 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKimina-Prover Preview: Towards Large Formal Reasoning Models with Reinforcement Learning
Apr 15, 2025We introduce Kimina-Prover Preview, a large language model that pioneers a novel reasoning-driven exploration paradigm for formal theorem proving, as showcased in this preview release. Trained with a large-scale reinforcement learning pipeline from Qwen2.5-72B, Kimina-Prover demonstrates strong performance in Lean 4 proof generation by employing a structured reasoning pattern we term \textit{formal reasoning pattern}. This approach allows the model to emulate human problem-solving strategies in Lean, iteratively generating and refining proof steps. Kimina-Prover sets a new state-of-the-art on the miniF2F benchmark, reaching 80.7% with pass@8192. Beyond improved benchmark performance, our work yields several key insights: (1) Kimina-Prover exhibits high sample efficiency, delivering strong results even with minimal sampling (pass@1) and scaling effectively with computational budget, stemming from its unique reasoning pattern and RL training; (2) we demonstrate clear performance scaling with model size, a trend previously unobserved for neural theorem provers in formal mathematics; (3) the learned reasoning style, distinct from traditional search algorithms, shows potential to bridge the gap between formal verification and informal mathematical intuition. We open source distilled versions with 1.5B and 7B parameters of Kimina-Prover
Learning the effect of latent variables in Gaussian Graphical models with unobserved variables
Jul 31, 2018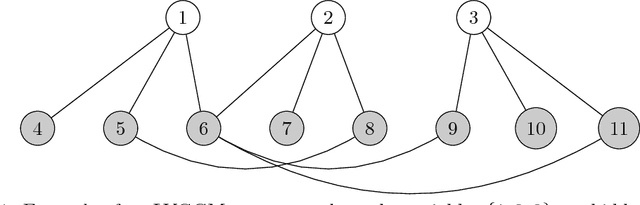
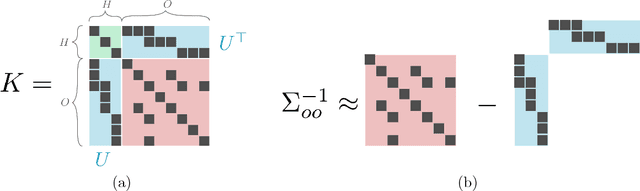
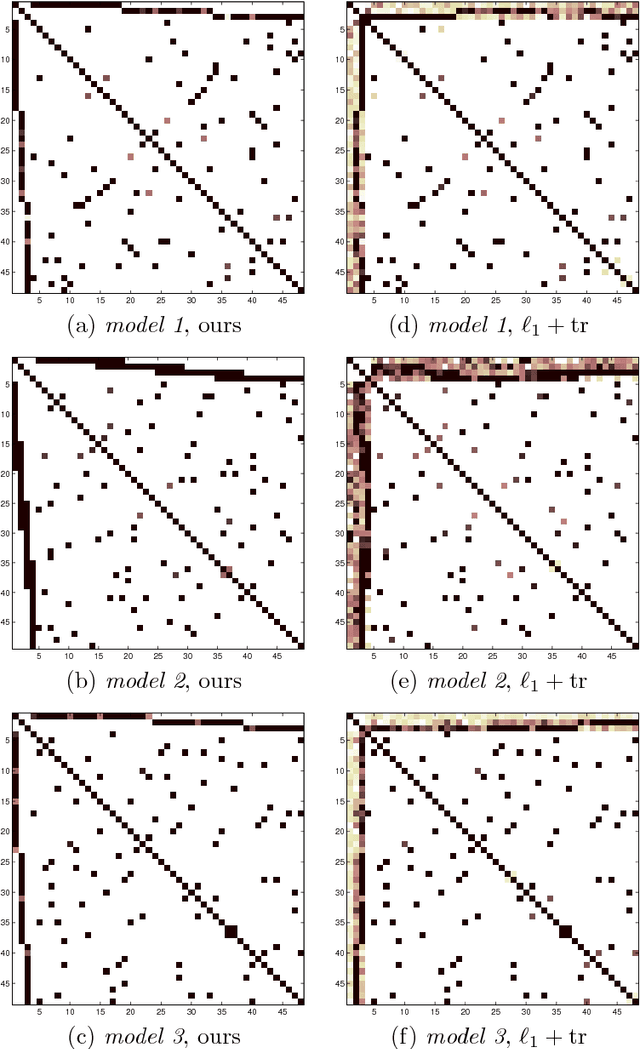
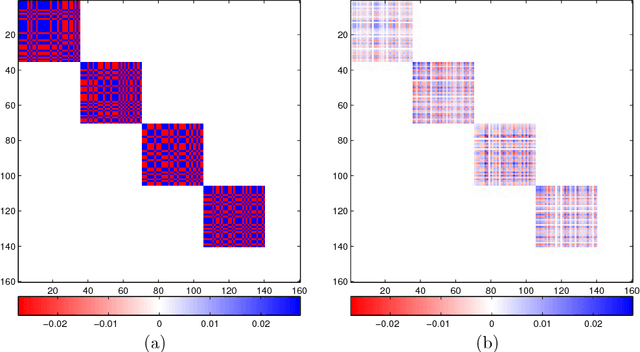
The edge structure of the graph defining an undirected graphical model describes precisely the structure of dependence between the variables in the graph. In many applications, the dependence structure is unknown and it is desirable to learn it from data, often because it is a preliminary step to be able to ascertain causal effects. This problem, known as structure learning, is hard in general, but for Gaussian graphical models it is slightly easier because the structure of the graph is given by the sparsity pattern of the precision matrix of the joint distribution, and because independence coincides with decorrelation. A major difficulty too often ignored in structure learning is the fact that if some variables are not observed, the marginal dependence graph over the observed variables will possibly be significantly more complex and no longer reflect the direct dependencies that are potentially associated with causal effects. In this work, we consider a family of latent variable Gaussian graphical models in which the graph of the joint distribution between observed and unobserved variables is sparse, and the unobserved variables are conditionally independent given the others. Prior work was able to recover the connectivity between observed variables, but could only identify the subspace spanned by unobserved variables, whereas we propose a convex optimization formulation based on structured matrix sparsity to estimate the complete connectivity of the complete graph including unobserved variables, given the knowledge of the number of missing variables, and a priori knowledge of their level of connectivity. Our formulation is supported by a theoretical result of identifiability of the latent dependence structure for sparse graphs in the infinite data limit. We propose an algorithm leveraging recent active set methods, which performs well in the experiments on synthetic data.