 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing Chain-of-Thought Confidence via Topological and Dirichlet Risk Analysis
Nov 09, 2025



Chain-of-thought (CoT) prompting enables Large Language Models to solve complex problems, but deploying these models safely requires reliable confidence estimates, a capability where existing methods suffer from poor calibration and severe overconfidence on incorrect predictions. We propose Enhanced Dirichlet and Topology Risk (EDTR), a novel decoding strategy that combines topological analysis with Dirichlet-based uncertainty quantification to measure LLM confidence across multiple reasoning paths. EDTR treats each CoT as a vector in high-dimensional space and extracts eight topological risk features capturing the geometric structure of reasoning distributions: tighter, more coherent clusters indicate higher confidence while dispersed, inconsistent paths signal uncertainty. We evaluate EDTR against three state-of-the-art calibration methods across four diverse reasoning benchmarks spanning olympiad-level mathematics (AIME), grade school math (GSM8K), commonsense reasoning, and stock price prediction \cite{zhang2025aime, cobbe2021training, talmor-etal-2019-commonsenseqa, yahoo_finance}. EDTR achieves 41\% better calibration than competing methods with an average ECE of 0.287 and the best overall composite score of 0.672, while notably achieving perfect accuracy on AIME and exceptional calibration on GSM8K with an ECE of 0.107, domains where baselines exhibit severe overconfidence. Our work provides a geometric framework for understanding and quantifying uncertainty in multi-step LLM reasoning, enabling more reliable deployment where calibrated confidence estimates are essential.
Viser: Imperative, Web-based 3D Visualization in Python
Jul 30, 2025We present Viser, a 3D visualization library for computer vision and robotics. Viser aims to bring easy and extensible 3D visualization to Python: we provide a comprehensive set of 3D scene and 2D GUI primitives, which can be used independently with minimal setup or composed to build specialized interfaces. This technical report describes Viser's features, interface, and implementation. Key design choices include an imperative-style API and a web-based viewer, which improve compatibility with modern programming patterns and workflows.
Visual Imitation Enables Contextual Humanoid Control
May 07, 2025
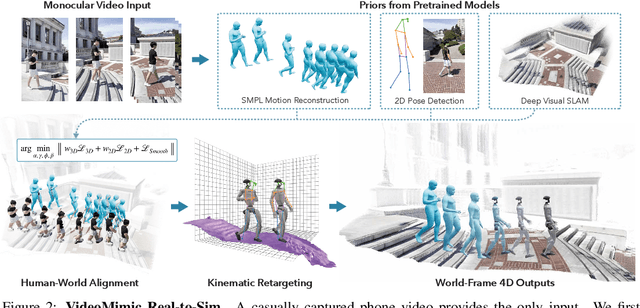


How can we teach humanoids to climb staircases and sit on chairs using the surrounding environment context? Arguably, the simplest way is to just show them-casually capture a human motion video and feed it to humanoids. We introduce VIDEOMIMIC, a real-to-sim-to-real pipeline that mines everyday videos, jointly reconstructs the humans and the environment, and produces whole-body control policies for humanoid robots that perform the corresponding skills. We demonstrate the results of our pipeline on real humanoid robots, showing robust, repeatable contextual control such as staircase ascents and descents, sitting and standing from chairs and benches, as well as other dynamic whole-body skills-all from a single policy, conditioned on the environment and global root commands. VIDEOMIMIC offers a scalable path towards teaching humanoids to operate in diverse real-world environments.
Predict-Optimize-Distill: A Self-Improving Cycle for 4D Object Understanding
Apr 24, 2025Humans can resort to long-form inspection to build intuition on predicting the 3D configurations of unseen objects. The more we observe the object motion, the better we get at predicting its 3D state immediately. Existing systems either optimize underlying representations from multi-view observations or train a feed-forward predictor from supervised datasets. We introduce Predict-Optimize-Distill (POD), a self-improving framework that interleaves prediction and optimization in a mutually reinforcing cycle to achieve better 4D object understanding with increasing observation time. Given a multi-view object scan and a long-form monocular video of human-object interaction, POD iteratively trains a neural network to predict local part poses from RGB frames, uses this predictor to initialize a global optimization which refines output poses through inverse rendering, then finally distills the results of optimization back into the model by generating synthetic self-labeled training data from novel viewpoints. Each iteration improves both the predictive model and the optimized motion trajectory, creating a virtuous cycle that bootstraps its own training data to learn about the pose configurations of an object. We also introduce a quasi-multiview mining strategy for reducing depth ambiguity by leveraging long video. We evaluate POD on 14 real-world and 5 synthetic objects with various joint types, including revolute and prismatic joints as well as multi-body configurations where parts detach or reattach independently. POD demonstrates significant improvement over a pure optimization baseline which gets stuck in local minima, particularly for longer videos. We also find that POD's performance improves with both video length and successive iterations of the self-improving cycle, highlighting its ability to scale performance with additional observations and looped refinement.
Reconstructing People, Places, and Cameras
Dec 23, 2024



We present "Humans and Structure from Motion" (HSfM), a method for jointly reconstructing multiple human meshes, scene point clouds, and camera parameters in a metric world coordinate system from a sparse set of uncalibrated multi-view images featuring people. Our approach combines data-driven scene reconstruction with the traditional Structure-from-Motion (SfM) framework to achieve more accurate scene reconstruction and camera estimation, while simultaneously recovering human meshes. In contrast to existing scene reconstruction and SfM methods that lack metric scale information, our method estimates approximate metric scale by leveraging a human statistical model. Furthermore, it reconstructs multiple human meshes within the same world coordinate system alongside the scene point cloud, effectively capturing spatial relationships among individuals and their positions in the environment. We initialize the reconstruction of humans, scenes, and cameras using robust foundational models and jointly optimize these elements. This joint optimization synergistically improves the accuracy of each component. We compare our method to existing approaches on two challenging benchmarks, EgoHumans and EgoExo4D, demonstrating significant improvements in human localization accuracy within the world coordinate frame (reducing error from 3.51m to 1.04m in EgoHumans and from 2.9m to 0.56m in EgoExo4D). Notably, our results show that incorporating human data into the SfM pipeline improves camera pose estimation (e.g., increasing RRA@15 by 20.3% on EgoHumans). Additionally, qualitative results show that our approach improves overall scene reconstruction quality. Our code is available at: muelea.github.io/hsfm.
Inducing Positive Perspectives with Text Reframing
Apr 06, 2022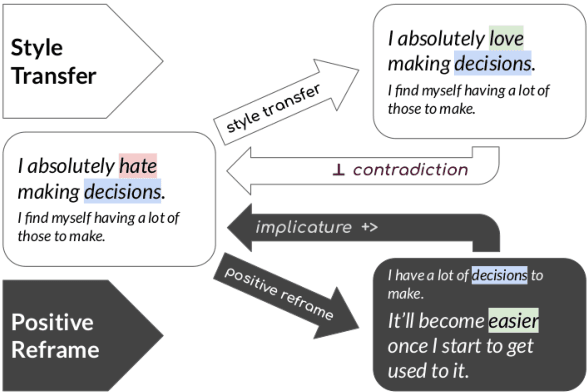
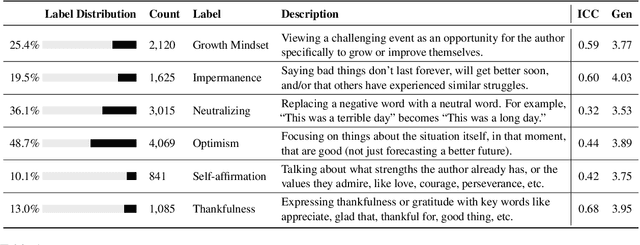
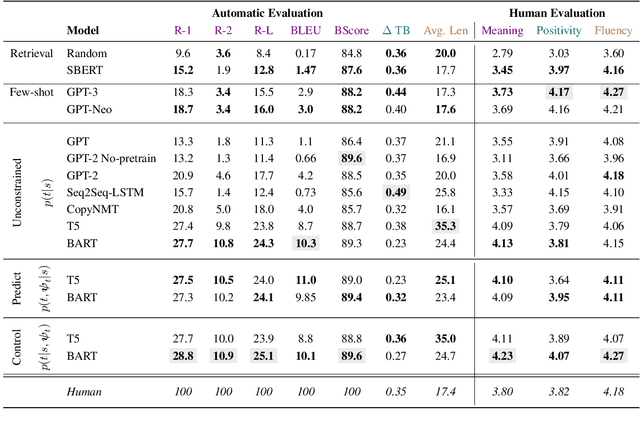
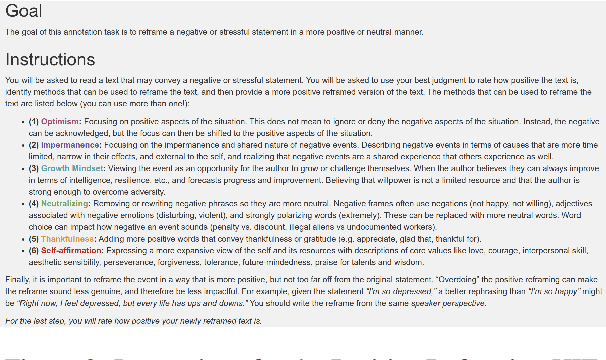
Sentiment transfer is one popular example of a text style transfer task, where the goal is to reverse the sentiment polarity of a text. With a sentiment reversal comes also a reversal in meaning. We introduce a different but related task called positive reframing in which we neutralize a negative point of view and generate a more positive perspective for the author without contradicting the original meaning. Our insistence on meaning preservation makes positive reframing a challenging and semantically rich task. To facilitate rapid progress, we introduce a large-scale benchmark, Positive Psychology Frames, with 8,349 sentence pairs and 12,755 structured annotations to explain positive reframing in terms of six theoretically-motivated reframing strategies. Then we evaluate a set of state-of-the-art text style transfer models, and conclude by discussing key challenges and directions for future work.