 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInductive Subgraphs as Shortcuts: Causal Disentanglement for Heterophilic Graph Learning
Apr 21, 2026Heterophily is a prevalent property of real-world graphs and is well known to impair the performance of homophilic Graph Neural Networks (GNNs). Prior work has attempted to adapt GNNs to heterophilic graphs through non-local neighbor extension or architecture refinement. However, the fundamental reasons behind misclassifications remain poorly understood. In this work, we take a novel perspective by examining recurring inductive subgraphs, empirically and theoretically showing that they act as spurious shortcuts that mislead GNNs and reinforce non-causal correlations in heterophilic graphs. To address this, we adopt a causal inference perspective to analyze and correct the biased learning behavior induced by shortcut inductive subgraphs. We propose a debiased causal graph that explicitly blocks confounding and spillover paths responsible for these shortcuts. Guided by this causal graph, we introduce Causal Disentangled GNN (CD-GNN), a principled framework that disentangles spurious inductive subgraphs from true causal subgraphs by explicitly blocking non-causal paths. By focusing on genuine causal signals, CD-GNN substantially improves the robustness and accuracy of node classification in heterophilic graphs. Extensive experiments on real-world datasets not only validate our theoretical findings but also demonstrate that our proposed CD-GNN outperforms state-of-the-art heterophily-aware baselines.
* SIGIR 2026
DyMRL: Dynamic Multispace Representation Learning for Multimodal Event Forecasting in Knowledge Graph
Mar 25, 2026Accurate representation of multimodal knowledge is crucial for event forecasting in real-world scenarios. However, existing studies have largely focused on static settings, overlooking the dynamic acquisition and fusion of multimodal knowledge. 1) At the knowledge acquisition level, how to learn time-sensitive information of different modalities, especially the dynamic structural modality. Existing dynamic learning methods are often limited to shallow structures across heterogeneous spaces or simple unispaces, making it difficult to capture deep relation-aware geometric features. 2) At the knowledge fusion level, how to learn evolving multimodal fusion features. Existing knowledge fusion methods based on static coattention struggle to capture the varying historical contributions of different modalities to future events. To this end, we propose DyMRL, a Dynamic Multispace Representation Learning approach to efficiently acquire and fuse multimodal temporal knowledge. 1) For the former issue, DyMRL integrates time-specific structural features from Euclidean, hyperbolic, and complex spaces into a relational message-passing framework to learn deep representations, reflecting human intelligences in associative thinking, high-order abstracting, and logical reasoning. Pretrained models endow DyMRL with time-sensitive visual and linguistic intelligences. 2) For the latter concern, DyMRL incorporates advanced dual fusion-evolution attention mechanisms that assign dynamic learning emphases equally to different modalities at different timestamps in a symmetric manner. To evaluate DyMRL's event forecasting performance through leveraging its learned multimodal temporal knowledge in history, we construct four multimodal temporal knowledge graph benchmarks. Extensive experiments demonstrate that DyMRL outperforms state-of-the-art dynamic unimodal and static multimodal baseline methods.
CoCR-RAG: Enhancing Retrieval-Augmented Generation in Web Q&A via Concept-oriented Context Reconstruction
Mar 25, 2026Retrieval-augmented generation (RAG) has shown promising results in enhancing Q&A by incorporating information from the web and other external sources. However, the supporting documents retrieved from the heterogeneous web often originate from multiple sources with diverse writing styles, varying formats, and inconsistent granularity. Fusing such multi-source documents into a coherent and knowledge-intensive context remains a significant challenge, as the presence of irrelevant and redundant information can compromise the factual consistency of the inferred answers. This paper proposes the Concept-oriented Context Reconstruction RAG (CoCR-RAG), a framework that addresses the multi-source information fusion problem in RAG through linguistically grounded concept-level integration. Specifically, we introduce a concept distillation algorithm that extracts essential concepts from Abstract Meaning Representation (AMR), a stable semantic representation that structures the meaning of texts as logical graphs. The distilled concepts from multiple retrieved documents are then fused and reconstructed into a unified, information-intensive context by Large Language Models, which supplement only the necessary sentence elements to highlight the core knowledge. Experiments on the PopQA and EntityQuestions datasets demonstrate that CoCR-RAG significantly outperforms existing context-reconstruction methods across these Web Q&A benchmarks. Furthermore, CoCR-RAG shows robustness across various backbone LLMs, establishing itself as a flexible, plug-and-play component adaptable to different RAG frameworks.
Debiasing Sequential Recommendation with Time-aware Inverse Propensity Scoring
Mar 05, 2026Sequential Recommendation (SR) predicts users next interactions by modeling the temporal order of their historical behaviors. Existing approaches, including traditional sequential models and generative recommenders, achieve strong performance but primarily rely on explicit interactions such as clicks or purchases while overlooking item exposures. This ignorance introduces selection bias, where exposed but unclicked items are misinterpreted as disinterest, and exposure bias, where unexposed items are treated as irrelevant. Effectively addressing these biases requires distinguishing between items that were "not exposed" and those that were "not of interest", which cannot be reliably inferred from correlations in historical data. Counterfactual reasoning provides a natural solution by estimating user preferences under hypothetical exposure, and Inverse Propensity Scoring (IPS) is a common tool for such estimation. However, conventional IPS methods are static and fail to capture the sequential dependencies and temporal dynamics of user behavior. To overcome these limitations, we propose Time aware Inverse Propensity Scoring (TIPS). Unlike traditional static IPS, TIPS effectively accounts for sequential dependencies and temporal dynamics, thereby capturing user preferences more accurately. Extensive experiments show that TIPS consistently enhances recommendation performance as a plug-in for various sequential recommenders. Our code will be publicly available upon acceptance.
CASTLE: A Comprehensive Benchmark for Evaluating Student-Tailored Personalized Safety in Large Language Models
Feb 05, 2026Large language models (LLMs) have advanced the development of personalized learning in education. However, their inherent generation mechanisms often produce homogeneous responses to identical prompts. This one-size-fits-all mechanism overlooks the substantial heterogeneity in students cognitive and psychological, thereby posing potential safety risks to vulnerable groups. Existing safety evaluations primarily rely on context-independent metrics such as factual accuracy, bias, or toxicity, which fail to capture the divergent harms that the same response might cause across different student attributes. To address this gap, we propose the concept of Student-Tailored Personalized Safety and construct CASTLE based on educational theories. This benchmark covers 15 educational safety risks and 14 student attributes, comprising 92,908 bilingual scenarios. We further design three evaluation metrics: Risk Sensitivity, measuring the model ability to detect risks; Emotional Empathy, evaluating the model capacity to recognize student states; and Student Alignment, assessing the match between model responses and student attributes. Experiments on 18 SOTA LLMs demonstrate that CASTLE poses a significant challenge: all models scored below an average safety rating of 2.3 out of 5, indicating substantial deficiencies in personalized safety assurance.
Towards Comprehensive Stage-wise Benchmarking of Large Language Models in Fact-Checking
Jan 06, 2026Large Language Models (LLMs) are increasingly deployed in real-world fact-checking systems, yet existing evaluations focus predominantly on claim verification and overlook the broader fact-checking workflow, including claim extraction and evidence retrieval. This narrow focus prevents current benchmarks from revealing systematic reasoning failures, factual blind spots, and robustness limitations of modern LLMs. To bridge this gap, we present FactArena, a fully automated arena-style evaluation framework that conducts comprehensive, stage-wise benchmarking of LLMs across the complete fact-checking pipeline. FactArena integrates three key components: (i) an LLM-driven fact-checking process that standardizes claim decomposition, evidence retrieval via tool-augmented interactions, and justification-based verdict prediction; (ii) an arena-styled judgment mechanism guided by consolidated reference guidelines to ensure unbiased and consistent pairwise comparisons across heterogeneous judge agents; and (iii) an arena-driven claim-evolution module that adaptively generates more challenging and semantically controlled claims to probe LLMs' factual robustness beyond fixed seed data. Across 16 state-of-the-art LLMs spanning seven model families, FactArena produces stable and interpretable rankings. Our analyses further reveal significant discrepancies between static claim-verification accuracy and end-to-end fact-checking competence, highlighting the necessity of holistic evaluation. The proposed framework offers a scalable and trustworthy paradigm for diagnosing LLMs' factual reasoning, guiding future model development, and advancing the reliable deployment of LLMs in safety-critical fact-checking applications.
Listwise Preference Alignment Optimization for Tail Item Recommendation
Jul 03, 2025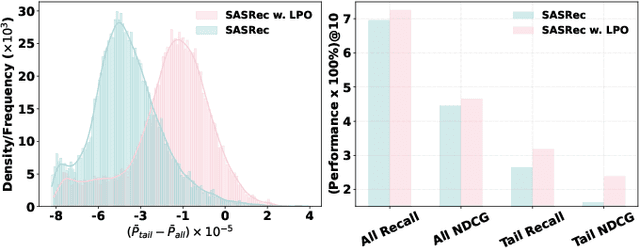
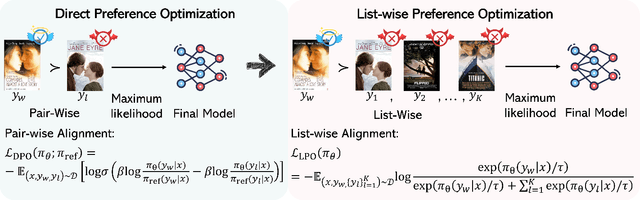
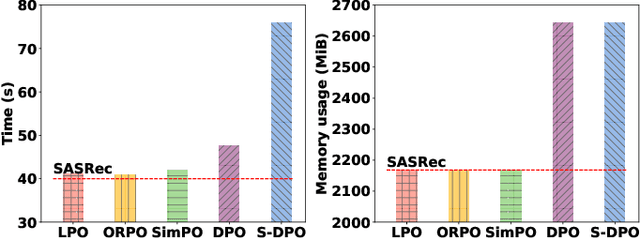
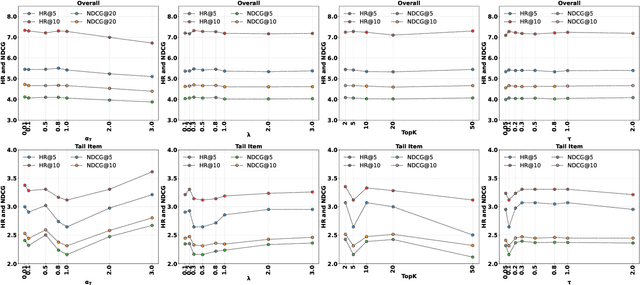
Preference alignment has achieved greater success on Large Language Models (LLMs) and drawn broad interest in recommendation research. Existing preference alignment methods for recommendation either require explicit reward modeling or only support pairwise preference comparison. The former directly increases substantial computational costs, while the latter hinders training efficiency on negative samples. Moreover, no existing effort has explored preference alignment solutions for tail-item recommendation. To bridge the above gaps, we propose LPO4Rec, which extends the Bradley-Terry model from pairwise comparison to listwise comparison, to improve the efficiency of model training. Specifically, we derive a closed form optimal policy to enable more efficient and effective training without explicit reward modeling. We also present an adaptive negative sampling and reweighting strategy to prioritize tail items during optimization and enhance performance in tail-item recommendations. Besides, we theoretically prove that optimizing the listwise preference optimization (LPO) loss is equivalent to maximizing the upper bound of the optimal reward. Our experiments on three public datasets show that our method outperforms 10 baselines by a large margin, achieving up to 50% performance improvement while reducing 17.9% GPU memory usage when compared with direct preference optimization (DPO) in tail-item recommendation. Our code is available at https://github.com/Yuhanleeee/LPO4Rec.
A Comprehensive Survey of Knowledge-Based Vision Question Answering Systems: The Lifecycle of Knowledge in Visual Reasoning Task
Apr 24, 2025Knowledge-based Vision Question Answering (KB-VQA) extends general Vision Question Answering (VQA) by not only requiring the understanding of visual and textual inputs but also extensive range of knowledge, enabling significant advancements across various real-world applications. KB-VQA introduces unique challenges, including the alignment of heterogeneous information from diverse modalities and sources, the retrieval of relevant knowledge from noisy or large-scale repositories, and the execution of complex reasoning to infer answers from the combined context. With the advancement of Large Language Models (LLMs), KB-VQA systems have also undergone a notable transformation, where LLMs serve as powerful knowledge repositories, retrieval-augmented generators and strong reasoners. Despite substantial progress, no comprehensive survey currently exists that systematically organizes and reviews the existing KB-VQA methods. This survey aims to fill this gap by establishing a structured taxonomy of KB-VQA approaches, and categorizing the systems into main stages: knowledge representation, knowledge retrieval, and knowledge reasoning. By exploring various knowledge integration techniques and identifying persistent challenges, this work also outlines promising future research directions, providing a foundation for advancing KB-VQA models and their applications.
UniRVQA: A Unified Framework for Retrieval-Augmented Vision Question Answering via Self-Reflective Joint Training
Apr 05, 2025



Knowledge-based Vision Question Answering (KB-VQA) systems address complex visual-grounded questions requiring external knowledge, such as web-sourced encyclopedia articles. Existing methods often use sequential and separate frameworks for the retriever and the generator with limited parametric knowledge sharing. However, since both retrieval and generation tasks require accurate understanding of contextual and external information, such separation can potentially lead to suboptimal system performance. Another key challenge is the integration of multimodal information. General-purpose multimodal pre-trained models, while adept at multimodal representation learning, struggle with fine-grained retrieval required for knowledge-intensive visual questions. Recent specialized pre-trained models mitigate the issue, but are computationally expensive. To bridge the gap, we propose a Unified Retrieval-Augmented VQA framework (UniRVQA). UniRVQA adapts general multimodal pre-trained models for fine-grained knowledge-intensive tasks within a unified framework, enabling cross-task parametric knowledge sharing and the extension of existing multimodal representation learning capability. We further introduce a reflective-answering mechanism that allows the model to explicitly evaluate and refine its knowledge boundary. Additionally, we integrate late interaction into the retrieval-augmented generation joint training process to enhance fine-grained understanding of queries and documents. Our approach achieves competitive performance against state-of-the-art models, delivering a significant 4.7% improvement in answering accuracy, and brings an average 7.5% boost in base MLLMs' VQA performance.
Is LLMs Hallucination Usable? LLM-based Negative Reasoning for Fake News Detection
Mar 12, 2025The questionable responses caused by knowledge hallucination may lead to LLMs' unstable ability in decision-making. However, it has never been investigated whether the LLMs' hallucination is possibly usable to generate negative reasoning for facilitating the detection of fake news. This study proposes a novel supervised self-reinforced reasoning rectification approach - SR$^3$ that yields both common reasonable reasoning and wrong understandings (negative reasoning) for news via LLMs reflection for semantic consistency learning. Upon that, we construct a negative reasoning-based news learning model called - \emph{NRFE}, which leverages positive or negative news-reasoning pairs for learning the semantic consistency between them. To avoid the impact of label-implicated reasoning, we deploy a student model - \emph{NRFE-D} that only takes news content as input to inspect the performance of our method by distilling the knowledge from \emph{NRFE}. The experimental results verified on three popular fake news datasets demonstrate the superiority of our method compared with three kinds of baselines including prompting on LLMs, fine-tuning on pre-trained SLMs, and other representative fake news detection methods.