 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhyAVBench: A Challenging Audio Physics-Sensitivity Benchmark for Physically Grounded Text-to-Audio-Video Generation
Dec 30, 2025Text-to-audio-video (T2AV) generation underpins a wide range of applications demanding realistic audio-visual content, including virtual reality, world modeling, gaming, and filmmaking. However, existing T2AV models remain incapable of generating physically plausible sounds, primarily due to their limited understanding of physical principles. To situate current research progress, we present PhyAVBench, a challenging audio physics-sensitivity benchmark designed to systematically evaluate the audio physics grounding capabilities of existing T2AV models. PhyAVBench comprises 1,000 groups of paired text prompts with controlled physical variables that implicitly induce sound variations, enabling a fine-grained assessment of models' sensitivity to changes in underlying acoustic conditions. We term this evaluation paradigm the Audio-Physics Sensitivity Test (APST). Unlike prior benchmarks that primarily focus on audio-video synchronization, PhyAVBench explicitly evaluates models' understanding of the physical mechanisms underlying sound generation, covering 6 major audio physics dimensions, 4 daily scenarios (music, sound effects, speech, and their mix), and 50 fine-grained test points, ranging from fundamental aspects such as sound diffraction to more complex phenomena, e.g., Helmholtz resonance. Each test point consists of multiple groups of paired prompts, where each prompt is grounded by at least 20 newly recorded or collected real-world videos, thereby minimizing the risk of data leakage during model pre-training. Both prompts and videos are iteratively refined through rigorous human-involved error correction and quality control to ensure high quality. We argue that only models with a genuine grasp of audio-related physical principles can generate physically consistent audio-visual content. We hope PhyAVBench will stimulate future progress in this critical yet largely unexplored domain.
HSA-Net: Hierarchical and Structure-Aware Framework for Efficient and Scalable Molecular Language Modeling
Aug 10, 2025Molecular representation learning, a cornerstone for downstream tasks like molecular captioning and molecular property prediction, heavily relies on Graph Neural Networks (GNN). However, GNN suffers from the over-smoothing problem, where node-level features collapse in deep GNN layers. While existing feature projection methods with cross-attention have been introduced to mitigate this issue, they still perform poorly in deep features. This motivated our exploration of using Mamba as an alternative projector for its ability to handle complex sequences. However, we observe that while Mamba excels at preserving global topological information from deep layers, it neglects fine-grained details in shallow layers. The capabilities of Mamba and cross-attention exhibit a global-local trade-off. To resolve this critical global-local trade-off, we propose Hierarchical and Structure-Aware Network (HSA-Net), a novel framework with two modules that enables a hierarchical feature projection and fusion. Firstly, a Hierarchical Adaptive Projector (HAP) module is introduced to process features from different graph layers. It learns to dynamically switch between a cross-attention projector for shallow layers and a structure-aware Graph-Mamba projector for deep layers, producing high-quality, multi-level features. Secondly, to adaptively merge these multi-level features, we design a Source-Aware Fusion (SAF) module, which flexibly selects fusion experts based on the characteristics of the aggregation features, ensuring a precise and effective final representation fusion. Extensive experiments demonstrate that our HSA-Net framework quantitatively and qualitatively outperforms current state-of-the-art (SOTA) methods.
A Comprehensive Survey on Human Video Generation: Challenges, Methods, and Insights
Jul 11, 2024



Human video generation is a dynamic and rapidly evolving task that aims to synthesize 2D human body video sequences with generative models given control conditions such as text, audio, and pose. With the potential for wide-ranging applications in film, gaming, and virtual communication, the ability to generate natural and realistic human video is critical. Recent advancements in generative models have laid a solid foundation for the growing interest in this area. Despite the significant progress, the task of human video generation remains challenging due to the consistency of characters, the complexity of human motion, and difficulties in their relationship with the environment. This survey provides a comprehensive review of the current state of human video generation, marking, to the best of our knowledge, the first extensive literature review in this domain. We start with an introduction to the fundamentals of human video generation and the evolution of generative models that have facilitated the field's growth. We then examine the main methods employed for three key sub-tasks within human video generation: text-driven, audio-driven, and pose-driven motion generation. These areas are explored concerning the conditions that guide the generation process. Furthermore, we offer a collection of the most commonly utilized datasets and the evaluation metrics that are crucial in assessing the quality and realism of generated videos. The survey concludes with a discussion of the current challenges in the field and suggests possible directions for future research. The goal of this survey is to offer the research community a clear and holistic view of the advancements in human video generation, highlighting the milestones achieved and the challenges that lie ahead.
Bridge to Non-Barrier Communication: Gloss-Prompted Fine-grained Cued Speech Gesture Generation with Diffusion Model
Apr 30, 2024Cued Speech (CS) is an advanced visual phonetic encoding system that integrates lip reading with hand codings, enabling people with hearing impairments to communicate efficiently. CS video generation aims to produce specific lip and gesture movements of CS from audio or text inputs. The main challenge is that given limited CS data, we strive to simultaneously generate fine-grained hand and finger movements, as well as lip movements, meanwhile the two kinds of movements need to be asynchronously aligned. Existing CS generation methods are fragile and prone to poor performance due to template-based statistical models and careful hand-crafted pre-processing to fit the models. Therefore, we propose a novel Gloss-prompted Diffusion-based CS Gesture generation framework (called GlossDiff). Specifically, to integrate additional linguistic rules knowledge into the model. we first introduce a bridging instruction called \textbf{Gloss}, which is an automatically generated descriptive text to establish a direct and more delicate semantic connection between spoken language and CS gestures. Moreover, we first suggest rhythm is an important paralinguistic feature for CS to improve the communication efficacy. Therefore, we propose a novel Audio-driven Rhythmic Module (ARM) to learn rhythm that matches audio speech. Moreover, in this work, we design, record, and publish the first Chinese CS dataset with four CS cuers. Extensive experiments demonstrate that our method quantitatively and qualitatively outperforms current state-of-the-art (SOTA) methods. We release the code and data at https://glossdiff.github.io/.
A Survey on Deep Multi-modal Learning for Body Language Recognition and Generation
Aug 17, 2023



Body language (BL) refers to the non-verbal communication expressed through physical movements, gestures, facial expressions, and postures. It is a form of communication that conveys information, emotions, attitudes, and intentions without the use of spoken or written words. It plays a crucial role in interpersonal interactions and can complement or even override verbal communication. Deep multi-modal learning techniques have shown promise in understanding and analyzing these diverse aspects of BL. The survey emphasizes their applications to BL generation and recognition. Several common BLs are considered i.e., Sign Language (SL), Cued Speech (CS), Co-speech (CoS), and Talking Head (TH), and we have conducted an analysis and established the connections among these four BL for the first time. Their generation and recognition often involve multi-modal approaches. Benchmark datasets for BL research are well collected and organized, along with the evaluation of SOTA methods on these datasets. The survey highlights challenges such as limited labeled data, multi-modal learning, and the need for domain adaptation to generalize models to unseen speakers or languages. Future research directions are presented, including exploring self-supervised learning techniques, integrating contextual information from other modalities, and exploiting large-scale pre-trained multi-modal models. In summary, this survey paper provides a comprehensive understanding of deep multi-modal learning for various BL generations and recognitions for the first time. By analyzing advancements, challenges, and future directions, it serves as a valuable resource for researchers and practitioners in advancing this field. n addition, we maintain a continuously updated paper list for deep multi-modal learning for BL recognition and generation: https://github.com/wentaoL86/awesome-body-language.
Spatio-Temporal Structure Consistency for Semi-supervised Medical Image Classification
Mar 03, 2023Intelligent medical diagnosis has shown remarkable progress based on the large-scale datasets with precise annotations. However, fewer labeled images are available due to significantly expensive cost for annotating data by experts. To fully exploit the easily available unlabeled data, we propose a novel Spatio-Temporal Structure Consistent (STSC) learning framework. Specifically, a gram matrix is derived to combine the spatial structure consistency and temporal structure consistency together. This gram matrix captures the structural similarity among the representations of different training samples. At the spatial level, our framework explicitly enforces the consistency of structural similarity among different samples under perturbations. At the temporal level, we consider the consistency of the structural similarity in different training iterations by digging out the stable sub-structures in a relation graph. Experiments on two medical image datasets (i.e., ISIC 2018 challenge and ChestX-ray14) show that our method outperforms state-of-the-art SSL methods. Furthermore, extensive qualitative analysis on the Gram matrices and heatmaps by Grad-CAM are presented to validate the effectiveness of our method.
Semi-Supervised Active Learning for COVID-19 Lung Ultrasound Multi-symptom Classification
Sep 09, 2020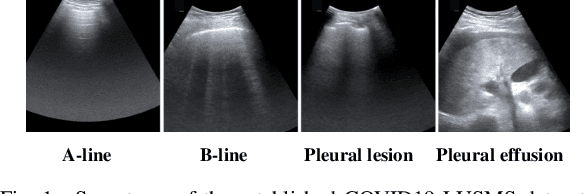
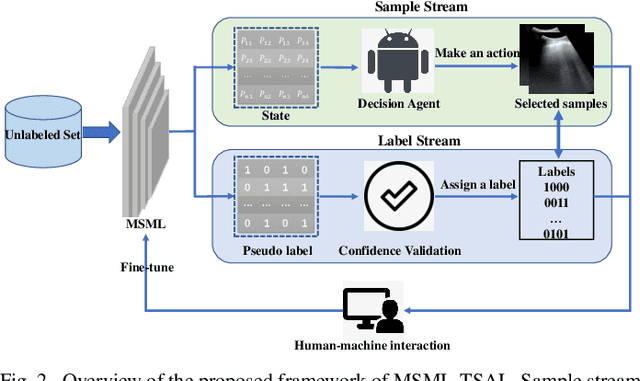
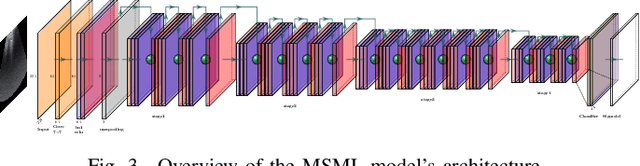
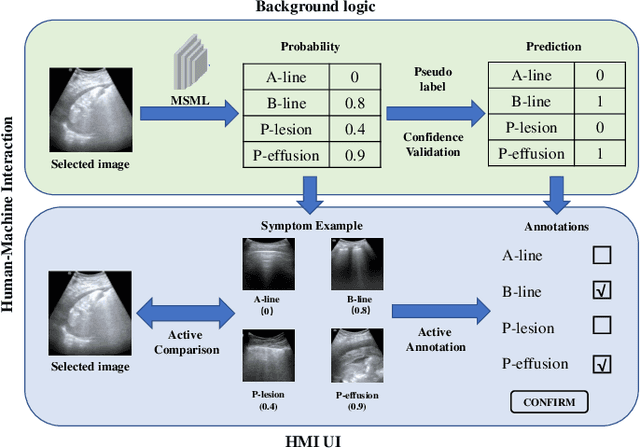
Ultrasound (US) is a non-invasive yet effective medical diagnostic imaging technique for the COVID-19 global pandemic. However, due to complex feature behaviors and expensive annotations of US images, it is difficult to apply Artificial Intelligence (AI) assisting approaches for lung's multi-symptom (multi-label) classification. To overcome these difficulties, we propose a novel semi-supervised Two-Stream Active Learning (TSAL) method to model complicated features and reduce labeling costs in an iterative procedure. The core component of TSAL is the multi-label learning mechanism, in which label correlations information is used to design multi-label margin (MLM) strategy and confidence validation for automatically selecting informative samples and confident labels. On this basis, a multi-symptom multi-label (MSML) classification network is proposed to learn discriminative features of lung symptoms, and a human-machine interaction is exploited to confirm the final annotations that are used to fine-tune MSML with progressively labeled data. Moreover, a novel lung US dataset named COVID19-LUSMS is built, currently containing 71 clinical patients with 6,836 images sampled from 678 videos. Experimental evaluations show that TSAL using only 20% data can achieve superior performance to the baseline and the state-of-the-art. Qualitatively, visualization of both attention map and sample distribution confirms the good consistency with the clinic knowledge.