 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEqualization Loss for Long-Tailed Object Recognition
Apr 14, 2020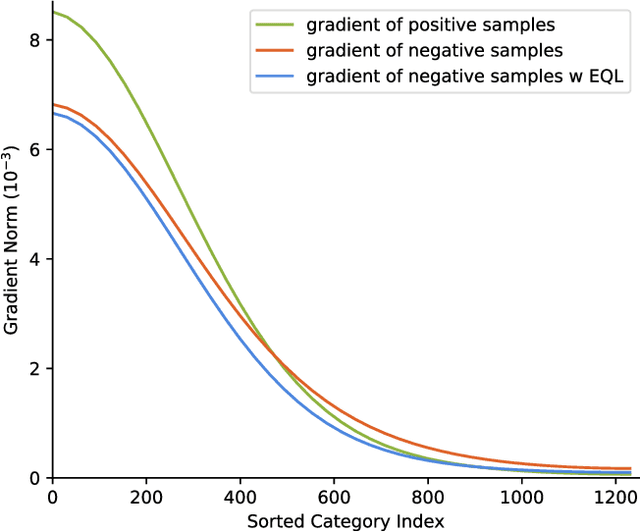
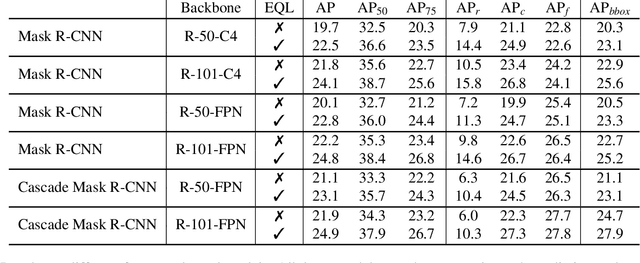
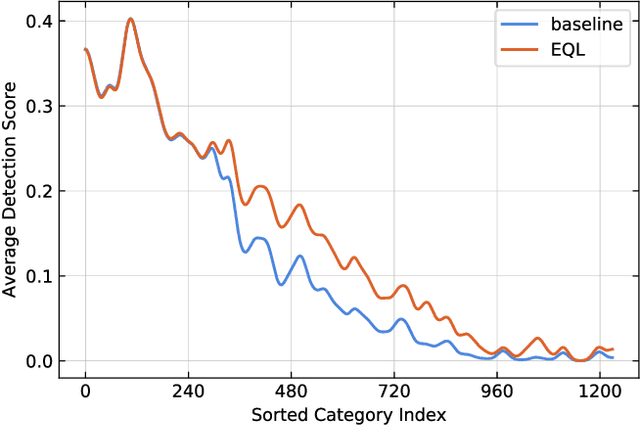
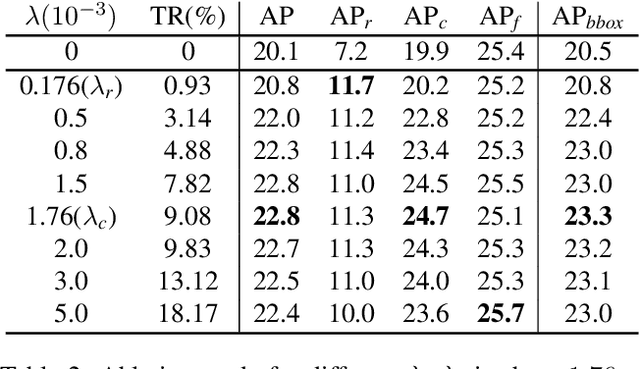
Object recognition techniques using convolutional neural networks (CNN) have achieved great success. However, state-of-the-art object detection methods still perform poorly on large vocabulary and long-tailed datasets, e.g. LVIS. In this work, we analyze this problem from a novel perspective: each positive sample of one category can be seen as a negative sample for other categories, making the tail categories receive more discouraging gradients. Based on it, we propose a simple but effective loss, named equalization loss, to tackle the problem of long-tailed rare categories by simply ignoring those gradients for rare categories. The equalization loss protects the learning of rare categories from being at a disadvantage during the network parameter updating. Thus the model is capable of learning better discriminative features for objects of rare classes. Without any bells and whistles, our method achieves AP gains of 4.1% and 4.8% for the rare and common categories on the challenging LVIS benchmark, compared to the Mask R-CNN baseline. With the utilization of the effective equalization loss, we finally won the 1st place in the LVIS Challenge 2019. Code has been made available at: https: //github.com/tztztztztz/eql.detectron2
1st Place Solutions for OpenImage2019 -- Object Detection and Instance Segmentation
Mar 17, 2020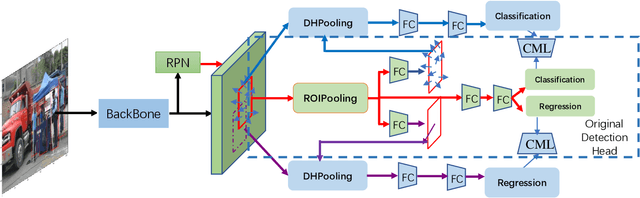


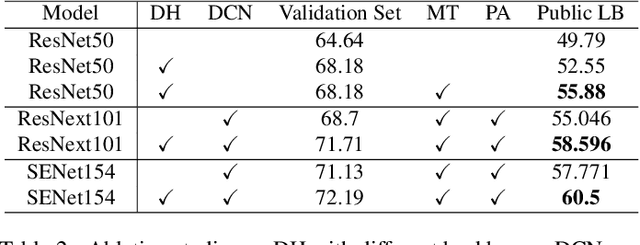
This article introduces the solutions of the two champion teams, `MMfruit' for the detection track and `MMfruitSeg' for the segmentation track, in OpenImage Challenge 2019. It is commonly known that for an object detector, the shared feature at the end of the backbone is not appropriate for both classification and regression, which greatly limits the performance of both single stage detector and Faster RCNN \cite{ren2015faster} based detector. In this competition, we observe that even with a shared feature, different locations in one object has completely inconsistent performances for the two tasks. \textit{E.g. the features of salient locations are usually good for classification, while those around the object edge are good for regression.} Inspired by this, we propose the Decoupling Head (DH) to disentangle the object classification and regression via the self-learned optimal feature extraction, which leads to a great improvement. Furthermore, we adjust the soft-NMS algorithm to adj-NMS to obtain stable performance improvement. Finally, a well-designed ensemble strategy via voting the bounding box location and confidence is proposed. We will also introduce several training/inferencing strategies and a bag of tricks that give minor improvement. Given those masses of details, we train and aggregate 28 global models with various backbones, heads and 3+2 expert models, and achieves the 1st place on the OpenImage 2019 Object Detection Challenge on the both public and private leadboards. Given such good instance bounding box, we further design a simple instance-level semantic segmentation pipeline and achieve the 1st place on the segmentation challenge.
Top-1 Solution of Multi-Moments in Time Challenge 2019
Mar 13, 2020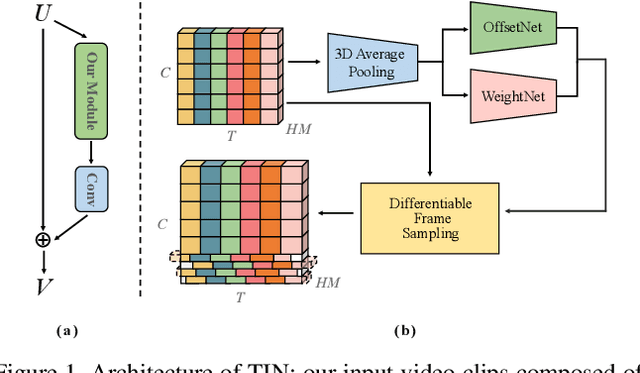
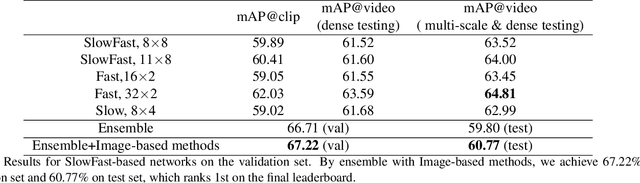
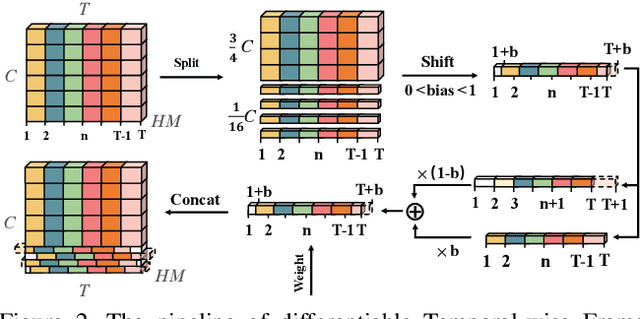
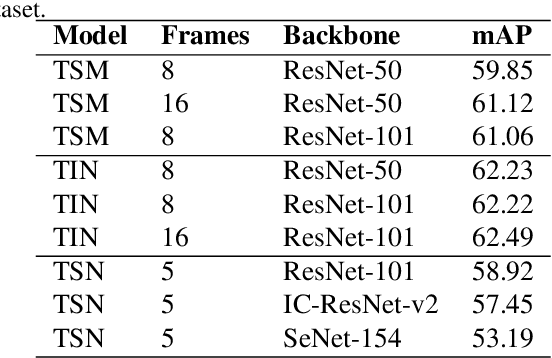
In this technical report, we briefly introduce the solutions of our team 'Efficient' for the Multi-Moments in Time challenge in ICCV 2019. We first conduct several experiments with popular Image-Based action recognition methods TRN, TSN, and TSM. Then a novel temporal interlacing network is proposed towards fast and accurate recognition. Besides, the SlowFast network and its variants are explored. Finally, we ensemble all the above models and achieve 67.22\% on the validation set and 60.77\% on the test set, which ranks 1st on the final leaderboard. In addition, we release a new code repository for video understanding which unifies state-of-the-art 2D and 3D methods based on PyTorch. The solution of the challenge is also included in the repository, which is available at https://github.com/Sense-X/X-Temporal.
Towards Stabilizing Batch Statistics in Backward Propagation of Batch Normalization
Jan 19, 2020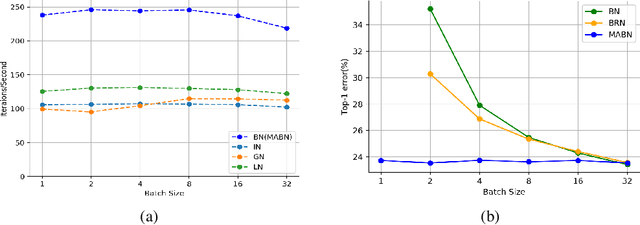
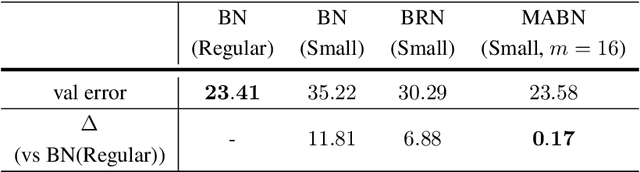
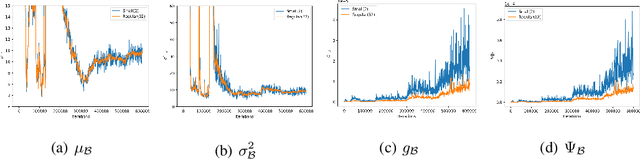
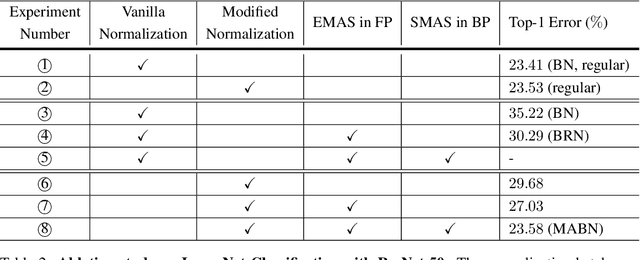
Batch Normalization (BN) is one of the most widely used techniques in Deep Learning field. But its performance can awfully degrade with insufficient batch size. This weakness limits the usage of BN on many computer vision tasks like detection or segmentation, where batch size is usually small due to the constraint of memory consumption. Therefore many modified normalization techniques have been proposed, which either fail to restore the performance of BN completely, or have to introduce additional nonlinear operations in inference procedure and increase huge consumption. In this paper, we reveal that there are two extra batch statistics involved in backward propagation of BN, on which has never been well discussed before. The extra batch statistics associated with gradients also can severely affect the training of deep neural network. Based on our analysis, we propose a novel normalization method, named Moving Average Batch Normalization (MABN). MABN can completely restore the performance of vanilla BN in small batch cases, without introducing any additional nonlinear operations in inference procedure. We prove the benefits of MABN by both theoretical analysis and experiments. Our experiments demonstrate the effectiveness of MABN in multiple computer vision tasks including ImageNet and COCO. The code has been released in https://github.com/megvii-model/MABN.
Cross-dataset Training for Class Increasing Object Detection
Jan 14, 2020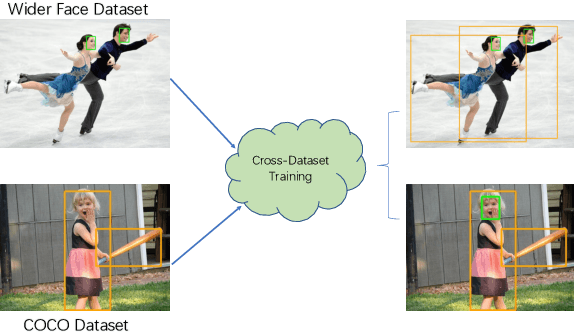
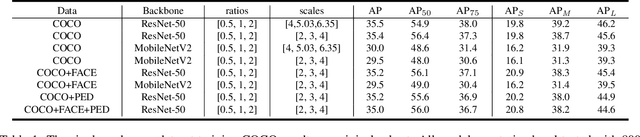
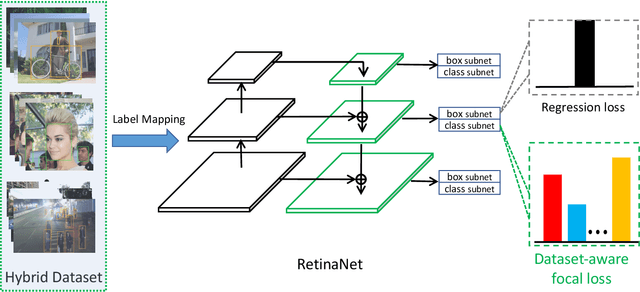

We present a conceptually simple, flexible and general framework for cross-dataset training in object detection. Given two or more already labeled datasets that target for different object classes, cross-dataset training aims to detect the union of the different classes, so that we do not have to label all the classes for all the datasets. By cross-dataset training, existing datasets can be utilized to detect the merged object classes with a single model. Further more, in industrial applications, the object classes usually increase on demand. So when adding new classes, it is quite time-consuming if we label the new classes on all the existing datasets. While using cross-dataset training, we only need to label the new classes on the new dataset. We experiment on PASCAL VOC, COCO, WIDER FACE and WIDER Pedestrian with both solo and cross-dataset settings. Results show that our cross-dataset pipeline can achieve similar impressive performance simultaneously on these datasets compared with training independently.
Towards Unified INT8 Training for Convolutional Neural Network
Dec 29, 2019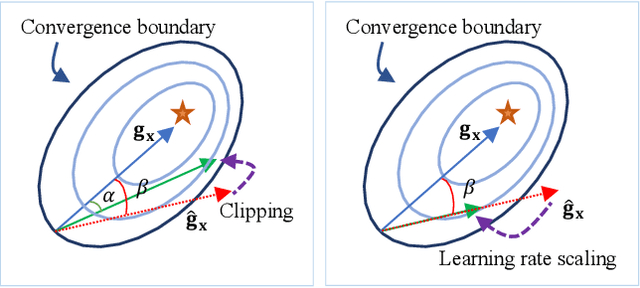
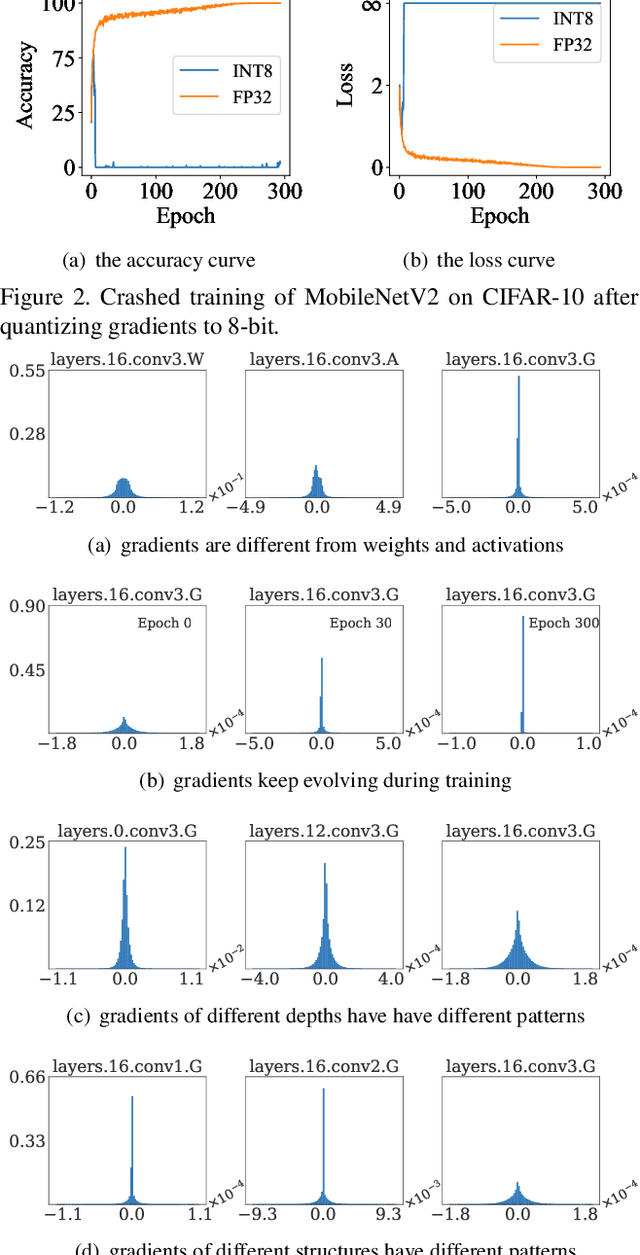

Recently low-bit (e.g., 8-bit) network quantization has been extensively studied to accelerate the inference. Besides inference, low-bit training with quantized gradients can further bring more considerable acceleration, since the backward process is often computation-intensive. Unfortunately, the inappropriate quantization of backward propagation usually makes the training unstable and even crash. There lacks a successful unified low-bit training framework that can support diverse networks on various tasks. In this paper, we give an attempt to build a unified 8-bit (INT8) training framework for common convolutional neural networks from the aspects of both accuracy and speed. First, we empirically find the four distinctive characteristics of gradients, which provide us insightful clues for gradient quantization. Then, we theoretically give an in-depth analysis of the convergence bound and derive two principles for stable INT8 training. Finally, we propose two universal techniques, including Direction Sensitive Gradient Clipping that reduces the direction deviation of gradients and Deviation Counteractive Learning Rate Scaling that avoids illegal gradient update along the wrong direction. The experiments show that our unified solution promises accurate and efficient INT8 training for a variety of networks and tasks, including MobileNetV2, InceptionV3 and object detection that prior studies have never succeeded. Moreover, it enjoys a strong flexibility to run on off-the-shelf hardware, and reduces the training time by 22% on Pascal GPU without too much optimization effort. We believe that this pioneering study will help lead the community towards a fully unified INT8 training for convolutional neural networks.
Computation Reallocation for Object Detection
Dec 24, 2019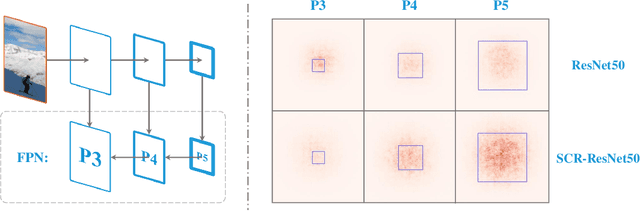
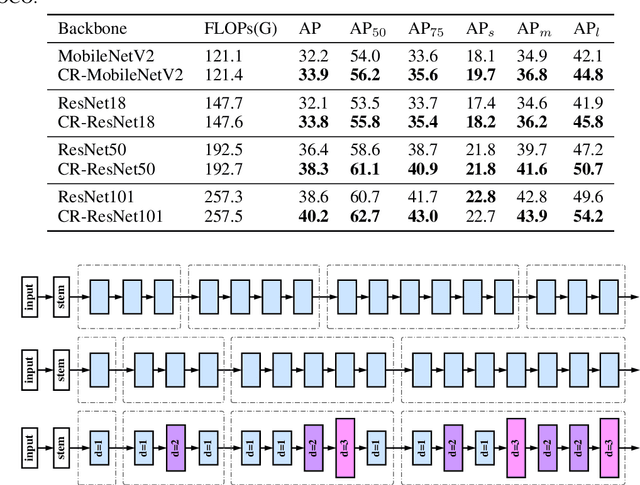
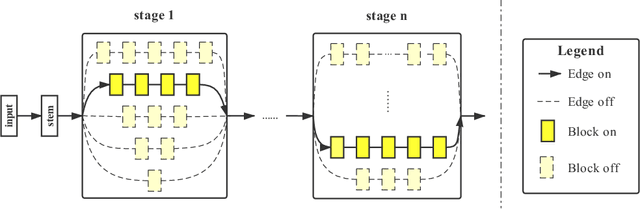

The allocation of computation resources in the backbone is a crucial issue in object detection. However, classification allocation pattern is usually adopted directly to object detector, which is proved to be sub-optimal. In order to reallocate the engaged computation resources in a more efficient way, we present CR-NAS (Computation Reallocation Neural Architecture Search) that can learn computation reallocation strategies across different feature resolution and spatial position diectly on the target detection dataset. A two-level reallocation space is proposed for both stage and spatial reallocation. A novel hierarchical search procedure is adopted to cope with the complex search space. We apply CR-NAS to multiple backbones and achieve consistent improvements. Our CR-ResNet50 and CR-MobileNetV2 outperforms the baseline by 1.9% and 1.7% COCO AP respectively without any additional computation budget. The models discovered by CR-NAS can be equiped to other powerful detection neck/head and be easily transferred to other dataset, e.g. PASCAL VOC, and other vision tasks, e.g. instance segmentation. Our CR-NAS can be used as a plugin to improve the performance of various networks, which is demanding.
Equalization Loss for Large Vocabulary Instance Segmentation
Nov 12, 2019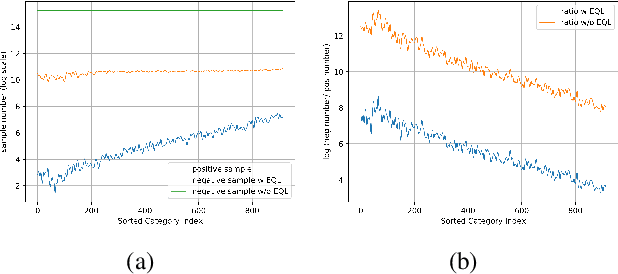
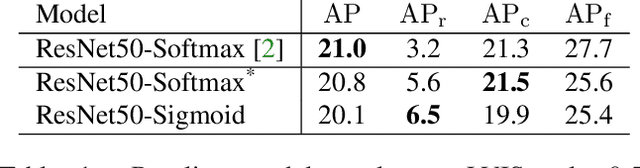


Recent object detection and instance segmentation tasks mainly focus on datasets with a relatively small set of categories, e.g. Pascal VOC with 20 classes and COCO with 80 classes. The new large vocabulary dataset LVIS brings new challenges to conventional methods. In this work, we propose an equalization loss to solve the long tail of rare categories problem. Combined with exploiting the data from detection datasets to alleviate the effect of missing-annotation problems during the training, our method achieves 5.1\% overall AP gain and 11.4\% AP gain of rare categories on LVIS benchmark without any bells and whistles compared to Mask R-CNN baseline. Finally we achieve 28.9 mask AP on the test-set of the LVIS and rank 1st place in LVIS Challenge 2019.
Improving One-shot NAS by Suppressing the Posterior Fading
Oct 06, 2019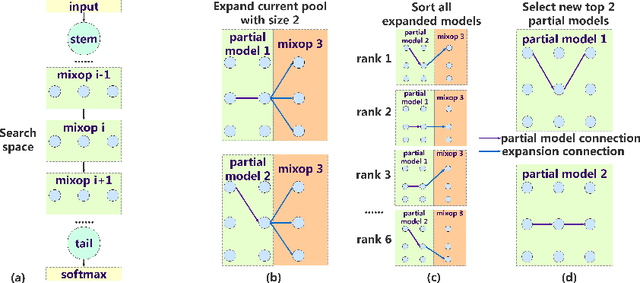
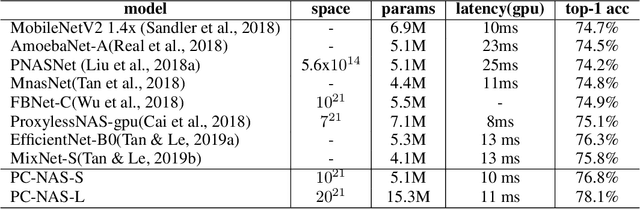

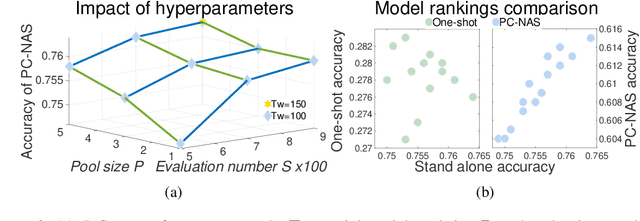
There is a growing interest in automated neural architecture search (NAS). To improve the efficiency of NAS, previous approaches adopt weight sharing method to force all models share the same set of weights. However, it has been observed that a model performing better with shared weights does not necessarily perform better when trained alone. In this paper, we analyse existing weight sharing one-shot NAS approaches from a Bayesian point of view and identify the posterior fading problem, which compromises the effectiveness of shared weights. To alleviate this problem, we present a practical approach to guide the parameter posterior towards its true distribution. Moreover, a hard latency constraint is introduced during the search so that the desired latency can be achieved. The resulted method, namely Posterior Convergent NAS (PC-NAS), achieves state-of-the-art performance under standard GPU latency constraint on ImageNet. In our small search space, our model PC-NAS-S attains 76.8 % top-1 accuracy, 2.1% higher than MobileNetV2 (1.4x) with the same latency. When adopted to the large search space, PC-NAS-L achieves 78.1 % top-1 accuracy within 11ms. The discovered architecture also transfers well to other computer vision applications such as object detection and person re-identification.
CAMP: Cross-Modal Adaptive Message Passing for Text-Image Retrieval
Sep 12, 2019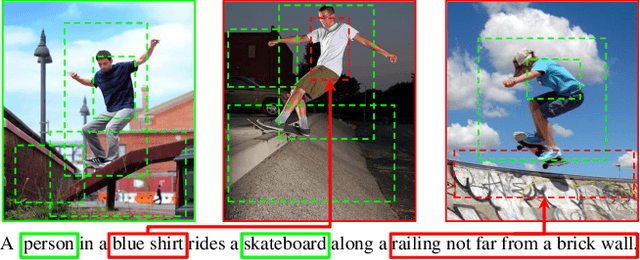
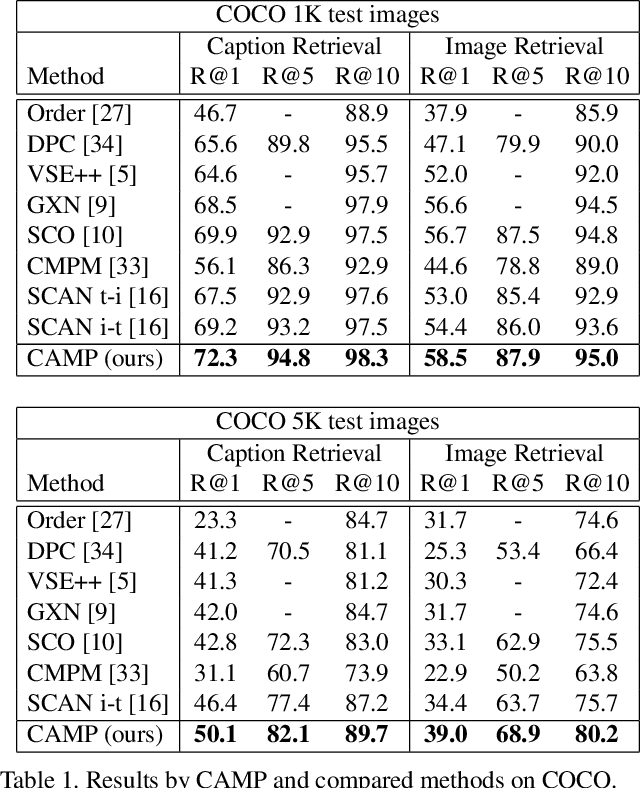
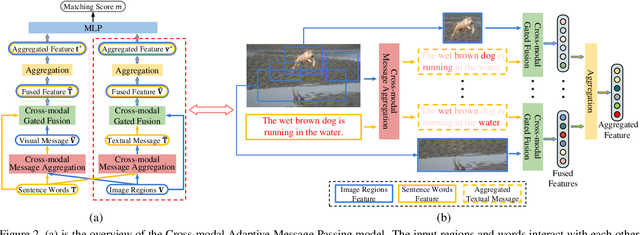
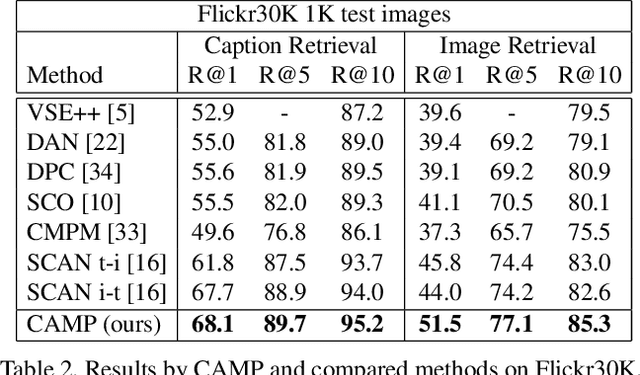
Text-image cross-modal retrieval is a challenging task in the field of language and vision. Most previous approaches independently embed images and sentences into a joint embedding space and compare their similarities. However, previous approaches rarely explore the interactions between images and sentences before calculating similarities in the joint space. Intuitively, when matching between images and sentences, human beings would alternatively attend to regions in images and words in sentences, and select the most salient information considering the interaction between both modalities. In this paper, we propose Cross-modal Adaptive Message Passing (CAMP), which adaptively controls the information flow for message passing across modalities. Our approach not only takes comprehensive and fine-grained cross-modal interactions into account, but also properly handles negative pairs and irrelevant information with an adaptive gating scheme. Moreover, instead of conventional joint embedding approaches for text-image matching, we infer the matching score based on the fused features, and propose a hardest negative binary cross-entropy loss for training. Results on COCO and Flickr30k significantly surpass state-of-the-art methods, demonstrating the effectiveness of our approach.