 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoV3D: Grounding Cognitive Prognosis Reasoning in Longitudinal 3D Brain MRI via Regional Volume Assessments
Mar 14, 2026Longitudinal brain MRI is essential for characterizing the progression of neurological diseases such as Alzheimer's disease assessment. However, current deep-learning tools fragment this process: classifiers reduce a scan to a label, volumetric pipelines produce uninterpreted measurements, and vision-language models (VLMs) may generate fluent but potentially hallucinated conclusions. We present LoV3D, a pipeline for training 3D vision-language models, which reads longitudinal T1-weighted brain MRI, produces a region-level anatomical assessment, conducts longitudinal comparison with the prior scan, and finally outputs a three-class diagnosis (Cognitively Normal, Mild Cognitive Impairment, or Dementia) along with a synthesized diagnostic summary. The stepped pipeline grounds the final diagnosis by enforcing label consistency, longitudinal coherence, and biological plausibility, thereby reducing the risks of hallucinations. The training process introduces a clinically-weighted Verifier that scores candidate outputs automatically against normative references derived from standardized volume metrics, driving Direct Preference Optimization without a single human annotation. On a subject-level held-out ADNI test set (479 scans, 258 subjects), LoV3D achieves 93.7% three-class diagnostic accuracy (+34.8% over the no-grounding baseline), 97.2% on two-class diagnosis accuracy (+4% over the SOTA) and 82.6% region-level anatomical classification accuracy (+33.1% over VLM baselines). Zero-shot transfer yields 95.4% on MIRIAD (100% Dementia recall) and 82.9% three-class accuracy on AIBL, confirming high generalizability across sites, scanners, and populations. Code is available at https://github.com/Anonymous-TEVC/LoV-3D.
Finite Difference Flow Optimization for RL Post-Training of Text-to-Image Models
Mar 13, 2026Reinforcement learning (RL) has become a standard technique for post-training diffusion-based image synthesis models, as it enables learning from reward signals to explicitly improve desirable aspects such as image quality and prompt alignment. In this paper, we propose an online RL variant that reduces the variance in the model updates by sampling paired trajectories and pulling the flow velocity in the direction of the more favorable image. Unlike existing methods that treat each sampling step as a separate policy action, we consider the entire sampling process as a single action. We experiment with both high-quality vision language models and off-the-shelf quality metrics for rewards, and evaluate the outputs using a broad set of metrics. Our method converges faster and yields higher output quality and prompt alignment than previous approaches.
Paper Title: LoV3D: Grounding Cognitive Prognosis Reasoning in Longitudinal 3D Brain MRI via Regional Volume Assessments
Mar 12, 2026Longitudinal brain MRI is essential for characterizing the progression of neurological diseases such as Alzheimer's disease assessment. However, current deep-learning tools fragment this process: classifiers reduce a scan to a label, volumetric pipelines produce uninterpreted measurements, and vision-language models (VLMs) may generate fluent but potentially hallucinated conclusions. We present LoV3D, a pipeline for training 3D vision-language models, which reads longitudinal T1-weighted brain MRI, produces a region-level anatomical assessment, conducts longitudinal comparison with the prior scan, and finally outputs a three-class diagnosis (Cognitively Normal, Mild Cognitive Impairment, or Dementia) along with a synthesized diagnostic summary. The stepped pipeline grounds the final diagnosis by enforcing label consistency, longitudinal coherence, and biological plausibility, thereby reducing the risks of hallucinations. The training process introduces a clinically-weighted Verifier that scores candidate outputs automatically against normative references derived from standardized volume metrics, driving Direct Preference Optimization without a single human annotation. On a subject-level held-out ADNI test set (479 scans, 258 subjects), LoV3D achieves 93.7% three-class diagnostic accuracy (+34.8% over the no-grounding baseline), 97.2% on two-class diagnosis accuracy (+4% over the SOTA) and 82.6% region-level anatomical classification accuracy (+33.1% over VLM baselines). Zero-shot transfer yields 95.4% on MIRIAD (100% Dementia recall) and 82.9% three-class accuracy on AIBL, confirming high generalizability across sites, scanners, and populations. Code is available at https://github.com/Anonymous-TEVC/LoV-3D.
Flow Matching Policy Gradients
Jul 28, 2025Flow-based generative models, including diffusion models, excel at modeling continuous distributions in high-dimensional spaces. In this work, we introduce Flow Policy Optimization (FPO), a simple on-policy reinforcement learning algorithm that brings flow matching into the policy gradient framework. FPO casts policy optimization as maximizing an advantage-weighted ratio computed from the conditional flow matching loss, in a manner compatible with the popular PPO-clip framework. It sidesteps the need for exact likelihood computation while preserving the generative capabilities of flow-based models. Unlike prior approaches for diffusion-based reinforcement learning that bind training to a specific sampling method, FPO is agnostic to the choice of diffusion or flow integration at both training and inference time. We show that FPO can train diffusion-style policies from scratch in a variety of continuous control tasks. We find that flow-based models can capture multimodal action distributions and achieve higher performance than Gaussian policies, particularly in under-conditioned settings.
Visual Imitation Enables Contextual Humanoid Control
May 07, 2025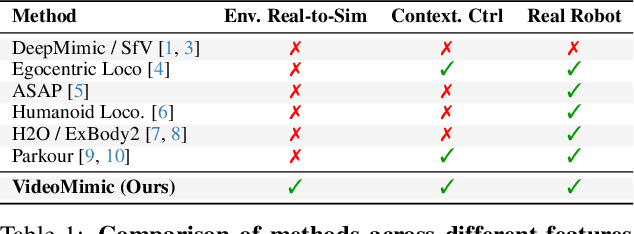
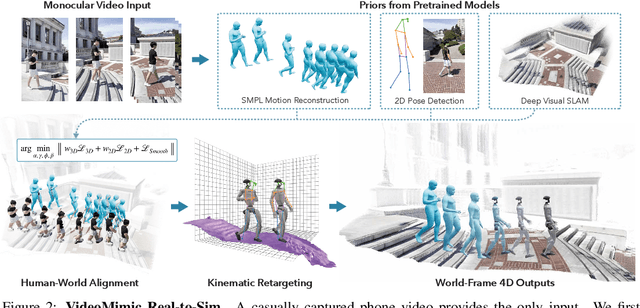


How can we teach humanoids to climb staircases and sit on chairs using the surrounding environment context? Arguably, the simplest way is to just show them-casually capture a human motion video and feed it to humanoids. We introduce VIDEOMIMIC, a real-to-sim-to-real pipeline that mines everyday videos, jointly reconstructs the humans and the environment, and produces whole-body control policies for humanoid robots that perform the corresponding skills. We demonstrate the results of our pipeline on real humanoid robots, showing robust, repeatable contextual control such as staircase ascents and descents, sitting and standing from chairs and benches, as well as other dynamic whole-body skills-all from a single policy, conditioned on the environment and global root commands. VIDEOMIMIC offers a scalable path towards teaching humanoids to operate in diverse real-world environments.
Decentralized Diffusion Models
Jan 10, 2025Large-scale AI model training divides work across thousands of GPUs, then synchronizes gradients across them at each step. This incurs a significant network burden that only centralized, monolithic clusters can support, driving up infrastructure costs and straining power systems. We propose Decentralized Diffusion Models, a scalable framework for distributing diffusion model training across independent clusters or datacenters by eliminating the dependence on a centralized, high-bandwidth networking fabric. Our method trains a set of expert diffusion models over partitions of the dataset, each in full isolation from one another. At inference time, the experts ensemble through a lightweight router. We show that the ensemble collectively optimizes the same objective as a single model trained over the whole dataset. This means we can divide the training burden among a number of "compute islands," lowering infrastructure costs and improving resilience to localized GPU failures. Decentralized diffusion models empower researchers to take advantage of smaller, more cost-effective and more readily available compute like on-demand GPU nodes rather than central integrated systems. We conduct extensive experiments on ImageNet and LAION Aesthetics, showing that decentralized diffusion models FLOP-for-FLOP outperform standard diffusion models. We finally scale our approach to 24 billion parameters, demonstrating that high-quality diffusion models can now be trained with just eight individual GPU nodes in less than a week.
Rethinking Score Distillation as a Bridge Between Image Distributions
Jun 13, 2024



Score distillation sampling (SDS) has proven to be an important tool, enabling the use of large-scale diffusion priors for tasks operating in data-poor domains. Unfortunately, SDS has a number of characteristic artifacts that limit its usefulness in general-purpose applications. In this paper, we make progress toward understanding the behavior of SDS and its variants by viewing them as solving an optimal-cost transport path from a source distribution to a target distribution. Under this new interpretation, these methods seek to transport corrupted images (source) to the natural image distribution (target). We argue that current methods' characteristic artifacts are caused by (1) linear approximation of the optimal path and (2) poor estimates of the source distribution. We show that calibrating the text conditioning of the source distribution can produce high-quality generation and translation results with little extra overhead. Our method can be easily applied across many domains, matching or beating the performance of specialized methods. We demonstrate its utility in text-to-2D, text-based NeRF optimization, translating paintings to real images, optical illusion generation, and 3D sketch-to-real. We compare our method to existing approaches for score distillation sampling and show that it can produce high-frequency details with realistic colors.
Nerfstudio: A Modular Framework for Neural Radiance Field Development
Feb 08, 2023



Neural Radiance Fields (NeRF) are a rapidly growing area of research with wide-ranging applications in computer vision, graphics, robotics, and more. In order to streamline the development and deployment of NeRF research, we propose a modular PyTorch framework, Nerfstudio. Our framework includes plug-and-play components for implementing NeRF-based methods, which make it easy for researchers and practitioners to incorporate NeRF into their projects. Additionally, the modular design enables support for extensive real-time visualization tools, streamlined pipelines for importing captured in-the-wild data, and tools for exporting to video, point cloud and mesh representations. The modularity of Nerfstudio enables the development of Nerfacto, our method that combines components from recent papers to achieve a balance between speed and quality, while also remaining flexible to future modifications. To promote community-driven development, all associated code and data are made publicly available with open-source licensing at https://nerf.studio.