual mappings learned from instances, thereby reducing class-level imprecision and further improving the visual-semantic mapping. Experiments were conducted on standard benchmark datasets-AWA2, SUN, and CUB-to verify the effectiveness of our method.
Toward Realistic Camouflaged Object Detection: Benchmarks and Method
Jan 13, 2025



Camouflaged object detection (COD) primarily relies on semantic or instance segmentation methods. While these methods have made significant advancements in identifying the contours of camouflaged objects, they may be inefficient or cost-effective for tasks that only require the specific location of the object. Object detection algorithms offer an optimized solution for Realistic Camouflaged Object Detection (RCOD) in such cases. However, detecting camouflaged objects remains a formidable challenge due to the high degree of similarity between the features of the objects and their backgrounds. Unlike segmentation methods that perform pixel-wise comparisons to differentiate between foreground and background, object detectors omit this analysis, further aggravating the challenge. To solve this problem, we propose a camouflage-aware feature refinement (CAFR) strategy. Since camouflaged objects are not rare categories, CAFR fully utilizes a clear perception of the current object within the prior knowledge of large models to assist detectors in deeply understanding the distinctions between background and foreground. Specifically, in CAFR, we introduce the Adaptive Gradient Propagation (AGP) module that fine-tunes all feature extractor layers in large detection models to fully refine class-specific features from camouflaged contexts. We then design the Sparse Feature Refinement (SFR) module that optimizes the transformer-based feature extractor to focus primarily on capturing class-specific features in camouflaged scenarios. To facilitate the assessment of RCOD tasks, we manually annotate the labels required for detection on three existing segmentation COD datasets, creating a new benchmark for RCOD tasks. Code and datasets are available at: https://github.com/zhimengXin/RCOD.
Discriminative Image Generation with Diffusion Models for Zero-Shot Learning
Dec 23, 2024



Generative Zero-Shot Learning (ZSL) methods synthesize class-related features based on predefined class semantic prototypes, showcasing superior performance. However, this feature generation paradigm falls short of providing interpretable insights. In addition, existing approaches rely on semantic prototypes annotated by human experts, which exhibit a significant limitation in their scalability to generalized scenes. To overcome these deficiencies, a natural solution is to generate images for unseen classes using text prompts. To this end, We present DIG-ZSL, a novel Discriminative Image Generation framework for Zero-Shot Learning. Specifically, to ensure the generation of discriminative images for training an effective ZSL classifier, we learn a discriminative class token (DCT) for each unseen class under the guidance of a pre-trained category discrimination model (CDM). Harnessing DCTs, we can generate diverse and high-quality images, which serve as informative unseen samples for ZSL tasks. In this paper, the extensive experiments and visualizations on four datasets show that our DIG-ZSL: (1) generates diverse and high-quality images, (2) outperforms previous state-of-the-art nonhuman-annotated semantic prototype-based methods by a large margin, and (3) achieves comparable or better performance than baselines that leverage human-annotated semantic prototypes. The codes will be made available upon acceptance of the paper.
Resonance: Learning to Predict Social-Aware Pedestrian Trajectories as Co-Vibrations
Dec 03, 2024



Learning to forecast the trajectories of intelligent agents like pedestrians has caught more researchers' attention. Despite researchers' efforts, it remains a challenge to accurately account for social interactions among agents when forecasting, and in particular, to simulate such social modifications to future trajectories in an explainable and decoupled way. Inspired by the resonance phenomenon of vibration systems, we propose the Resonance (short for Re) model to forecast pedestrian trajectories as co-vibrations, and regard that social interactions are associated with spectral properties of agents' trajectories. It forecasts future trajectories as three distinct vibration terms to represent agents' future plans from different perspectives in a decoupled way. Also, agents' social interactions and how they modify scheduled trajectories will be considered in a resonance-like manner by learning the similarities of their trajectory spectrums. Experiments on multiple datasets, whether pedestrian or vehicle, have verified the usefulness of our method both quantitatively and qualitatively.