 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGREAT: Generalizable Representation Enhancement via Auxiliary Transformations for Zero-Shot Environmental Prediction
Nov 17, 2025Environmental modeling faces critical challenges in predicting ecosystem dynamics across unmonitored regions due to limited and geographically imbalanced observation data. This challenge is compounded by spatial heterogeneity, causing models to learn spurious patterns that fit only local data. Unlike conventional domain generalization, environmental modeling must preserve invariant physical relationships and temporal coherence during augmentation. In this paper, we introduce Generalizable Representation Enhancement via Auxiliary Transformations (GREAT), a framework that effectively augments available datasets to improve predictions in completely unseen regions. GREAT guides the augmentation process to ensure that the original governing processes can be recovered from the augmented data, and the inclusion of the augmented data leads to improved model generalization. Specifically, GREAT learns transformation functions at multiple layers of neural networks to augment both raw environmental features and temporal influence. They are refined through a novel bi-level training process that constrains augmented data to preserve key patterns of the original source data. We demonstrate GREAT's effectiveness on stream temperature prediction across six ecologically diverse watersheds in the eastern U.S., each containing multiple stream segments. Experimental results show that GREAT significantly outperforms existing methods in zero-shot scenarios. This work provides a practical solution for environmental applications where comprehensive monitoring is infeasible.
Detecting Emotional Dynamic Trajectories: An Evaluation Framework for Emotional Support in Language Models
Nov 12, 2025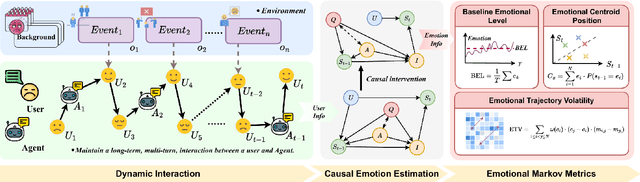
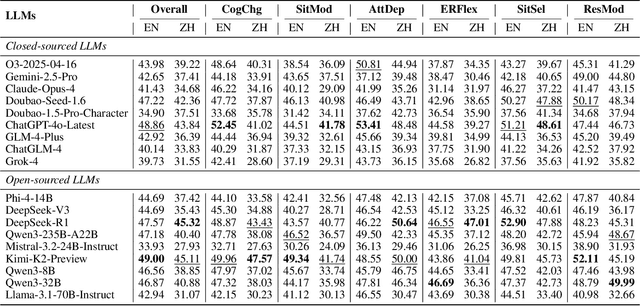
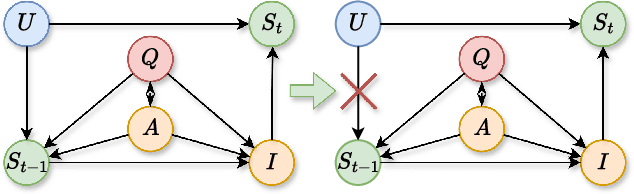
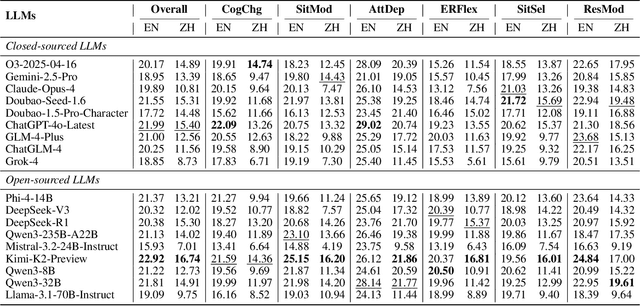
Emotional support is a core capability in human-AI interaction, with applications including psychological counseling, role play, and companionship. However, existing evaluations of large language models (LLMs) often rely on short, static dialogues and fail to capture the dynamic and long-term nature of emotional support. To overcome this limitation, we shift from snapshot-based evaluation to trajectory-based assessment, adopting a user-centered perspective that evaluates models based on their ability to improve and stabilize user emotional states over time. Our framework constructs a large-scale benchmark consisting of 328 emotional contexts and 1,152 disturbance events, simulating realistic emotional shifts under evolving dialogue scenarios. To encourage psychologically grounded responses, we constrain model outputs using validated emotion regulation strategies such as situation selection and cognitive reappraisal. User emotional trajectories are modeled as a first-order Markov process, and we apply causally-adjusted emotion estimation to obtain unbiased emotional state tracking. Based on this framework, we introduce three trajectory-level metrics: Baseline Emotional Level (BEL), Emotional Trajectory Volatility (ETV), and Emotional Centroid Position (ECP). These metrics collectively capture user emotional dynamics over time and support comprehensive evaluation of long-term emotional support performance of LLMs. Extensive evaluations across a diverse set of LLMs reveal significant disparities in emotional support capabilities and provide actionable insights for model development.
Geo-Aware Models for Stream Temperature Prediction across Different Spatial Regions and Scales
Oct 10, 2025Understanding environmental ecosystems is vital for the sustainable management of our planet. However,existing physics-based and data-driven models often fail to generalize to varying spatial regions and scales due to the inherent data heterogeneity presented in real environmental ecosystems. This generalization issue is further exacerbated by the limited observation samples available for model training. To address these issues, we propose Geo-STARS, a geo-aware spatio-temporal modeling framework for predicting stream water temperature across different watersheds and spatial scales. The major innovation of Geo-STARS is the introduction of geo-aware embedding, which leverages geographic information to explicitly capture shared principles and patterns across spatial regions and scales. We further integrate the geo-aware embedding into a gated spatio-temporal graph neural network. This design enables the model to learn complex spatial and temporal patterns guided by geographic and hydrological context, even with sparse or no observational data. We evaluate Geo-STARS's efficacy in predicting stream water temperature, which is a master factor for water quality. Using real-world datasets spanning 37 years across multiple watersheds along the eastern coast of the United States, Geo-STARS demonstrates its superior generalization performance across both regions and scales, outperforming state-of-the-art baselines. These results highlight the promise of Geo-STARS for scalable, data-efficient environmental monitoring and decision-making.
Learning to Retrieve for Environmental Knowledge Discovery: An Augmentation-Adaptive Self-Supervised Learning Framework
Sep 18, 2025The discovery of environmental knowledge depends on labeled task-specific data, but is often constrained by the high cost of data collection. Existing machine learning approaches usually struggle to generalize in data-sparse or atypical conditions. To this end, we propose an Augmentation-Adaptive Self-Supervised Learning (A$^2$SL) framework, which retrieves relevant observational samples to enhance modeling of the target ecosystem. Specifically, we introduce a multi-level pairwise learning loss to train a scenario encoder that captures varying degrees of similarity among scenarios. These learned similarities drive a retrieval mechanism that supplements a target scenario with relevant data from different locations or time periods. Furthermore, to better handle variable scenarios, particularly under atypical or extreme conditions where traditional models struggle, we design an augmentation-adaptive mechanism that selectively enhances these scenarios through targeted data augmentation. Using freshwater ecosystems as a case study, we evaluate A$^2$SL in modeling water temperature and dissolved oxygen dynamics in real-world lakes. Experimental results show that A$^2$SL significantly improves predictive accuracy and enhances robustness in data-scarce and atypical scenarios. Although this study focuses on freshwater ecosystems, the A$^2$SL framework offers a broadly applicable solution in various scientific domains.
Knowledge Guided Encoder-Decoder Framework: Integrating Multiple Physical Models for Agricultural Ecosystem Modeling
May 13, 2025



Agricultural monitoring is critical for ensuring food security, maintaining sustainable farming practices, informing policies on mitigating food shortage, and managing greenhouse gas emissions. Traditional process-based physical models are often designed and implemented for specific situations, and their parameters could also be highly uncertain. In contrast, data-driven models often use black-box structures and does not explicitly model the inter-dependence between different ecological variables. As a result, they require extensive training data and lack generalizability to different tasks with data distribution shifts and inconsistent observed variables. To address the need for more universal models, we propose a knowledge-guided encoder-decoder model, which can predict key crop variables by leveraging knowledge of underlying processes from multiple physical models. The proposed method also integrates a language model to process complex and inconsistent inputs and also utilizes it to implement a model selection mechanism for selectively combining the knowledge from different physical models. Our evaluations on predicting carbon and nitrogen fluxes for multiple sites demonstrate the effectiveness and robustness of the proposed model under various scenarios.
LITE: Modeling Environmental Ecosystems with Multimodal Large Language Models
Apr 01, 2024


The modeling of environmental ecosystems plays a pivotal role in the sustainable management of our planet. Accurate prediction of key environmental variables over space and time can aid in informed policy and decision-making, thus improving people's livelihood. Recently, deep learning-based methods have shown promise in modeling the spatial-temporal relationships for predicting environmental variables. However, these approaches often fall short in handling incomplete features and distribution shifts, which are commonly observed in environmental data due to the substantial cost of data collection and malfunctions in measuring instruments. To address these issues, we propose LITE -- a multimodal large language model for environmental ecosystems modeling. Specifically, LITE unifies different environmental variables by transforming them into natural language descriptions and line graph images. Then, LITE utilizes unified encoders to capture spatial-temporal dynamics and correlations in different modalities. During this step, the incomplete features are imputed by a sparse Mixture-of-Experts framework, and the distribution shift is handled by incorporating multi-granularity information from past observations. Finally, guided by domain instructions, a language model is employed to fuse the multimodal representations for the prediction. Our experiments demonstrate that LITE significantly enhances performance in environmental spatial-temporal prediction across different domains compared to the best baseline, with a 41.25% reduction in prediction error. This justifies its effectiveness. Our data and code are available at https://github.com/hrlics/LITE.
FREE: The Foundational Semantic Recognition for Modeling Environmental Ecosystems
Nov 17, 2023Modeling environmental ecosystems is critical for the sustainability of our planet, but is extremely challenging due to the complex underlying processes driven by interactions amongst a large number of physical variables. As many variables are difficult to measure at large scales, existing works often utilize a combination of observable features and locally available measurements or modeled values as input to build models for a specific study region and time period. This raises a fundamental question in advancing the modeling of environmental ecosystems: how to build a general framework for modeling the complex relationships amongst various environmental data over space and time? In this paper, we introduce a new framework, FREE, which maps available environmental data into a text space and then converts the traditional predictive modeling task in environmental science to the semantic recognition problem. The proposed FREE framework leverages recent advances in Large Language Models (LLMs) to supplement the original input features with natural language descriptions. This facilitates capturing the data semantics and also allows harnessing the irregularities of input features. When used for long-term prediction, FREE has the flexibility to incorporate newly collected observations to enhance future prediction. The efficacy of FREE is evaluated in the context of two societally important real-world applications, predicting stream water temperature in the Delaware River Basin and predicting annual corn yield in Illinois and Iowa. Beyond the superior predictive performance over multiple baseline methods, FREE is shown to be more data- and computation-efficient as it can be pre-trained on simulated data generated by physics-based models.