 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTele-Omni: a Unified Multimodal Framework for Video Generation and Editing
Feb 10, 2026Recent advances in diffusion-based video generation have substantially improved visual fidelity and temporal coherence. However, most existing approaches remain task-specific and rely primarily on textual instructions, limiting their ability to handle multimodal inputs, contextual references, and diverse video generation and editing scenarios within a unified framework. Moreover, many video editing methods depend on carefully engineered pipelines tailored to individual operations, which hinders scalability and composability. In this paper, we propose Tele-Omni, a unified multimodal framework for video generation and editing that follows multimodal instructions, including text, images, and reference videos, within a single model. Tele-Omni leverages pretrained multimodal large language models to parse heterogeneous instructions and infer structured generation or editing intents, while diffusion-based generators perform high-quality video synthesis conditioned on these structured signals. To enable joint training across heterogeneous video tasks, we introduce a task-aware data processing pipeline that unifies multimodal inputs into a structured instruction format while preserving task-specific constraints. Tele-Omni supports a wide range of video-centric tasks, including text-to-video generation, image-to-video generation, first-last-frame video generation, in-context video generation, and in-context video editing. By decoupling instruction parsing from video synthesis and combining it with task-aware data design, Tele-Omni achieves flexible multimodal control while maintaining strong temporal coherence and visual consistency. Experimental results demonstrate that Tele-Omni achieves competitive performance across multiple tasks.
TempoMaster: Efficient Long Video Generation via Next-Frame-Rate Prediction
Nov 16, 2025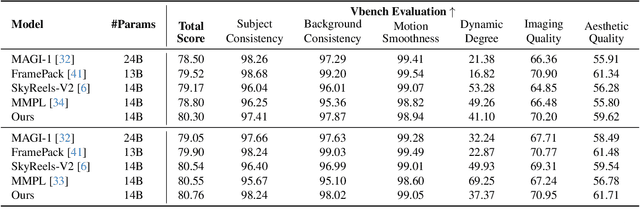
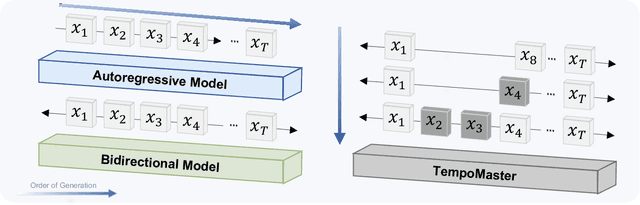
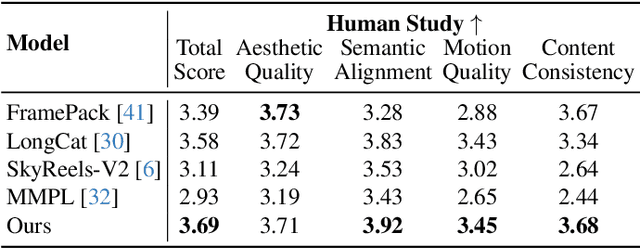
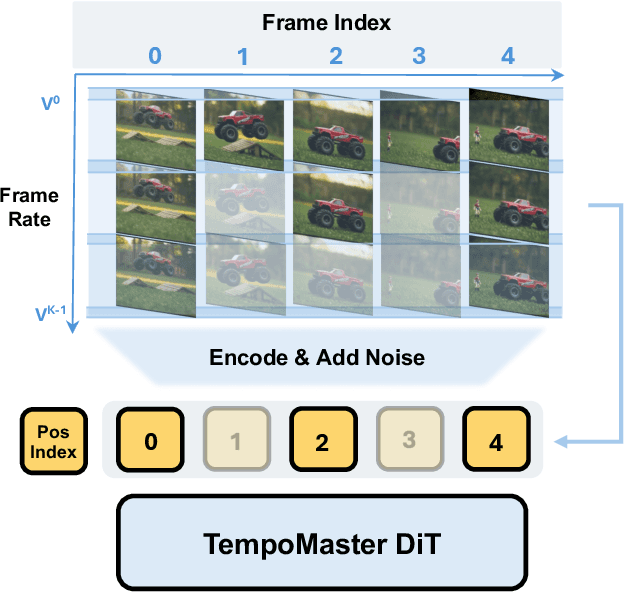
We present TempoMaster, a novel framework that formulates long video generation as next-frame-rate prediction. Specifically, we first generate a low-frame-rate clip that serves as a coarse blueprint of the entire video sequence, and then progressively increase the frame rate to refine visual details and motion continuity. During generation, TempoMaster employs bidirectional attention within each frame-rate level while performing autoregression across frame rates, thus achieving long-range temporal coherence while enabling efficient and parallel synthesis. Extensive experiments demonstrate that TempoMaster establishes a new state-of-the-art in long video generation, excelling in both visual and temporal quality.
NFIG: Autoregressive Image Generation with Next-Frequency Prediction
Mar 10, 2025



Autoregressive models have achieved promising results in natural language processing. However, for image generation tasks, they encounter substantial challenges in effectively capturing long-range dependencies, managing computational costs, and most crucially, defining meaningful autoregressive sequences that reflect natural image hierarchies. To address these issues, we present \textbf{N}ext-\textbf{F}requency \textbf{I}mage \textbf{G}eneration (\textbf{NFIG}), a novel framework that decomposes the image generation process into multiple frequency-guided stages. Our approach first generates low-frequency components to establish global structure with fewer tokens, then progressively adds higher-frequency details, following the natural spectral hierarchy of images. This principled autoregressive sequence not only improves the quality of generated images by better capturing true causal relationships between image components, but also significantly reduces computational overhead during inference. Extensive experiments demonstrate that NFIG achieves state-of-the-art performance with fewer steps, offering a more efficient solution for image generation, with 1.25$\times$ speedup compared to VAR-d20 while achieving better performance (FID: 2.81) on the ImageNet-256 benchmark. We hope that our insight of incorporating frequency-domain knowledge to guide autoregressive sequence design will shed light on future research. We will make our code publicly available upon acceptance of the paper.