 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNumina-Lean-Agent: An Open and General Agentic Reasoning System for Formal Mathematics
Jan 20, 2026Agentic systems have recently become the dominant paradigm for formal theorem proving, achieving strong performance by coordinating multiple models and tools. However, existing approaches often rely on task-specific pipelines and trained formal provers, limiting their flexibility and reproducibility. In this paper, we propose the paradigm that directly uses a general coding agent as a formal math reasoner. This paradigm is motivated by (1) A general coding agent provides a natural interface for diverse reasoning tasks beyond proving, (2) Performance can be improved by simply replacing the underlying base model, without training, and (3) MCP enables flexible extension and autonomous calling of specialized tools, avoiding complex design. Based on this paradigm, we introduce Numina-Lean-Agent, which combines Claude Code with Numina-Lean-MCP to enable autonomous interaction with Lean, retrieval of relevant theorems, informal proving and auxiliary reasoning tools. Using Claude Opus 4.5 as the base model, Numina-Lean-Agent solves all problems in Putnam 2025 (12 / 12), matching the best closed-source system. Beyond benchmark evaluation, we further demonstrate its generality by interacting with mathematicians to successfully formalize the Brascamp-Lieb theorem. We release Numina-Lean-Agent and all solutions at https://github.com/project-numina/numina-lean-agent.
TeleWorld: Towards Dynamic Multimodal Synthesis with a 4D World Model
Dec 31, 2025World models aim to endow AI systems with the ability to represent, generate, and interact with dynamic environments in a coherent and temporally consistent manner. While recent video generation models have demonstrated impressive visual quality, they remain limited in real-time interaction, long-horizon consistency, and persistent memory of dynamic scenes, hindering their evolution into practical world models. In this report, we present TeleWorld, a real-time multimodal 4D world modeling framework that unifies video generation, dynamic scene reconstruction, and long-term world memory within a closed-loop system. TeleWorld introduces a novel generation-reconstruction-guidance paradigm, where generated video streams are continuously reconstructed into a dynamic 4D spatio-temporal representation, which in turn guides subsequent generation to maintain spatial, temporal, and physical consistency. To support long-horizon generation with low latency, we employ an autoregressive diffusion-based video model enhanced with Macro-from-Micro Planning (MMPL)--a hierarchical planning method that reduces error accumulation from frame-level to segment-level-alongside efficient Distribution Matching Distillation (DMD), enabling real-time synthesis under practical computational budgets. Our approach achieves seamless integration of dynamic object modeling and static scene representation within a unified 4D framework, advancing world models toward practical, interactive, and computationally accessible systems. Extensive experiments demonstrate that TeleWorld achieves strong performance in both static and dynamic world understanding, long-term consistency, and real-time generation efficiency, positioning it as a practical step toward interactive, memory-enabled world models for multimodal generation and embodied intelligence.
See More, Change Less: Anatomy-Aware Diffusion for Contrast Enhancement
Dec 08, 2025Image enhancement improves visual quality and helps reveal details that are hard to see in the original image. In medical imaging, it can support clinical decision-making, but current models often over-edit. This can distort organs, create false findings, and miss small tumors because these models do not understand anatomy or contrast dynamics. We propose SMILE, an anatomy-aware diffusion model that learns how organs are shaped and how they take up contrast. It enhances only clinically relevant regions while leaving all other areas unchanged. SMILE introduces three key ideas: (1) structure-aware supervision that follows true organ boundaries and contrast patterns; (2) registration-free learning that works directly with unaligned multi-phase CT scans; (3) unified inference that provides fast and consistent enhancement across all contrast phases. Across six external datasets, SMILE outperforms existing methods in image quality (14.2% higher SSIM, 20.6% higher PSNR, 50% better FID) and in clinical usefulness by producing anatomically accurate and diagnostically meaningful images. SMILE also improves cancer detection from non-contrast CT, raising the F1 score by up to 10 percent.
TempoMaster: Efficient Long Video Generation via Next-Frame-Rate Prediction
Nov 16, 2025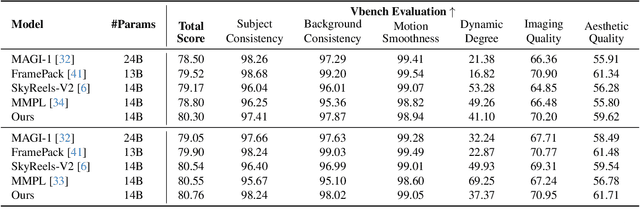
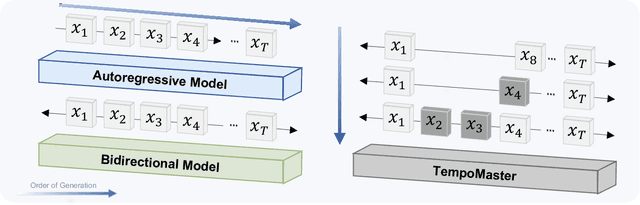
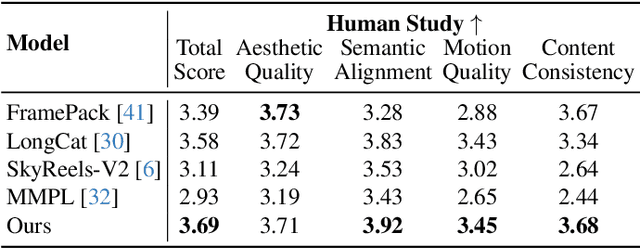
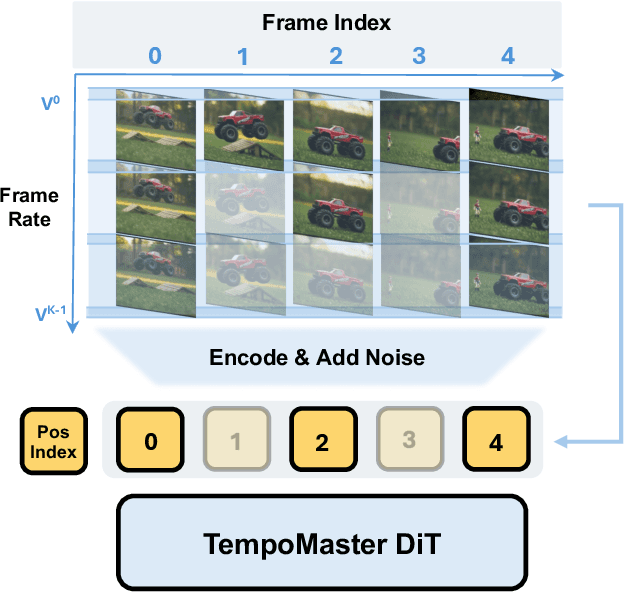
We present TempoMaster, a novel framework that formulates long video generation as next-frame-rate prediction. Specifically, we first generate a low-frame-rate clip that serves as a coarse blueprint of the entire video sequence, and then progressively increase the frame rate to refine visual details and motion continuity. During generation, TempoMaster employs bidirectional attention within each frame-rate level while performing autoregression across frame rates, thus achieving long-range temporal coherence while enabling efficient and parallel synthesis. Extensive experiments demonstrate that TempoMaster establishes a new state-of-the-art in long video generation, excelling in both visual and temporal quality.
LeanGeo: Formalizing Competitional Geometry problems in Lean
Aug 20, 2025



Geometry problems are a crucial testbed for AI reasoning capabilities. Most existing geometry solving systems cannot express problems within a unified framework, thus are difficult to integrate with other mathematical fields. Besides, since most geometric proofs rely on intuitive diagrams, verifying geometry problems is particularly challenging. To address these gaps, we introduce LeanGeo, a unified formal system for formalizing and solving competition-level geometry problems within the Lean 4 theorem prover. LeanGeo features a comprehensive library of high-level geometric theorems with Lean's foundational logic, enabling rigorous proof verification and seamless integration with Mathlib. We also present LeanGeo-Bench, a formal geometry benchmark in LeanGeo, comprising problems from the International Mathematical Olympiad (IMO) and other advanced sources. Our evaluation demonstrates the capabilities and limitations of state-of-the-art Large Language Models on this benchmark, highlighting the need for further advancements in automated geometric reasoning. We open source the theorem library and the benchmark of LeanGeo at https://github.com/project-numina/LeanGeo/tree/master.
Kimi K2: Open Agentic Intelligence
Jul 28, 2025



We introduce Kimi K2, a Mixture-of-Experts (MoE) large language model with 32 billion activated parameters and 1 trillion total parameters. We propose the MuonClip optimizer, which improves upon Muon with a novel QK-clip technique to address training instability while enjoying the advanced token efficiency of Muon. Based on MuonClip, K2 was pre-trained on 15.5 trillion tokens with zero loss spike. During post-training, K2 undergoes a multi-stage post-training process, highlighted by a large-scale agentic data synthesis pipeline and a joint reinforcement learning (RL) stage, where the model improves its capabilities through interactions with real and synthetic environments. Kimi K2 achieves state-of-the-art performance among open-source non-thinking models, with strengths in agentic capabilities. Notably, K2 obtains 66.1 on Tau2-Bench, 76.5 on ACEBench (En), 65.8 on SWE-Bench Verified, and 47.3 on SWE-Bench Multilingual -- surpassing most open and closed-sourced baselines in non-thinking settings. It also exhibits strong capabilities in coding, mathematics, and reasoning tasks, with a score of 53.7 on LiveCodeBench v6, 49.5 on AIME 2025, 75.1 on GPQA-Diamond, and 27.1 on OJBench, all without extended thinking. These results position Kimi K2 as one of the most capable open-source large language models to date, particularly in software engineering and agentic tasks. We release our base and post-trained model checkpoints to facilitate future research and applications of agentic intelligence.
CombiBench: Benchmarking LLM Capability for Combinatorial Mathematics
May 06, 2025Neurosymbolic approaches integrating large language models with formal reasoning have recently achieved human-level performance on mathematics competition problems in algebra, geometry and number theory. In comparison, combinatorics remains a challenging domain, characterized by a lack of appropriate benchmarks and theorem libraries. To address this gap, we introduce CombiBench, a comprehensive benchmark comprising 100 combinatorial problems, each formalized in Lean~4 and paired with its corresponding informal statement. The problem set covers a wide spectrum of difficulty levels, ranging from middle school to IMO and university level, and span over ten combinatorial topics. CombiBench is suitable for testing IMO solving capabilities since it includes all IMO combinatorial problems since 2000 (except IMO 2004 P3 as its statement contain an images). Furthermore, we provide a comprehensive and standardized evaluation framework, dubbed Fine-Eval (for $\textbf{F}$ill-in-the-blank $\textbf{in}$ L$\textbf{e}$an Evaluation), for formal mathematics. It accommodates not only proof-based problems but also, for the first time, the evaluation of fill-in-the-blank questions. Using Fine-Eval as the evaluation method and Kimina Lean Server as the backend, we benchmark several LLMs on CombiBench and observe that their capabilities for formally solving combinatorial problems remain limited. Among all models tested (none of which has been trained for this particular task), Kimina-Prover attains the best results, solving 7 problems (out of 100) under both ``with solution'' and ``without solution'' scenarios. We open source the benchmark dataset alongside with the code of the proposed evaluation method at https://github.com/MoonshotAI/CombiBench/.
Kimina-Prover Preview: Towards Large Formal Reasoning Models with Reinforcement Learning
Apr 15, 2025We introduce Kimina-Prover Preview, a large language model that pioneers a novel reasoning-driven exploration paradigm for formal theorem proving, as showcased in this preview release. Trained with a large-scale reinforcement learning pipeline from Qwen2.5-72B, Kimina-Prover demonstrates strong performance in Lean 4 proof generation by employing a structured reasoning pattern we term \textit{formal reasoning pattern}. This approach allows the model to emulate human problem-solving strategies in Lean, iteratively generating and refining proof steps. Kimina-Prover sets a new state-of-the-art on the miniF2F benchmark, reaching 80.7% with pass@8192. Beyond improved benchmark performance, our work yields several key insights: (1) Kimina-Prover exhibits high sample efficiency, delivering strong results even with minimal sampling (pass@1) and scaling effectively with computational budget, stemming from its unique reasoning pattern and RL training; (2) we demonstrate clear performance scaling with model size, a trend previously unobserved for neural theorem provers in formal mathematics; (3) the learned reasoning style, distinct from traditional search algorithms, shows potential to bridge the gap between formal verification and informal mathematical intuition. We open source distilled versions with 1.5B and 7B parameters of Kimina-Prover
DT-JRD: Deep Transformer based Just Recognizable Difference Prediction Model for Video Coding for Machines
Nov 14, 2024Just Recognizable Difference (JRD) represents the minimum visual difference that is detectable by machine vision, which can be exploited to promote machine vision oriented visual signal processing. In this paper, we propose a Deep Transformer based JRD (DT-JRD) prediction model for Video Coding for Machines (VCM), where the accurately predicted JRD can be used reduce the coding bit rate while maintaining the accuracy of machine tasks. Firstly, we model the JRD prediction as a multi-class classification and propose a DT-JRD prediction model that integrates an improved embedding, a content and distortion feature extraction, a multi-class classification and a novel learning strategy. Secondly, inspired by the perception property that machine vision exhibits a similar response to distortions near JRD, we propose an asymptotic JRD loss by using Gaussian Distribution-based Soft Labels (GDSL), which significantly extends the number of training labels and relaxes classification boundaries. Finally, we propose a DT-JRD based VCM to reduce the coding bits while maintaining the accuracy of object detection. Extensive experimental results demonstrate that the mean absolute error of the predicted JRD by the DT-JRD is 5.574, outperforming the state-of-the-art JRD prediction model by 13.1%. Coding experiments shows that comparing with the VVC, the DT-JRD based VCM achieves an average of 29.58% bit rate reduction while maintaining the object detection accuracy.
LITE: Modeling Environmental Ecosystems with Multimodal Large Language Models
Apr 01, 2024The modeling of environmental ecosystems plays a pivotal role in the sustainable management of our planet. Accurate prediction of key environmental variables over space and time can aid in informed policy and decision-making, thus improving people's livelihood. Recently, deep learning-based methods have shown promise in modeling the spatial-temporal relationships for predicting environmental variables. However, these approaches often fall short in handling incomplete features and distribution shifts, which are commonly observed in environmental data due to the substantial cost of data collection and malfunctions in measuring instruments. To address these issues, we propose LITE -- a multimodal large language model for environmental ecosystems modeling. Specifically, LITE unifies different environmental variables by transforming them into natural language descriptions and line graph images. Then, LITE utilizes unified encoders to capture spatial-temporal dynamics and correlations in different modalities. During this step, the incomplete features are imputed by a sparse Mixture-of-Experts framework, and the distribution shift is handled by incorporating multi-granularity information from past observations. Finally, guided by domain instructions, a language model is employed to fuse the multimodal representations for the prediction. Our experiments demonstrate that LITE significantly enhances performance in environmental spatial-temporal prediction across different domains compared to the best baseline, with a 41.25% reduction in prediction error. This justifies its effectiveness. Our data and code are available at https://github.com/hrlics/LITE.